저자: Ting Chen | Simon Kornblith | Mohammad Norouzi | Geoffrey Hinton
소속: Google Research Team
학회: PMLR 2020
인용: 10639 (2023.06.25 기준)
논문: https://arxiv.org/abs/2002.05709
1992년 Contrastive learning? self-supervised learning의 대한 개념을 처음으로 제안하신 LeCun교수님과 더불어, 현재 Contrastive Learning / Self-supervised Learning의 핵심 논문 중 하나로 자리잡은 이 SimCLR의 교신저자가 Geoffrey Hinton 교수님이다. Facebook에서 MoCo가 2019년에 등장 후, 2020년 Google에서 SimCLR을 출시했다. 후에 Moco v2 → SimCLRv2 → Mocov3 까지 이어지며 Contrastive Learning의 관심을 늘리지 않았나 싶다. 아래는 앞서서 보고오면 좋은 Moco와 Contrastive Learning의 시초라 불리는 LeCun 교수님의 논문이다.
논문으로 알아보는 Contrastive Learning (1) - DrLIM (Dimensionality Reduction by Learning an Invariant Mapping)
MoCo Review를 하기 전, MoCo에서 많이 언급되며, Contrastive Loss를 처음으로 사용한 논문으로 소개되는 Hadsell - Dimensionality Reduction by Learning an Invariant Mapping (DrLIM) in 2006 CVPR 논문에 대해서 먼저 정리하고
187cm.tistory.com
Contrastive Learning (2) MoCo (Momentum Constrastive for Unsupervised Visual Representation Learning)
Contrastive learning의 대표적인 논문 중 하나인 MoCo에 대해서 소개하도록 하겠습니다. FaceBook, 현재 Meta인 Facebook AI research에서 Kaimming He께서 작성한 논문입니다. (ResNet 만드신 분) MoCo에 대한 개념 설
187cm.tistory.com
Abstract
- 논문 제목에서도 보이다싶이 simple contrastive learning framework를 제안한다.
- MoCo와 같이 특별한 구조, Memory Bank와 같은 구조를 필요로 하지 않는다. (Figure 2) 하지만 높은 배치사이즈 필요...
- 기존의 방법보다 7%나 높은 정확도를 보였다. (Supervised learning과 유사한 성능을 보임) (Figure 1)


Contribution
1. Data Augemtation의 구성 방법이 중요하다. (τ와 τ'를 구성하는 방법)
