제목 : Representation Learning with Contrastive predictive Coding
학회 : NIPS 2019 Aaron van den Oord Invited talk [영상 링크]
(따로 출판 된지는 몰루? 블로그 글보다 영상이 훨씬 설명을 잘한다. 글 말고 영상는 것을 추천)
저자 : Aaron van den Oord | Yazhe Li | Oriol vinyals
소속: Deep Mind
인용 : 5322 (2023.06.26 기준)
링크 : https://arxiv.org/abs/1807.03748
Background. [이미지 출처 NIPS 2019 Invited talk]
1. mutual information → 우리가 데이터 셋을 가지고 있고 아래 그림과 같이 x,y는 같은 label이다. 이 때 우리가 X를 봤을 때 Y가 뭐가 될 것인가 에 대한 내용이다.
mutual information은 두 이미지의 연관성을 확률로 나타낸 것으로, 위에서 우리는 같은 label이라고 이미 가정하였기에 위와 같이 수정 가능.
2. Mutual information을 통해 generative task를 수행할 때의 수식 log P(y|x)
3. 우리가 256*256 짜리 JPEG 이미지가 있다고 할 때, 이 이미지의 bit는 1.5M 정도 될 것. 즉 1.5M의 정보를 가진다.
4. 그리고 우리의 log likelihood의 결과는 다음과 같이 50만 bit가 될 것. (가정) 즉 우리가 50만 bit의 정보를 가지고 있다면 lossless하게 원본 이미지 X를 복구할 수 있다. (lossless: 손실 없이 원본으로 되돌리는 것)
5. 1과 같이 4개의 class가 존재하고 이들이 각각 균일한 확률로 발생한다면 우리는 2개의 비트를 뺀 만큼의 log likelihood를 가지고 X를 복원할 수 있다. 우리의 log likelihood를 쉽게 줄여주긴하지만 이는 너무 비효율적인 방법이다.

6. 그래서 우리가 사용해야 하는 것은 Contrastive Loss. label 정보를 활용한 X와 Y사이의 mutual information 적용.
7. 같은 클래스를 Positive, 다른 Class를 negative로 묶어서 학습을 한다.
8. 이 때의 lower bound는 negative sample의 loss를 뺀 값이 된다는 것을 알 수 있다.
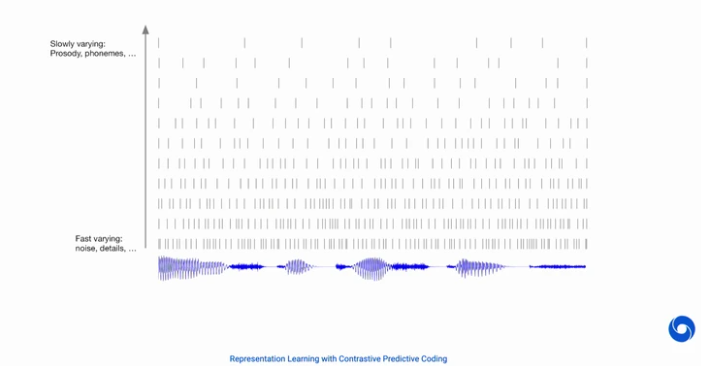
9. 그렇다면 우리가 아래와 같은 신호 데이터가 있다고 할 때, 미래에 오는 신호를 어떻게 예측할까?
10. 다음과 같이 바로 뒤에오는 fast-variable은 모두나 쉽게 예측할 수 있다.
11. 하지만 우리가 하고싶은건 slow-variable을 찾는 것이다. 다음 대화의 주제, 억양 등 천천히 변화하는 것에 대한 정보이다. 이러한 부분을 예측하는 것은 Entropy가 매우 높기 때문에 예측하기가 어렵다. 하지만 slow-variable은 매우 매우 천천히 변하기 때문에 이러한 정보를 찾는 것이 우리의 목표가 될 것이다.
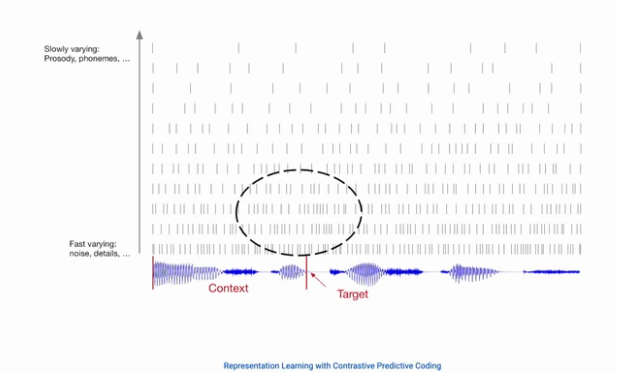
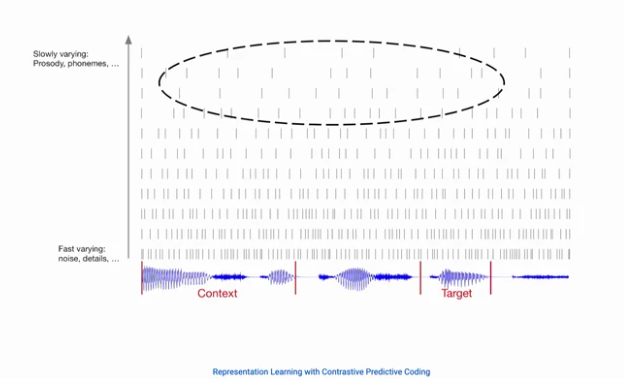
- 아래의 그림과 같이, noise와 같은 fast variable은 쉽게 사라지지만, 대화의 흐름과 같은 slow variable은 쉽게 변하지 않음

