Self supervised Learning을 시도할 때, 크게 2가지 방법이 있다. Contrastive Learning(CL)과 Masked Image Modeling이다. 하지만 최근에 MIM이 주목을 받으면서, 많은 사람들이 MIM을 사용하지만 왜 사용하는지, 언제 사용해야하는지에 대한 내용은 모를 것이다. 이 논문은 이러한 점을 ViT를 사용하여 분석하는 논문이다. 이 논문에서는 최근 주목받는 MIM이 항상 정답이 아님을 보여주며, 그렇다면 어떤 상황에서 어떤 모델을 쓸 수 있는지에 대한 가이드가 될 수 있다 생각한다.
저자: Namuk park
소속: Prescient Design Genentech, NAVER AI Lab
날짜: 2023.05.01 Arxiv 등재
학회: ICLR 2023
Github: [링크]
Problem
- Contrastive Learning (CL) 그리고 Masked Image Modeling (MIM)의 representation이 어떻게 다른지, 각각의 방법이
어떤 downstream task에서 잘 동작하는지 how 그리고 why를 ViT를 사용하여 밝혀내고자 한다.
아래에서 CL과 MIM에 대해 간단한 개념을 확인할 수 있다.
논문 읽기 - BEIT: BERT Pre-Training of Image Transformers
저자: Hangbo Bao 소속: Harbin Institute of Technology(하얼빈 공대) and Micrisoft research 학회: ICLR2022 Oral 인용: 991 (2023.04.30 기준) BaseLine - Bidirectional Encoder Representation from Transformers (BERT)는 NLP분야에서 뛰어난
187cm.tistory.com
논문으로 알아보는 Contrastive Learning (2) MoCo (Momentum Constrastive for Unsupervised Visual Representation Learni)
Contrastive learning의 대표적인 논문 중 하나인 MoCo에 대해서 소개하도록 하겠습니다. FaceBook, 현재 Meta인 Facebook AI research에서 Kaimming He께서 작성한 논문입니다. (ResNet 만드신 분) MoCo에 대한 개념 설
187cm.tistory.com
Abstract
1-1. CL은 longer-range global pattern을 잘 학습한다. 특히 ViT의 마지막 layer에서 "물체의 형태"를 잘 포획한다.
이는 ViT가 representation space에서 이미지를 선형적으로 잘 분류한다는 뜻이 된다.
1-2. 하지만 이 CL은 self-attention에서의 Query와 Key가 Multi-Head에서 동질성을 가져 붕괴된다는 문제가 있다. 이 뜻은 self-attention에서의 Representation이 감소한다는 것을 의미하며, 확장성과 dense prediction에서의 문제를 만들게 된다.
2-1. CL은 low frequency 신호 표현을, MIM은 High-frequency를 사용한다.
2-2. low, high frequency의 차이의 의해 CL은 물체의 형태를, MIM은 texture 정보 (구체적인 정보)에 초점을 두게 된다.
3. 또한 CL은 마지막 Layer가 중요한 역할을 수행하며, MIM은 초반 layer에 초점을 두고 있다.
-> 본 논문에서는 분석을 바탕으로 CL과 MIM을 간단한 방법으로 보완하는 법을 소개하고자 한다.
0. BackGround
0-1. Contrastive Multiview Coding (CL method)