2. Representation과 Contrastive Loss사이의 non-linear layer를 추가하는 것이 representation을 학습하는 데 더 좋다.
+ 기존의 MoCo방식과 다르게 non-linear layer g()가 추가되었다. (nn.Linear + nn.ReLU)
3. 큰 batch size가 성능을 높이는데 더 좋았다.
Summarize
SimCLR의 과정을 요약하면 다음과 같다. 아래의 이미지 출처 [공식 Github문서 참조]


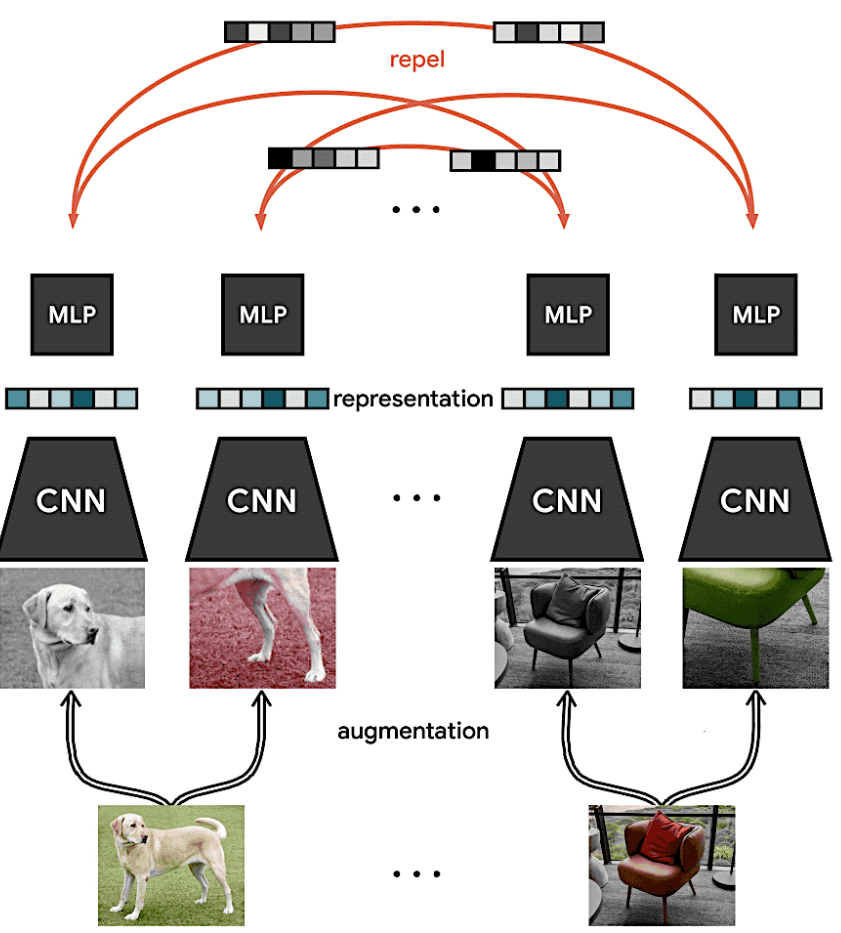
1. 이미지에 대해 두 개의 Stochastic data Augmentation을 적용한다. 1. Crop + Color + blur / 2. Crop
2. Encoder 통과
3. MLP Layer 통과
4. Contrastive Loss 계산, Positive = 녹색, Negative = 빨간색
Introduction.
- visual representation을 학습하는 방법은 크게 2가지로 나뉜다. Generative or Discriminative
Generative: DeepBeliefNet, VAE, GAN과 같이 생성하는법을 학습
→ Pixel 단위 생성은 연산이 많이들고 Representation Learning에서 불필요하다.
Discriminative: Objective function을 사용하여 representation 학습. supervised learning과 비슷하게 전개된다.
→ pretext task*수행 과정에서 unlabeld dataset 필요로 하며, pretext task를 발견 가능하게 디자인 하는 것에 의존.
pretext task: 어떤 문제를 해결하도록 훈련된 네트워크가 다른 downstream task에 쉽게 적용할 수 있는 어떤 시각적 특징을 배우는 단계.
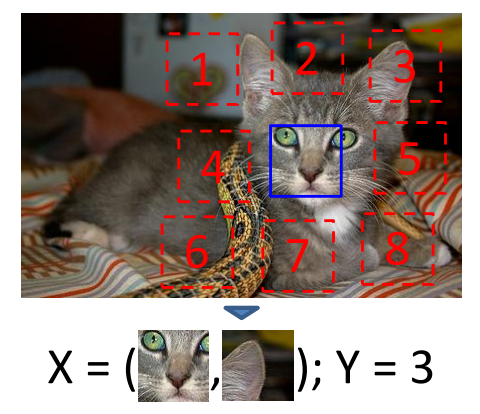


Unsupervised Visual Representation Learning by Context Prediction [CVPR 2015] : Context prediction 작업을 통해 pretext task 학습
Colorful Image Colorization [ECCV 2016] : 흑백 이미지를 Color로 변환.
Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles [ECCV 2016] : 좌측하단과 같이 Jigsaw 퍼즐 해결
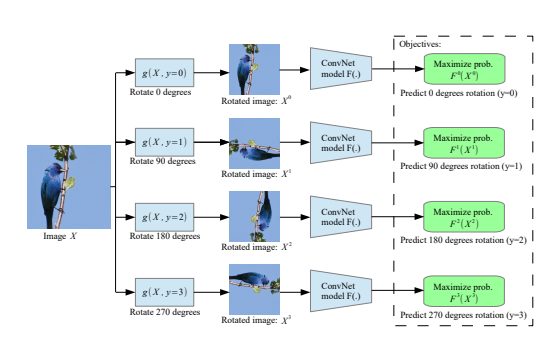
UNSUPERVISED REPRESENTATION LEARNING BY PREDICTING IMAGE ROTATIONS [ICLR 2018] : 이미지 Rotation하여 입력으로.
