오늘은 CVPR 2023 Contrastive Learning / Self-Supervised Learning 관련 논문을 찾아보다가 인용 수가 많은 논문이 있길래 간단하게 정리해보려고 한다.
저자: Chenxin Tao
소속: Tsinghua University(칭화대)
학회: CVPR2023
인용: 36 (2023.08.18 기준) 2022년 11에 Arxiv에 올라왔으니 꽤 오래되긴 했으나, 그래도 CVPR Contrastive/Self-Suervised Learning 코너에서 인용수가 가장 높았다.
링크: https://arxiv.org/abs/2206.01204
Github: https://github.com/OpenGVLab/Siamese-Image-Modeling/tree/main
Table 1. 모델의 성능. 84.1로 이정도면 ImageNet에서 DINOv2 시리즈 다음으로 높은 성능을 보여준다.

0. Abstract
- Instance Discrimination (ID)와 Masked Image Modeling (MIM) 으로 크게 구분 지을 수 있는 Self-supervised Learning (SSL) 이다. 하지만 이 ID와 MIM의 차이는 너무 뚜렷하며, 따라서 적용할 수 있는 downstream task 분야가 차이가 있다.
++ 차이는 Introduction에서 그냥 한번에 다뤄야지
- 이 논문에서는 이 단점들을 보완하기 위한 방법론들을 섞었으며 따라서 위와 같이 더 좋은 성능을 얻었다는 것이 결론.
1. Introduction


- Self-supervised Learning (SSL) 방법론은 human-annotated label없이 많은 양의 unlabeled data를 사용 가능하게 했다.
- 왼쪽이 ID (사진:Contrastive Multiview Coding), 오른쪽이 MIM (사진: Masked AutoEncoder). 설명은 아래에서 하겠다.
1-1. Instance Discrimination (ID)
- ID는 같은 이미지에서 다른 Augmentation을 적용한 represnetation을 서로 가깝게 만들어서 representational collapse를 피하고 SSL을 효과적으로 적용하기 위한 방법론이다. pretext task를 사용하였으며, 주요 방법론들은 아래와 같다.
1. Contastive Learning: Positive/Negative sample을 만들어 feature space에 압축된 representation을 mapping한다. Positive는 Positive끼리 학습하게 하는 것이 목표이다. ex) MOCO, SimCLR
2. Asymmetric Network: simsiam, BYOL과 같이 Base Encoder와 Projection Head를 가지고 학습 한 후, Encoder만 downstream task에 사용하는 Asymmetric Network 방법론이 있다.
3. feature decorrelation, intrinsic consistency는 안봐서 모르겠다...
- 이 ID 방법론의 주요 특징은, 이미지의 압축된 표현을 비슷한 정보끼리 mapping 시키기 때문에 linear probing task에서 성능이 좋으며, linear separability가 좋다는 것이다.
- 하지만 이 ID는 spatial sensitivity가 부족한데, 즉 이미지 전체를 압축하며, 공간적으로 유의미한 세부적인 feature를 신경쓰지 않기에, Dense prediction task에서 상대적으로 밑의 MIM 방법론 보다 낮은 성능을 보인다.
- 하지만 가장 큰 단점은, Supervised Learning으로 pre-train된 모델보다 더 성능이 낮으며, 심지어는 random initialization한 모델을 길게 training 시켜도 ID보다 성능이 좋다는 것이다.
1-2. Masked Image Modeling . (MIM)
- Masked Image Modeling은 위의 그림과 같이 원본 이미지를 패치 토큰으로 나누고, 75%를 랜덤하게 마스킹 후, Unmasked token을 Encoder에 통과시킨다. 그리고 다시 masked token과 합치고 원본 이미지와 최대한 같게 복구한다.
- 이 과정에서 각각의 패치들이 정보를 학습하기에 풍부한 local structrue를 가지게 된다. 즉, 이런 정보를 바탕으로 Object detection과 같은 분야에서 성능이 좋지만 linear separability가 없기에 few-shot classification에서 낮은 성능을 보인다.
- 즉, MIM은 하나의 이미지를 가지고 패치들이 세부적인 정보를 학습하려 노력하지, semantic alignment와 같이 비슷한 정보를 인식하거나 학습하는 모습이 없기에 linear probing과 같은 task에서 부진하다
1-3. So what?

- 그래서 ID, MIM 모두 각각의 장점, 단점이 뚜렷하다. 이런 서로의 딜레마를 해결하기 위한 SiameseID를 제안하는데,
1. semantic alignment는 두 개의 projeciton된 representation을 근처에 두게끔 만들면 해결된다. SimCLR과 비슷하게, Strong augmentation을 사용하여 invariance를 더 주입하는 방법으로 해결하였다.
2. spatial sensitivity는 local structure를 요구하므로, local structure를 주입하면 된다는 설명이다.
3. ID와 MIM의 방법론을 합친것과 매우 유사한 방법론을 가진다. Semantic alignment와 spatial sensitivity를 하나의 Dense Loss만을 사용하여 학습을 진행하였다.
2. Related Work.
- 위의 introduction의 설명으로 충분하다.
3. Method

- online encoder는 MIM 방식으로 동장한다고 보면 될 것 같다. Target Encoder는 EMA방식으로 online encoder 방식에 의해 학습이되며, target encoder의 출력물은 online decoder를 통해 만들어진 내용물과 Dense loss를 통해 이루어진다.
- online decoder의 입력은 (압축된 encoder의 mask[파란색용] + mask[주황색용]) 이 Concat되어 들어간다. 아 물론 PE.
- SimCLR에서는 Strong Augmentation(spatial + color)이 좋다고 하였는데, MIM에서는 Color augmentation이 좋지 않다는 주장을 하였기에 이 논문에서는 그 차이에 대한 성능 차이 또한 명시하였다. [section 4에서 명시]
3-2. Prediction Targets

- 우선 위의 이미지는 두개의 Encoder에 대해 각각 Positional Encoding을 어떻게 하였는지를 명시해주고 있다.
- 파란색 (Online Encoder에 들어감) 패치의 위치를 바탕으로 주황색 (Target Encoder) 패치에 상대적인 좌표를 계산하여 Positional Encoding을 진행하고 있다.

- 위의 수식은 yb 즉, online decoder의 출력에 대해 알려준다. g()가 decoder이며, ya는 encoder의 출력, pa, pb는 online decooder에서의 PE방법, m은 target encoder와 비교하기 위해 만들어지는 mask이다.
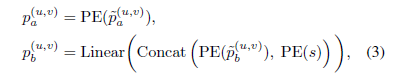
- 또한 pb는 다음과 같이 구성이 되는데, scaling fucntion과, Linear가 차원을 맞추기 위해 들어갔다.

- Loss functon은 다음과 같으며 lambda는 0.02이다.
4. Experiments
- 성능비교

- 아래는 Augmentation 관련 성능

'Deep Learning (Computer Vision) > Self-Supervised Learning' 카테고리의 다른 글
| 논문 파헤치기 - What Do Self-Supervised Vision Transformers Learn? (2) | 2023.05.04 |
|---|