- 먼저 BackGround로 Contrastive Learning의 방법론 중 하나인 CMC이다. 다른 CL 방법론과 매우 유사하다.
- 두 쌍의 이미지를 입력으로 넣는다. 각 이미지는, 각각의 Encoder를 통과한다.
- 각각의 Latent Vector 'z'를 Feature space에 mapping한다.
- 이 때, 두 이미지가 같은 source, label에서 왔다면 Positive sample이라고 칭하고 가깝게 mapping한다. 반면, 두 이미지가 다른 source나 label에서 왔다면, Negative sample이라고 칭하고 멀게 mapping한다.
- 이러한 과정에서 압축된 표현이 비슷한 표현끼리 군집화 시키는 것을 목표로 하며, 이런 과정에서 전체적인 이미지의 패턴, 특성을 파악할 수 있기에 "Image-level approach"라고 불린다.
- 자세한 설명은 아래 포스팅을 참고하자. 위의 정보만 알아도 Contrastive Learning의 큰 틀은 이해했다고 생각한다.
논문 읽기[CMC] - Contrastive Multiview Coding
오랜만에 돌아온 논문 리뷰. 오타와 대학과 함께 진행하는 논문 세미나에서 발표할 PPT의 Figure로 넣을 예정인데 혹시 몰라서 읽어볼 예정이다. 발표할 논문은 아래의 What do self-supervised Vision Transf
187cm.tistory.com
0-2. Masked AutoEncoder (Masked Image Modeling)
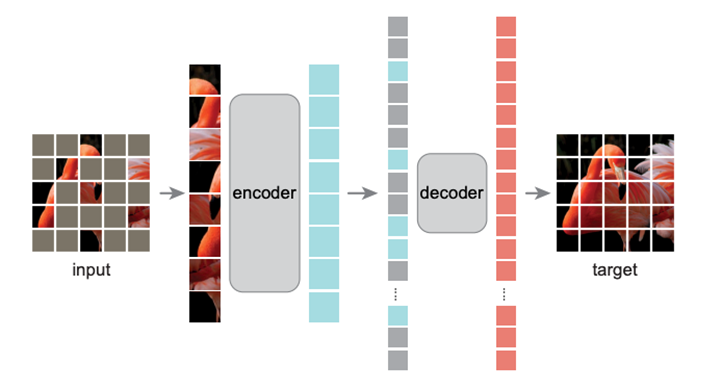
- 다른 방법론으로는 최근에 각광받는 MIM 방식인, Masked AutoEncoder를 짧게 설명하려고 한다.
- 입력 이미지를 ViT처럼 패치 단위로 쪼개고, 75%의 높은 비율로 패치 마스킹을 진행한다.
- unmasked된 패치를 입력으로 넣고, encoder를 통과 후, 다시 masked된 패치들과 합쳐져 decoder를 통과한다
- 이러한 과정에서 원본 이미지를 최대한 유사하게 복원하는 것을 목표로 하며, 이러한 과정은 각각의 패치들이 진행하기에, 각각의 패치들이 semantic information을 학습한다고 보면 될 것 같다.
- 그래서 이 방법론은 token-level approach라고 불린다. 자세한 설명은 아래의 포스팅을 참고하자
논문 읽기 [MAE] : Masked Autoencoders Are Scalable Vision Learners
논문 링크 : https://arxiv.org/abs/2111.06377 저자 : Kamming He 인용 : 2170 (2023.06.22) 소속 : FaceBookAI Research (MetaAI) 학회 : CVPR2022 Summarize - 아래의 왼쪽 이미지가 이 논문의 처음이자 끝이다. 이미지를 일정한
187cm.tistory.com
0-3. 그 외의 논문에서 자주 등장하는 방법론들.
우선, 위에서 설명한 MAE는 Chapter 4, Section 3에서 등장한다. 그리고 그 외의 section에서는 MoCo와 SimMIM을 주로 다루는데, 간단히 설명하자면 다음과 같다.