하지만 위와 같은 pretext task 방식은 Representation을 학습하는데 한계가 존재하였다. (일반화 실패)
- DrLIM, Exemplar-CNN, CPC, AmDIM 과 같은 논문은 Latent space에서 Contrastive Learning을 사용하여 SOTA를 달성하여 가망을 보임.
- 관심이 있다면 위의 논문들을 한번씩 읽어보는 것이 더 도움이 될 것이다.
SimCLR
- AmDIM, Data-Efficient Image Recognition with Contrastive Predictive Coding과 같이 특별한 모델 구조가 필요 없다.
- MoCo와 같이 memory bank 방식 또한 필요없다.
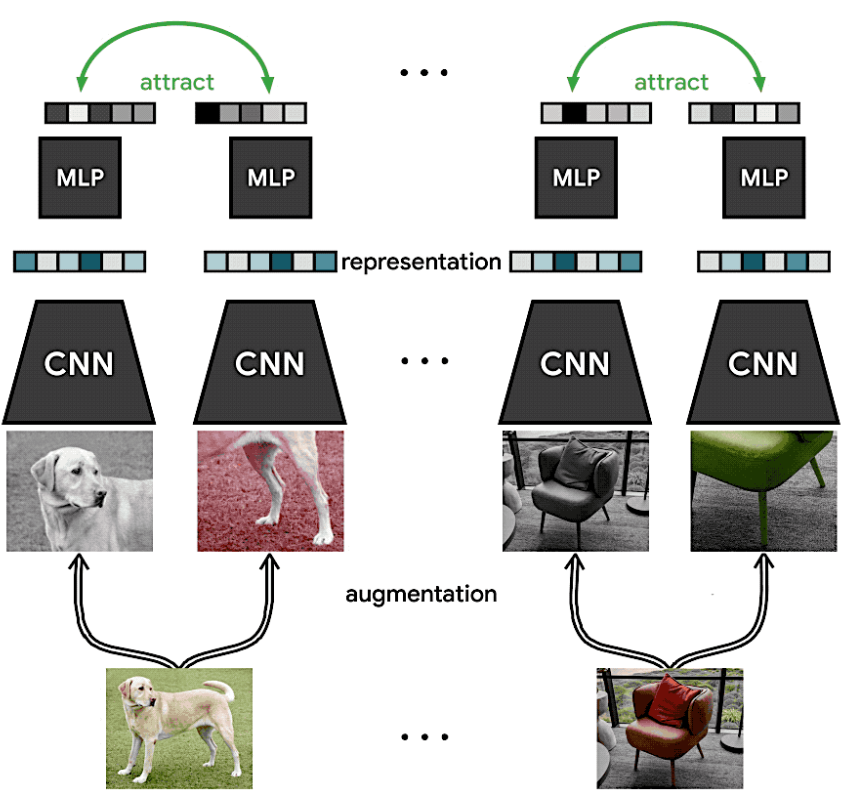
- 앞서 소개한 Data Augmentation, MLP(nn.Linear + nn.ReLU) layer 추가, Figure1과 같이 zi, zj 사이에서 Contrastive Loss를 구하고, Downstream Task에서는 MLP layer를 사용 안하는 X. 큰 배치 사이즈 사용. 이 4가지가 핵심.