Summarize
- 그래서 제안하는 DeepMind의 모델은 아래와 같다.

1. high-dimensional data를 압축 후, latent space에 embedding시킨다.
2. powerful autoregressive model의 latent space가 많은 단계의 미래를 예측하는데 사용.
3. NLP에서 word embedding 학습에 사용된 것 처럼 Noise-Contrastive Estimation을 loss function에 사용.
Abstract
- high-dimensional data에서 유용한 representation을 뽑아내는 Universial unsupervised learning approach CPC* 제안.
CPC* - Contrastive Predictive Coding.
- powerful한 autoregressive model을 사용해 latent space에서 미래를 예측해서 representation학습.
- latent space의 정보를 효과적으로 capture가능한 probabilistic contrastive loss 사용 → 미래 sample을 효과적으로 예측
Introduction
- representation learning을 Improving시키기 위해선 single supervised task에 맞춰진 feature가 아닌, less specialized된 feature를 요구한다. 하나의 task에 대해 최고의 성능이 아닌 여러 가지 분야에서의 좋은 성능을 내는 feature를 뽑자!
ex) inducded feature*가 image classfication에 전이가 잘 된다면, color 혹은 image captioning task에서 부족하더라도 잘 되는 feature일 것.
++ inducded feature : pre-train을 통해 얻어진 feature.
→ 즉 이러한 induced feature를 가지는 unsupervised learning은 robust하고 generic한 representation learning의 디딤돌이 될 것이다.
- 하지만 이런 중요성을 알아도 supervised learning만큼 성능을 내는 것이 불가능. (2019년은 unsupervised learning이 채택 되지 못함) why? raw 신호에서 high-level representation을 뽑아내는 것은 파악하기 어려우며, 뭐가 좋은 표현인지, 아닌지가 명확하지 않기 때문이다.
- 2019년까지 흔한 Unsupervised learning은 미래 예측, missing or contextural information. Image domain은 이미지 참조
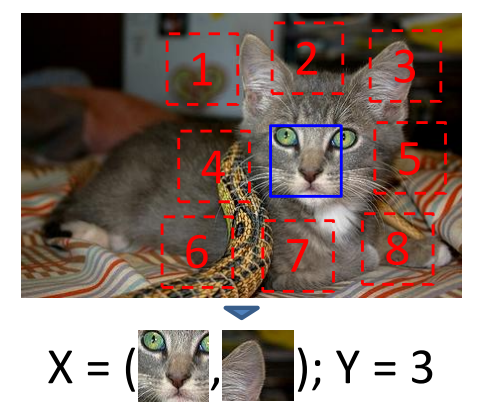