- 우선 왼쪽이 Contrastive Learning 방법론 중 하나인 MoCo, 우측은 MIM 방법론 중 하나인 SimMIM이다.
- MoCo는 다룰 것이 너무 많긴 한데.. 간단히 설명하자면 기존의 Memory Bank 방법론이 너무 메모리를 많이 차지하는 문제로 인해 EMA (Exponential Moving Average)를 사용하여 Memory bank와 유사한 Encoder의 Update를 진행한다.
- 즉 초록색 Encoder만 Backpropagation에 의해 학습되며, 파란색 Encoder는 EMA로만 업데이트가 된다.
- 그리고 Positive sample이 아래와 같은 체스라고 하고 query의 입력으로 들어가면, key에서는 다양한 sample들 즉 Positive와 Negative 샘플이 섞여있는 곳에서 하나의 +이미지, 나머지는 - 이미지로 취급하여 InfoNCE Loss를 구한다.
- 그리고 이 과정이 배치 단위로 진행된다고 보면 될 것 같다. Negative sample은 현재 배치 말고 Queue에 들어있는 다른 배치 묶음들이 될 것이다.
- 조금 더 자세한건 아래 참조하면 될 것 같다.
Contrastive Learning (2) MoCo (Momentum Constrastive for Unsupervised Visual Representation Learning)
Contrastive learning의 대표적인 논문 중 하나인 MoCo에 대해서 소개하도록 하겠습니다. FaceBook, 현재 Meta인 Facebook AI research에서 Kaimming He께서 작성한 논문입니다. (ResNet 만드신 분) MoCo에 대한 개념 설
187cm.tistory.com
- SimMIM은 따로 정리해둔게 없긴 한데.. 간단하게 정리하자면, 기존의 MAE에서 Decoder를 그냥 한층? 두층짜리 MLP layer를 쌓아서 구성했다. 그리고 성능이 잘 나왔다. 그리고 이 논문에서 이유를 분석해보자. (Section 3)
1. INTRODUCTION
- CL은 2개의 이미지의 invariant 정보를 학습하고자 하며, Positive, Netative 혹은 Similar, Dissimilar samples로 나눠 global한 representation을 학습하는 것을 목표로 하여, image-level self-supervised Learning 방법으로 불린다.
- MIM은 masked input patch에 대한 정보를 복구 시키는 것을 목표로 하여, CL과 다르게 patch token 정보를 학습하여 token-level self-supervised learning방법으로 불린다.
- fine-tuning result가 MIM이 상대적으로 뛰어나기에, MIM이 CL보다 더 좋은 방법으로 보이지만, 각각의 방법이 뛰어난 Task에 대해 CL/MIM 방식으로 Train된 방법을 대조하며 크게 3가지에 대해 이야기하고자 한다. 4번째는 둘을 간단하게 보완하여 성능을 더 높일 수 있는 방법을 제안한다.
1. the behavior of self-attentions. (Section 2)
2. the transformation of the representations. (Section 3)
3. the position of lead role component. (Section 4)
4. CL and MIM complement. (Section 5)
2. HOW DO SELF-ATTENTIONS BEHAVE?


(1번 IMG)
1. CL과 MIM이 항상 모든 task에서 정답이 아님을 보여주는 Figure 1. CL은 Linear probing에서 좋은 성능을,
MIM은 Fine-tuning에서 좋은 성능을 보인다. (Linear Probing과 Fine-tuning의 차이는 아래 표 참조)
2. 최근 MIM의 인기? 관심이 증가하고 있음에도 불구하고, MIM이 항상 Optimal 한 것은 아니다.
(2번 IMG)
1. 1번 그림이 ViT-B에 대해 그려졌다면, 여기서는 여러 모델의 비교를 했다. 특히 + 표시를 통해 실험 환경을 통일시켰다. 왜냐하면 두 논문은 다른 환경에서 학습이 됐기 때문이다. 따라서 hyperparameter를 통일 후, 100epoch동안 학습을 시켰다. + 표시가 없는 모델은, 그냥 다른 논문에서 주장하는 성능을 가져왔다.
2. 그리고 큰 모델에서는 MIM이, 작은 모델에서는 CL이 좋은 모습을 보여준다.
(3번 IMG)
1. Model size를 구체적으로 보면 작은 size에서 CL이 더 좋은 성능을 보임일 알 수 있다. (3번) 하지만 COCO 데이터 셋을 기반으로 한 dence prediction task에서는 MIM방식이 더 성능이 좋은 것을 볼 수 있다.
(4번 IMG)
우측의 표는 SimMIM Paper에서 가져온 성능 표 이다. Ours가 SimMIM이다. 1,2,3 이미지 보두 이 표를 기반으로 한다.
2-0. 추가적인 설명 및 Section 1의 흐름에 대해서
- 우선, Fine-tuning과 Linear-probing의 차이는 다음과 같다. Fine-tuning은 Downstream task에 적용을 할만한 새로운 모델을 만드는 것이 목표이며, Linear probing은 표현력이 좋은 사전학습 모델을 만드는 것이 목표이다.
- 그렇다면 무엇이 다를까? Fine-tuning은 pre-trained 모델을 downstream task에 맞게 전체적으로 재학습시킨다고 보면 될 것이다. Linear-probing은 모델을 Freezing한 후, 마지막 classifier layer만 학습을 시킨다. 따라서 사전학습 모델의 표현력이 좋아야 성능이 좋다.