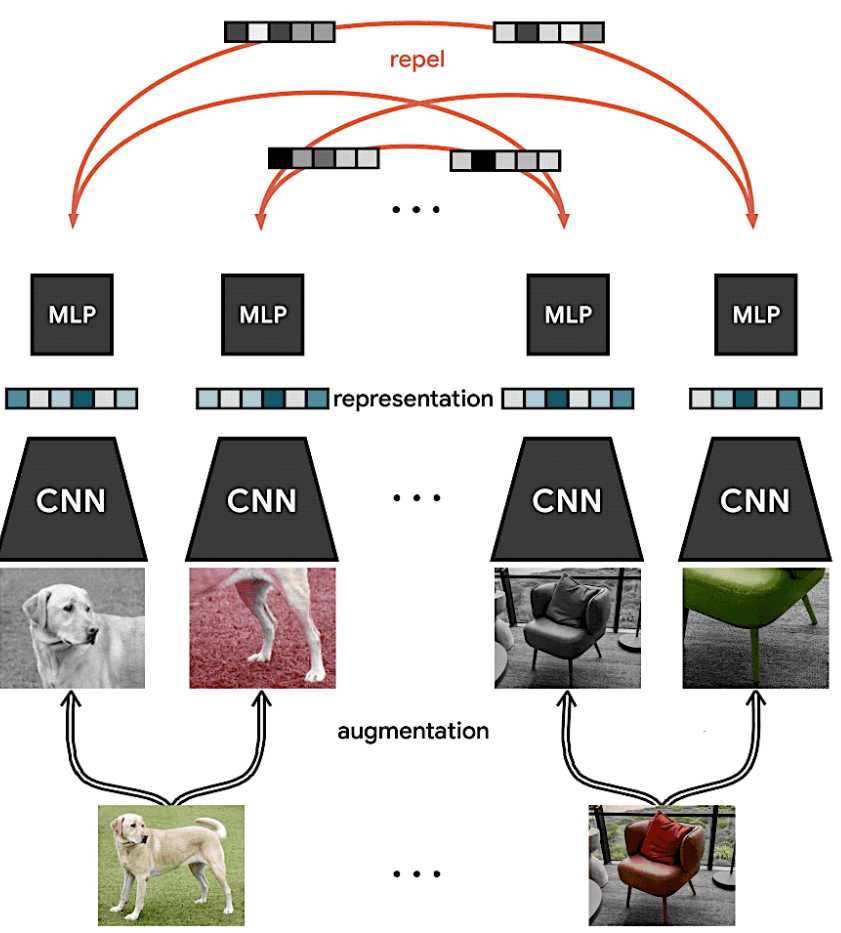
A stochastic data augmentation module.
- 위와 같이 하나의 이미지에 대해 xi, xj 즉 다른 Augmentation을 적용한 이미지 2개를 만든다. (Positive pair)
- Random Cropping, Random color distortions, Random Gaussian Blur 이렇게 3가지 Random Augmentation 적용.
++ Random Gaussian Blur는 Color distortion과 함께 쓰였다고 생각하면 될 것 같다.

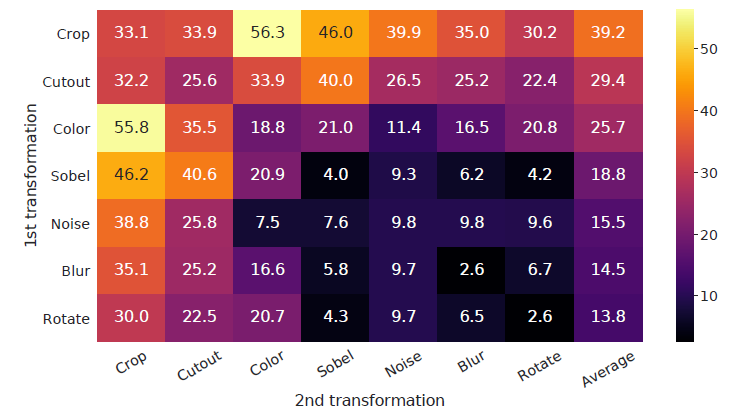
- 왼쪽과 같은 여러가지 방식의 Augmentation을 순서대로 적용해보았다. 성능은 1st - Crop, 2nd - Color Augmentation이 가장 성능이 좋았다.
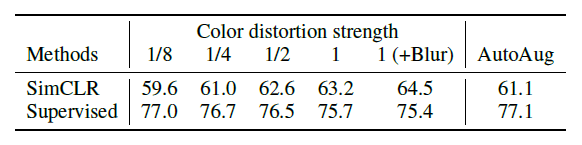
- 또한 아래 그림을 보면 알 수 있는데, Color distortion strenth를 1로 주고 Blur를 주었을 때, SimCLR의 성능이 상승.
