오랜만에 돌아온 논문 리뷰.
오타와 대학과 함께 진행하는 논문 세미나에서 발표할 PPT의 Figure로 넣을 예정인데 혹시 몰라서 읽어볼 예정이다.
발표할 논문은 아래의 What do self-supervised Vision Transformer learn? 이라는 논문인데, 나도 나중에 이런 논문을 쓰고싶다고 느끼게 해준 논문이다. 가볍게 정리 후, 아직 업데이트를 안했는데, 조만간 조금 더 구체적으로 포스팅을 해야겠다.
논문 읽기 - What Do Self-Supervised Vision Transformers Learn?
저자: Namuk park 소속: Prescient Design Genentech, NAVER AI Lab 날짜: 2023.05.01 Arxiv 등재 학회: ICLR 2023 Problem - Contrastive Learning (CL) 그리고 Masked Image Modeling (MIM)의 representation이 어떻게 다른지, 각각의 방법이
187cm.tistory.com
저자: Y Tian
소속: MIT CSAIL & Google Research
학회: ECCV 2020
인용: 1830 (2023.07.16 기준)
링크: https://arxiv.org/abs/1906.05849
Abstract
- 사람은 많은 감각 채널을 통해 세상을 본다. 시각을 통한 장파장, 청각을 통한 고주파 채널 등, 여러 감각 채널이 존재한다.
- 각각의 채널은 noisy하고 incomplete하지만, 물리학, 기하학, 의미론에서 각 채널들이 공유되는 중요한 정보들이 있다.
- models view-invariant factors*가 powerful reprsentation일 것이란 Classic한 가설 → Multiview Contrastive Learning 제안
models view-invariant factors : 여러가지 MultiView에서 공유되는 중요한 정보.
Multiview Contrastive Learning : 같은 장면에서의 다른 view간의 mutual information을 최대화 하는 방식으로 representation learning 방법
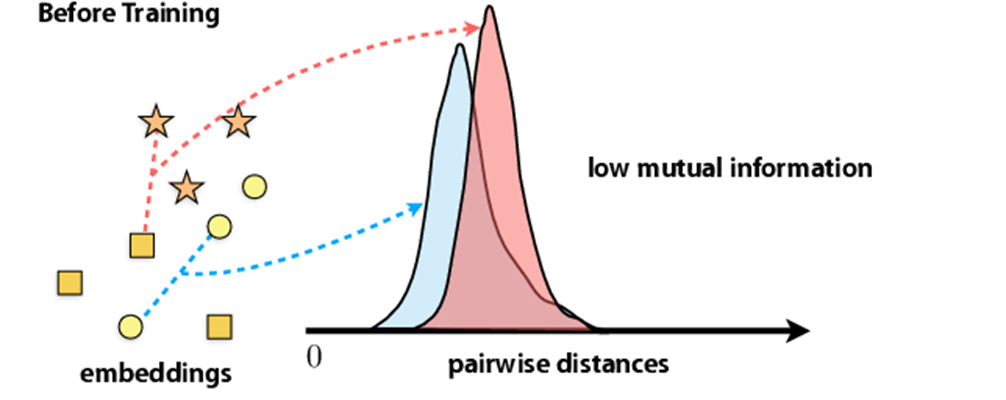
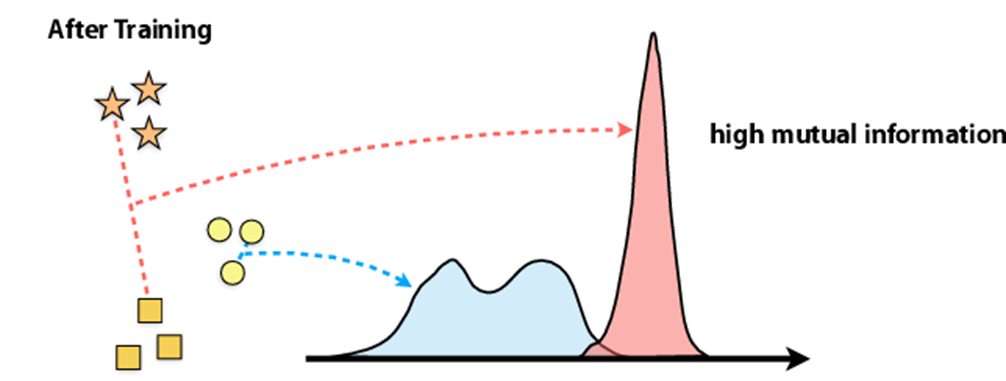
- 이런 방식을 통해 여러 view들의 근본적인 scene semantics를 학습하여 기존의 cross view prediction방식을 능가하는 SOTA를 달성하였다.
Introduction
- coding theory의 idea는 압축된 표현을 학습해서 raw data를 재건축. 주로 AutoEncode나, VAE, GAN에서 나타났다.
- data point나 distribution을 가능한 lossless하게 표현하려고 노력했지만, 애초에 raw data가 lossless하기도 하고, lossless하게 만드는 것이 애초에 우리가 원하는 것이 아니였다.
ex) Noise가 많은 Raw data의 경우 Raw data로 똑같이 복원해도 우리가 원하는 것이 아니다. 즉 전처리를 통해 유의미한 정보를 얻어가길 원하며, 이는 Downstream task에서 좋은 성능으로 나타나기를 바란다.
- 그래서 적절한 "good" information이 뭐가 될까?, 그리고 어떻게 good information과 noise를 식별할까?
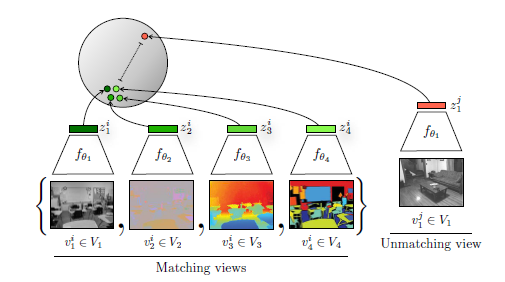
- Abstract에서의 Classic한 가설로 돌아와서 개의 존재라는 정보는 good information이다 듣고, 보고 느낄 수 있기 떄문이다. 하지만, Camera pose는 bad information이다. 왜냐하면 camera pose는 하나의 정보만 보여주기 때문이다.
- 그래서 논문에서는 이러한 점을 해결하고자 luminance, chrominance, depth, optical flow의 4가지 view를 이용한다.
- 의도적으로 어려운 4개의 이미지를 사용 (논문에서는 good bit를 날린다고 표현) 하여 모델이 경험적으로 좋은 bit를 알아서 학습하게 만든다. 이 모델이 downstream에서 잘 동작한다면 좋은 성능을 낼 것. (조금 무책임한 말 같기도하다)
- 이 논문의 목표는 위의 이미지와 같이, 같은 이미지에 대해서는 High mutual information을 가지도록, 다른 이미지에 대해서는 compact한 mutual information을 가지게 만드는 것이 목표이다.
- 방법론으로 같은 scence에 대해서는 가깝게 mapping하는, 반대는 멀게하는 Contrastive Learning을 사용하였다.
- 추가적으로 최근에 제시된 Contrastive Predictive Coding 방법론 또한 적용하였다. 아래에서 한번 읽는 것을 추천한다.
++근데 일반화를 위해 RNN을 제거하고, 시간적 공간적 정보에만 적용하는 것이 아닌, 이미지 채널에 대해서 적용하는 법도 보여줄 예정이다
논문 요약 [CPC] - Representation Learning with Contrastive predictive Coding
제목 : Representation Learning with Contrastive predictive Coding 학회 : NIPS 2019 Aaron van den Oord Invited talk [영상 링크] (따로 출판 된지는 몰루? 블로그 글보다 영상이 훨씬 설명을 잘한다. 글 말고 영상는 것을
187cm.tistory.com
- 연산 수식은 Instance Discrimination과 논리적으로 동일하다. Instance Discrimination을 자세하게 안읽어서 수식을 밑에서 다루겠다.
Realted Work.
- 생략. 위의 CPC를 읽어보는 것을 추천.
Method
Definition.