2-1. CL mainly caputure global relationship
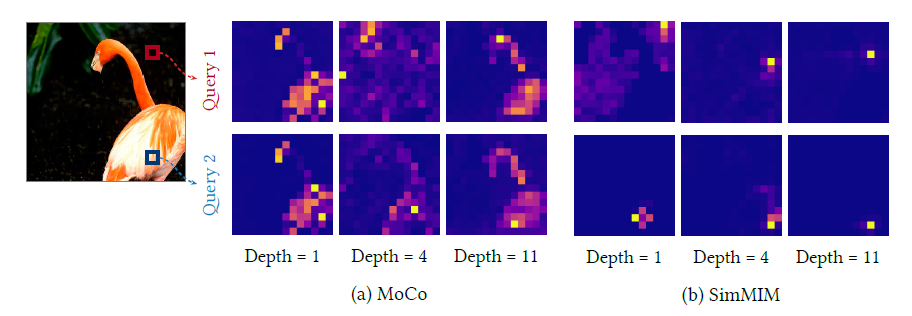

1. MOCO
- Figure 2를 통해 visual information을 확인했을 때, CL은 전체적으로 물체의 형태와 비슷한 Attention map을 보여준다.
- 활성화 된 Query Token의 값에 상관없이, 즉 빨간 쿼리 토큰이 골라지던, 파란 Query 토큰이 골라지던, CL은 항상 물체의 형태, 모양에 집중하는 것을 볼 수 있다.
- 이 말은, CL은 항상 물체를 찾으려고하며, 이는 Query token의 위치와 관계가 없이 항상 물체를 찾는다는 것을 의미한다.
2. SimMIM
- SimMIM은 Attention map이 localized된 것을 볼 수 있다. 빨간 Query 토큰이 활성화 되면, 그와 비슷한 위치에 Attention map이 활성화 되는 것을 볼 수 있다. 반대로 파란 Query 토큰이 활성화 되면, 마찬가지로 그와 비슷한 위치가 활성화된다
- 즉 SimMIM은 원래 목표가 이미지를 복구시키는 것이기에, 중후반 layer에서 주위의 정보를 바탕으로 패치를 복원한다. 따라서 위와 같이 localized된 Attention map을 출력하게 된다.
3. MOCO, SimMIM과 Attention Distance
- Figure 3즉 우측의 그래프는 Attention Distance를 시각화 한 것이다.
- Attention Distance는 CNN의 Receptive Field와 유사한 개념을 가지고 있는데, "모델이 이미지를 얼마나 보고 있는지에 대한 범위를 수치화 한 것이다."
- 즉 MOCO는 global하게 보고 있다는 것을 알 수 있으며, SimMIM은 처음에는 global하게, 나중에는 local하게 본다.
- 이 말은 MOCO는 global pattern을 잘 학습하는 것을 볼 수 있다. 이러한 이유에서 CL은 이미지에서 물체를 찾기 쉽다. 하지만 Query 또는 Key에서의 local정보를 보존하는 데에는 어려움을 겪을 것이다.
- MIM의 입장에서 처음에 global 하게 본다는 말은 입력 이미지가 들어오면 이미지에 배경정보, 물체정보를 파악하여 어떤 토큰이 어떤 토큰과 이어져 있는지 확인한다고 볼 수 있다고 생각한다. 그리고 후반 layer는 이미지를 복원해야하므로 점점 distance가 낮아지는 것을 볼 수 있다.
- 따라서 MIM의 경우 물체의 texture, 세부적인 표현을 학습하는데 도움이 되지만, 물체의 형태를 확인하는데 어려움을 겪는다.
4. MOCO, SimMIM의 특징과 Fine-tuning/Linear Probing과의 관계
Linear Probing
- 앞서서 말했던 것 처럼, Linear probing의 경우에는 사전학습된 표현력, 표현의 Quality가 매우 중요한 역할을 한다. 왜냐하면 모델을 Freezing 시키고, Classifier만 학습을 시키기 때문이다.
- 따라서 이미지에서 물체의 정보, 경계선을 구분할 수 있는 CL이 Linear probing에서 좋은 모습을 보인다
- MIM도 세부적인 정보를 파악하긴 하지만, 물체의 전체적인 정보를 학습하는 CL과 비교했을 때 당연히 성능이 떨어진다.
Fine-tuning
- Local하게 정보를 파악하는 MIM은, 물채의 Texture, 세부적인 정보를 다양하게 얻는다. 그리고 이러한 점은, Fine-tuning에서 새로운 Downstream task를 만났을 때 좋은 성능을 보여준다.
2-2. Self-attentions of CL collapse into homogeneity.
- 또한 CL의 마지막 layer에서 query, key, Head가 동일하여 attention map이 무너지는 현상을 발견 하였다.
- 2개의 다른 공간에서 온 query 정보를 비교했을 때 (ex Head가 다른데 위치는 같은 query), 두개의 query token은 MIM과 비교하였을 때, 비슷한 모습을 보였다. an attention collapse into homogeneity 라고 소개한다.
- Normalized Mutual Information(NMI)를 사용하여 attention collapse를 확인하였다. (아래의 수식이 NMI)