Base Encoder f(⋅)
- base encoder f()는 ResNet으로, Representation을 Random augmentation module에서 뽑아낸다.
- hi = f(xi) = ResNet(xi) 으로, hi ∈ℝ^d 이다. 즉 hi는 Average Pooling layer이다.
Small Projection Head g(⋅)
- representation을 Contrastive Loss를 사용하여 공간에다가 mapping해주는 non-linear layer이다.
- 따라서 아래 수식과 같으며, σ = ReLU()이다. z에다가 Contrastive Loss를 계산하는 것이 h에 계산하는 것보다 좋다.
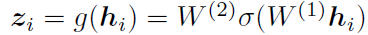
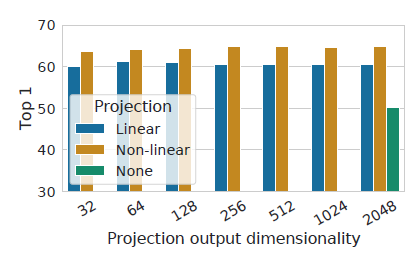
- Projection output의 크기와 Projection layer를 하지 않았을 때의 성능 차이. 안했을 때 크게 성능이 떨어지는 모습을 보이며, 비선형 layer인 ReLU까지 추가를 할 때, 더 좋은 모습을 보였다.
Contrastive Loss function.
- minibatch를 N이라고 할 때, Random Augmentation Module에 의해 2N개의 데이터 포인트가 생기는데, Positive sample은 자기 자신 1개, 자기 자신을 제외한 Negative sample은 2(N-1)이 된다.
- Loss function은 다음과 같이 구성된다. Positive sample / Negative Sample이므로, 우측 하단의 -log() 함수를 바탕으로 Positive sample의 대한 Similarity 값은 크게, Negative sample에 대한 Similarity 값은 작게 만든다.
- 아래 sim 함수는 L2 norm 값이다.
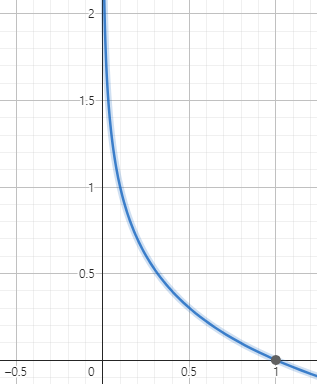
- τ 함수는 Temperature scaling 값으로 Gumble softmax [2017 ICLR Google] 에서 나온 아이디어 이다. 아래와 같은 Loss function에서 τ를 통해 scaling을 하였을 때, softmax의 값이 어떻게 변하는지에 대한 내용으로, τ가 작아질수록 sharpening, τ가 커질수록 smoothing효과가 있다는 내용이다.
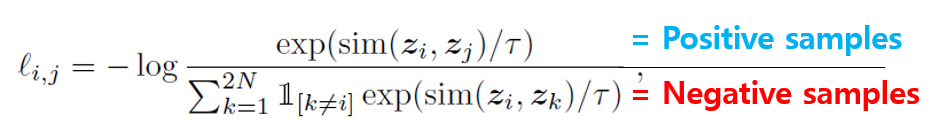

Algorithm

- 상단의 알고리즘은 위에서 설명한 내용을 코드로 나타낸 것이다. first augmentation에서는 Color + (Blur) + Resize,
Second Augmentation에서는 Resize Crop만 사용하였다.
- Memory Bank 방식 대신 256 부터 8192까지 Batchsize를 실험해보았고 4196 Batchsize 사용하였다.
- SGD는 불안정하기에 LARS Optimizer를 사용하였다.
- Global BatchNormalization 사용 → 학습하는 과정에서 Multi GPU를 사용할 때, 각각의 Device가 Similarity를 구하는
과정에서 Positive sample이 하나의 GPU에서만 계산이 되기 때문에 local information leakage가 일어나는 문제 발생.