- 위의 Image domain에서 Y와 같은 값을 뽑아내는 과정에서, high-level latent representation을 가지는 latent space가 conditionally dependent 하게 이 정보를 뽑아내기 때문에 풍부한 정보를 가지고 있다고 가정하고 이러한 방법을 사용.
Contrastive predicting Coding
Motivation and Intuitions
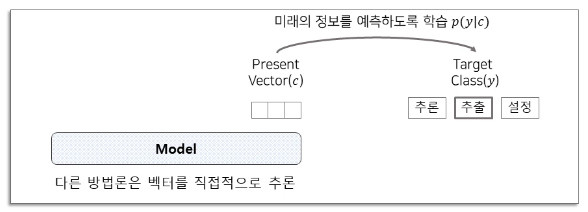
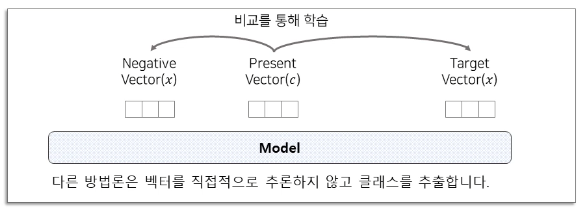
- representation 학습을 위해 여러 부분의 high-dimensional한 signal의 정보가 공유되어 encoding 되었다는 것.
++ lowe-level information, local noise와 같은 정보를 무시 가능하다.
- 하지만 high-dimensional data를 압축 한 후, 미래를 예측하는 과정에서 하나의 vector만 가지고 예측을 하는 것은 shared 정보가 추출하는 최적의 방법이 아니다. 하나의 vector를 골라 MSE or Cross Entropy와 같은 loss사용은 옳지 않다.
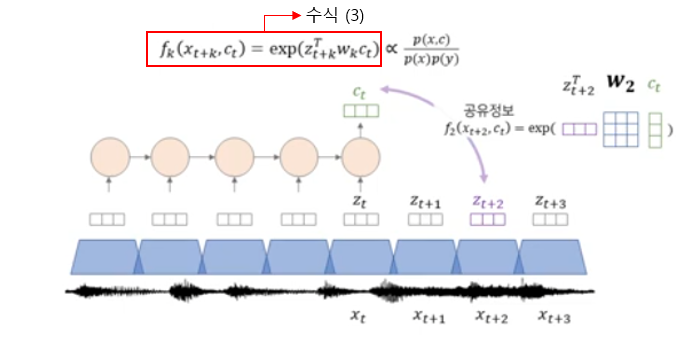
→ shared information을 적절하게 사용하는 새로운 loss function이 필요하다. (우측그림)
Contrastive predictive coding
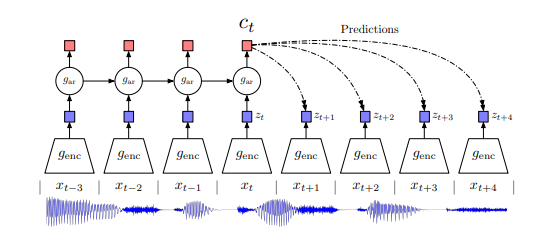
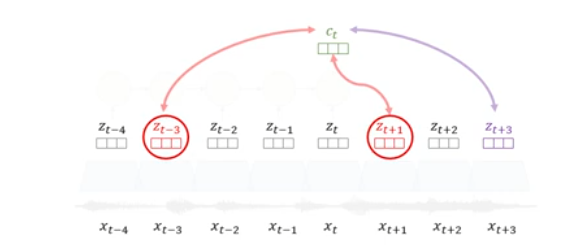
- non-linear (ResNet) encoder genc는 xt를 압축해서 zt를 만든다.
- autoregressive model gar (RNN)는 z1부터 zt의 정보를 종합해서 ct를 만든다.
- future predict t+k시점의 예측은 p(t+k|ct)로 예측한다.
- 위에서 Background로 설명한 그림을 바탕으로 Mutual information을 개념을 이해하고, 이를 수식으로 나타내면
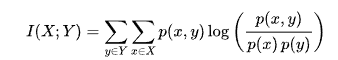
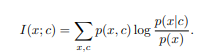
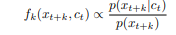
- 위의 왼쪽과 같은 수식에서 p(x,y)는 Bayesian rule에 의해 p(y)⋅p(x|y) 이므로, 우측 상단과 같은 수식 (1)이 전개 가능하다.
- 이를 바탕으로 우리의 density ratio f는 수식 (2)와 같이 정의되는데, 이를 수식 (3)과 함께 그림으로 나타내면 아래와 같다.
- 즉 shared information에 대한 density ratio는 아래와 같이 거리에 따라 다르게 반영이 되며, 이 Weight matrix W는 RNN 즉 g_ar 이라고 보면 된다.
이미지 출처: https://www.youtube.com/watch?v=X4fwPhGaR8Q