- M: Views of data. 위의 이미지에서 1,2에 해당. 위의 Figure 1에서는 4개의 view를 사용했으므로 M=4
- V1, V2, ... V_M : V는 scene이다.
- vi는 각각의 view "V_i"의 random variable이다. 즉 v_i ~ P(V_i)
Predictive Learning
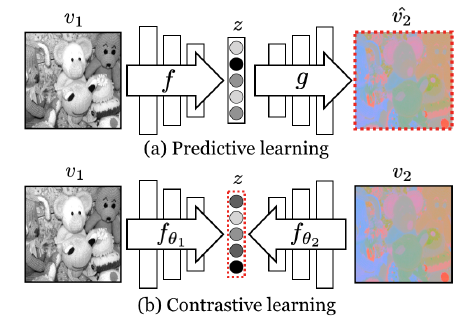
- 기존의 Contrastive Learning은 view 1과 view 2가 있을 때, 두개의 이미지가 입력이 되어 latent space z에 mapping을 한다는 점이 특징이지만, Predictive Learning은 v1은 z를 만들고 z는 v2를 만드는 encoder&decoder 형식이다.
Contrastive Learning with Two views.
- Dataset V1과 V2가 주어졌을 때, x ~ p(v1, v2) or x = {v1i, v2i}는 Positive Pair, y ~ p(v1)p(v2) or y = {v1i, v2j}는 Negative
- 하나의 Positive sample x와 나머지 k개의 Negative sample을 가지는 set S = {x, y1, y2, ..., yk}의 Loss는 아래와 같다.
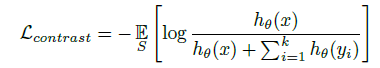

- 이 때, 여기서 주목할 점은 hθ(⋅)인데, 이 discriminating function은 critic이라 불리며 Positive value의 값은 높게, Negative sample의 값은 낮게 만드는 역할의 fuction이다.
- 이 수식 1에 x,y에 위에서 정의한 v1, v2를 넣으면 수식 2가 된다.
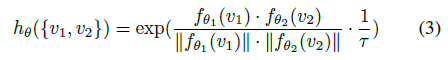

- 그리고 이 수식 (3)은 discriminating fuction hθ(⋅)를 정의한 수식이다. Cosine similarity와 유사하게 f1과 f2를 사용하였다.
- temperature paramter τ는 0.07으로 위의 그림을 참고하면 t는 sharpening효과를 준다는 점을 알 수 있다.
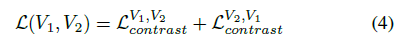
- 기존 Loss 수식 (2) 의 경우 f1가 Anchor 역할을, f2가 들어오는 역할이 되기 때문에, 반대로도 수행한다. 수식 (4)
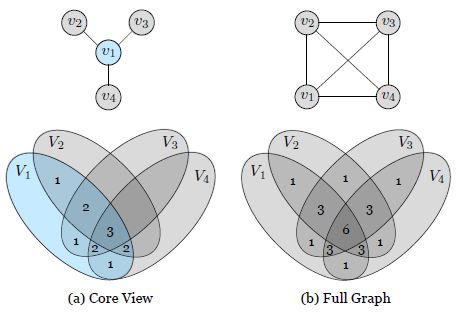
- 위의 loss function을 여러개의 view에 대해 수행할 때, 위의 숫자는 weight를 얼마나 줘야하는지에 대한 수치를 나타낸다.
Experiments