- p(q)는 query token의 분포를 나타내며 uniform한 분포라고 가정한다. 따라서 single query token은 1/N (N = 토큰 수)
- query, key 토큰의 joint distribution은 p(q, k) = π(k|q)p(q). 이 때 π(k|q)는 softmax-normalized self-attention matrix
- 따라서 NMI는 위와 같다. I(⋅,⋅)는 marginal information이며, H()는 marginal entropy이다.
- 다시 정리하자면, H(⋅) = Σ p(⋅) log(p(⋅)) 이고, p(q)는 Uniform Distribution으로 가정하므로, p(q) = 1/N


ex) query와 key token의 shape은 [B, H, seq, dk] 이다. 또한 self-attention의 결과는 [B, H, seq_q, seq_t] 이다. 우리가 attention map을 볼 때, seq_query를 for문으로 돌면서 seq_t = 196 = 14x14로 주로 시각화를 한다. CLS 토큰 뺴고..!
그래서 p(k) = 1/N이다. 내가 원하는 패치에 대해 attention map을 보고싶다면, 우리가 고르는 위치는 Query의 위치가 된다. 즉 위에서 빨간 위치에 대한 attention map를 보고싶다면, 그냥 위치를 고르면 된다. 이에 대한 확률은 p(k) = 1/N이다.

그렇다면 p(k)는 어떻게 구할까? 똑같이 1/N 이라 생각하면 틀렸다. 왜냐하면, p(k) = Σ p(qi) attn 이다. 이게 뭔 소리냐면, p(k)는 query의 확률 x 해당 쿼리의 attention map을 곱한 값이다. 다시 위로 돌아가 [B, H, seq_q, seq_t] 형태의 self attention map은 q x kT 형태로 만들어졌지, k x qT 형태가 아니다. 따라서 특정 key가 attention이 될 확률이 p(k)이며, 이는 위의 수식과 같다.


- 그래서 말하고자 하고 싶은건 위와 같다. 두 query와 key가 비슷하면, NMI가 낮고, 다르면 NMI가 높다는 걸 보여준다.
- 실제로도 query = key 이면 NMI에서 I() 내부의 p(q, k) = p(q)p(k) 가 되며, 이로인해 log 내부가 1이되어, 같을 때 값이 0이 됨을 보여준다. 아 여기서 p(q, k) = π(k|q)p(q). 이기에 위와 같이 된다. 만약 p(q,k)가 joint probability 이면 p(q,k) = p(q).
- low mutual information은 attention map이 token에 덜 의존한다는 것을 보여주며, homogene
ity하게 붕괴됨을 보여준다. 반대로 high mutual information은 attention map이 token에 강하게 의존한다는 것을 보여준다.