InfoNCE Loss
- Positive sample은 p(x_t+k|ct)
- Negative sample은 Positive sample 빼고 전부 다.
- 아래와 같은 예시에서 random Negative sampling을 적용한다면 우리의 InfoNCE Loss는 아래와 같다.
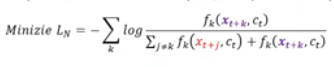
참고: Original InfoNCE Loss.
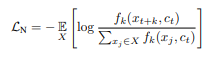
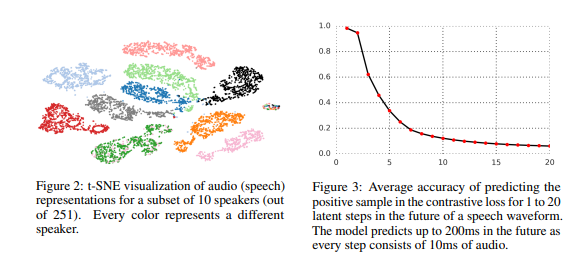
Result
Visual CPC
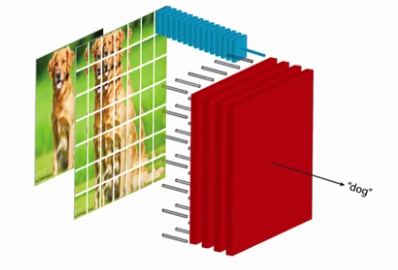
- 왼쪽의 이미지와 같이 빨간색 부분을 바탕으로 파란색 부분을 예측할 것이다.

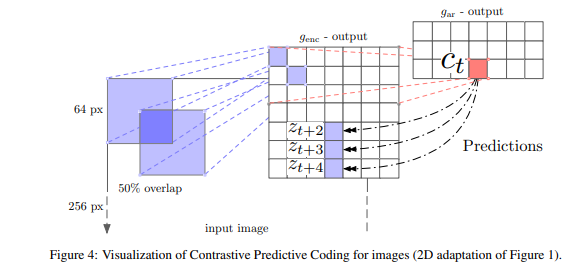
1. feature encode
2. context Networks
3. Predict values



4. 마지막 부분을 CPC가 아닌 pixel에 대해서 예측하는 방식으로 바꿨을 때, 우리의 Top 5% Accuracy는 다음과 같다.
5. 굉장히 적은 label만 가지고 기존의 방식보다 성공적인 성능을 내는 모습을 보여주었다.