- 따라서 결론은 다음과 같이 Collapse problem이 발생을 하며, 이는 표현력의 저하로 이어지지 않을까 하고 우려를 한다.
2-3. Attention collapse reduces representational diversity.

- self attention map이 homogeneity로 무너질 때, 결국 homoheneous한 token representation을 이끌어 낼 것이라 생각.
- 따라서 cosine similarity를 Head, Depth, token에 대해 각각 구하는 실험을 진행하였고, CL이 MIM과 비교했을 때 후반 layer에서 높은 similarity를 보여주었다. == Collapse Problem

- 또한 Model의 크기를 늘리는 것은 CL의 해결책이 아닌, 더 나빠질 수 있다는 것을 보여주었다. MIM은 상승을 보여주었다
- (a) 부터 heads를 비교하였을 때, 아래와 같이 MIM, CL모두 성능이 떨어지는 모습을 보였다. 실선은 ViT-B, 점선은 ViT-S
- 내 개인적인 의견은, MIM에서 Small Model을 사용할 때 similarity가 증가한 이유는 학습이 덜 되서 라고 생각한다. 작은 모델이기에, 효과적으로 이미지 복원을 하지 못해, token끼리 유사해지며 Head의 output이 비슷해지지 않았을까 생각한다
- 저자는 Head의 수를 늘리는 것은 효과적이지 않다 라고 주장하는데.. 그냥 Model Capacity가 전체적으로 낮아졌는데, Head만 영향을 주었다고 보는 것은 이해가 가지 않았다.
- (b) 에서는 Large model을 사용하여 비교하였을 때를 보여주었는데, Large Model의 경우, Cosine similarity가 후반 Layer에서 그냥 1에 수렴하는 모습을 보인다. 이는 위에서 보인 Collapse Problem 때문이며, 저자는 CL에서 불필요하다고 주장.
- 따라서 CL은 큰 모델에서 상승하지 못하며, MIM보다 뒤쳐지는 결과를 보인다. 하지만 작은 모델에서는 MIM이 효과적이지 않기에, CL이 더 좋다고 생각한다.

- 마지막으로 Dense Prediction Task에서 왜 CL이 낮은 성능을 보여주는지에 대한 그림이다.
- 같은 spatial loaciton에 위치한, 같은 self-attention layer끼리의 Cosine similarity를 구했을 때, 위와 같은 모습을 보였다. 즉 CL은 점점 후반 layer에서 공간정보에 대한 구분을 아에 안하는 모습을 보여주며, 이는 Dense prediction 시에 문제를 일으키게 된다.
- 반면 SimMIM은 그냥 모델이 깊어질수록 Similarity가 더 낮아지는 모습을 보이는데, 이는 패치 토큰들이 다양하게 정보를 보며 세부적으로 파악한다는 의미가 된다. 따라서 이러한 특성에 의해 Dense prediction에서 효과적인 모습을 보인다.
2.4 Implications of the behaviors we observed
- 결과적으로 CL은 linear probing, classification, smaller task에 효과적이며, MIM은 CL의 fine-tuning, dense prediction task를 큰 모델로 적용할 때 성능이 좋았다.
- 이런상황에서 CL의 self-attention map은 물체의 경계의 초점을 두고 학습을 하므로 물체의 형태를 잘 잡지만, Token들의 diversity는 잃어버리기 쉬우며 attention collapse문제가 생길 수 있다.
- CL은 주로 global relationship을 학습하고, MIM은 local relationship을 학습한다는 것을 알아냈다.
3 HOW ARE REPRESENTATIONS TRANSFORMED?
- CL과 MIM의 Token representation을 분석하고, self attentation에서 어떤 특성이 나타나는지 설명한다.

- 맨 처음에 설명한 token/image level approach처럼 접근을 시도한다. SVD를 사용할 것이며, Image level approach는 그냥 GAP써서 진행을 하였다.
3-1. CL transforms all tokens in unison, while MIM does so individually.

- 위의 Figure 6는 총 196개의 token에 대해 self-attention을 적용하기 전인 첫번째 layer와, 마지막 layer의 output을 비교한 사진이다. 원 또는 삼각형 모양의 점은 모두 Token level을 SVD*를 통해 얻어진 값이다. 중앙의 X표시는 Image-level approach의 SVD를 적용한 값이다.
- 위의 그림은 ImageNet validation set 중 하나, 혹은 두개를 사용하여 시각화를 진행하였다.
SVD: Singular value decomposition
(a) CL의 경우 모든 토큰이 일정하게 움직이므로 attention map이 처음과 끝에서 분포 및 형태가 동일하다는 것을 나타냅니다. 심지어, 여러개의 layer를 통과했음에도 불구하고, z = z+c 와 같은 형태를 보입니다. 즉, CL에서의 query token은 독립적입니다. 즉 CL은 Token에 대해 덜 신경을 쓴다는 것을 나타내며 encode된 image를 사용하지 않는다*는걸 의미합니다
* encode 된 image를 사용하지 않는다는 표현은 token에 의해 처리된 표현이 아닌 raw이미지를 사용한다는 뜻 입니다.
(b)에서는 (a)에서 CL이 항상 일정한 Attention map을 가지더라도, 이미지를 선형적으로 분류할 수 있는 힘이 있다고 주장한다. 각 이미지의 중심점 X (파란원)이 서로 멀어지는 모습을 화살표로 볼 수 있다. 즉 Token의 분포는 신경쓰지 않는데, Image를 비교할 때는 둘의 중심 좌표를 멀어지게 학습하는 모습을 볼 수 있다. CL == Linearly separable하다.
(c) SimMIM은 각각의 token에 대해 다른 변환을 수행하였고, 표현 분포뿐 아니라 이미지 간 Token의 거리도 변경시킨다. 또한 재미있는 점은, 이 부분을 2D -> 3D로 넘어간다 표현을 한다. 그만큼 토큰이 다양하게 정보를 학습한다는 것을 의미한다.
Two Quantitative Methods for Investigation

- 위에서도 SVD를 쓰긴 썼는데 아래에서도 사용할 예정이고, 푸리에 변환을 통해 latent vector/feature space에서의 값이 고주파/저주파 인지를 바탕으로 어떤표현을 학습하는지 볼 예정이다.
- SVD에서 얻어진 표현 분포의 singular value를 제공하므로, 표현공간에서 유용한 분포 확인 가능.
- PCA랑 유사하다고 보면 된다. 유용하지 않은 정보는 결국 사라지게 되니까 token이 유용하지 않다면, 값이 줄어들 것.

1. SVD의 수식은 아래와 같다. 여기서 log singular value는 시그마의 값에 log을 취한 것을 의미한다.
2. Rank index는 시그마의 값이 내림차순으로 정렬되는데, 이 값에 따른 순서이다.
3. 색이 연해질수록 더 깊은 layer를 의미한다.
4. 이걸 통해서 각 layer에서의 토큰이 모델에 얼마나 영향을 미치는지 알 수 있다. [다양성, 확산의 척도]
그래프 해석 [63번째 index를 기준으로 해서] singular value 값을 확인해 보았을 때
1. CL은 layer가 깊어질수록 점점 줄어드는 것을 볼 수 있다.
2. 이것은 CL이 Token을 구분하는 것을 매우 힘들게 여긴다.
a) why? 이것은 이 later layer의 토큰들이 한 공간에 모이는 것을 의미 그래서 어렵다
b) 그리고 이것은 later layer들의 토큰이 남아 돈다는 것을 의미. = 모델 크기와 연관 = 큰 모델이 CL에서 불필요
3. MIM은 늘어나다가 줄어드는 것을 볼 수 있다. MIM은 token을 아주 잘 사용한다는 것을 의미. singular values가 줄어드는 것은 디코더랑 연관 있음 – section 3
4. 그래서 MIM은 token-level 이다.

- 사실 이것도 똑같다 Rank가 392인 이유는 원래는 [depth, Batch, Head, Seq, dk] = [12, Batch, 12, 196+1, 768] 인데, 여기서 768을 그대로 시각화 하기엔 너무 많아서 잘랐다고 생각이 든다. 196+1은 14X14개 패치에다가 +1의 CLS토큰이다.
- 이제 CL은 위와 반대의 결과를 보여준다 == CL은 Image-level approach이다.

- t-SNE 시각화. 3개의 IN-1k validation set 클래스 중에서 18개 이미지를 골라서 시각화를 했다
- CL은 전체적으로 클래스끼리 Linearly separable한 모습을 보여주며, 심지어는 이미지 끼리도 분류할 수 있을만큼 군집이 잘 되어있다. 반면 MIM은 그냥 뭐 고르게 퍼져있다. 그만큼 MIM이 다양한 표현을 학습했다는 것을 보여준다.
3-2. CL exploits low-frequencies, and MIM exploits high-frequencies.

- 왼쪽이 low-frequency 우측이 high frequency의 정보. low는 shape-biased or content biased, high는 texture biased이다.
- log frequency = high freq – low freq = log amplitude.
- 푸리에 함수를 각 layer의 output에다가 적용을 한 후 위의 수식처럼 high-low를 통해 log amplitude를 계산하였다
- 결과적으로 SimMIM은 고주파 즉 텍스쳐 정보를, low인 CL은 형태를 파악한다.
- CL은 image-level의 transformation을, self-attention에서는 전체의 토큰에서 물체의 형태를 학습한다. 따라서 Token은 다양해지기 보단, 가까워지게된다. 따라서 CL은 이미지를 잘 구별할 수 있지만, token을 잘 구별하지 못한다.
- MIM은 Token-level 정보를 보존시키고, 증폭시키며 상대적으로 Token들이 여분의 정보를 가질 수 있게한다.

- layer output에 노이즈 더했을 때, CL은 low에서, MIM은 high에서 성능이 많이 떨어지는 것을 보였다. 따라서 CL는 low frequency에 취약한 shape-biased, image-level approach.
- 반대로 MIM은 high frequency noise에 약한 texture-biased & token-level approach
4. WHICH COMPONENTS PLAY AN IMPORTANT ROLE?

1. Linear Probing task는 아까도 말했지만, pre-train된 모델의 representation quality가 매우 중요하다.
2. 중반까지 SimMIM이 좋다가 떨어진다. 그 이유는 디코더 때문이다.
3. MIM은 상대적으로 MOCO보다 떨어지지만, 그래도 잘 증가하는 모습을 보인다.

- 푸리에 분석을 통해 low-frequency신호, high-frequency 신호를 비교한다.
- CL의 마지막 layer와, MIM의 초기 Layer의 중요성을 분석한다.
- 초기 layer는 보통 low-level특징 (local pattern, high-freqency signals, texture info.) 그리고 후반부 layer는 global pattern (low-frequency signals, shape info.)등을 학습한다.
- SimMIM은 푸리에 분석에서 9번째 layer부터 frequency가 떨어지는 모습을 보인다. 하지만, MAE는 마지막 layer를 제외하고 꾸준하게 frequency가 상승하는 모습을 보인다. 그리고 Decoder에서 바로 저수준의 주파수를 잡는 것을 볼 수 있는데, 이 low frequency가 blur된 이미지이므로 MIM의 출력 결과가 blur되는지를 보여주는 이유가 된다.
5 ARE THE TWO METHODS COMPLEMENTARY TO EACH OTHER?

- CL과 MIM을 간단하게 보완하여 이 둘 보다 성능 좋은 방법을 보여준다. (ㅅ = 0.2일 때 성능이 올라감을 보임)

6 CONCLUSION
- CL과 MIM의 특징, 차이, benefit을 self supervised learning에서 ViT를 통해 기술하였다.
- 두 CL과 MIM을 결합한 모델이 효과적일 수 있으며, multi stage ViT로 확장하여 CL과 MIM의 개별 특성을 개선한 새로운 연구 방향 제안 가능
