제목 : Training Data-efficient image Transformers & Distillation through attention [DeiT]
저자 : Hugo Touvron, Matthijs Douze, Alexandre Sablayrolles, Herv´e J´egou
소속 : Facebook AI, Sorbonne University (프랑스 파리)
인용 : 3958 (2023.09.22 기준)
링크 : https://proceedings.mlr.press/v139/touvron21a
학회 : ICML2021
돌고 돌아 돌아온 오타와 세미나 발표.. 1주밖에 안남았는데 교수님께서 할당해주신 논문을 다른 걸로 바꿨다.
원래 논문은 When to Prune? A Policy towards Early Structural Pruning 라는 CVPR2022 논문이였지만, 사실 이 논문이 어쩌다보니 나한테왔고, pruning은 알지만 논문 발표할 수준은 아니라서 패스했다. 리스트에 DeiT-III가 있었는데, DeiT 발표 기록이 없어서 먼저 골랐다. DeiT-III는 뒤이어서 해야지. 근데 DeiT-II는 안보인다.. 어쨌든 DeiT 톺아보기 출발이다.
DeiT의 간단한 배경지식을 먼저 말하자면, ViT는 Convolution Free Encoder를 사용하여 기존의 CNN을 대체할 수 있을만한 유의미한 모델 구조를 제시했다. 하지만 이 ViT의 가장 큰 단점은 JFT-300M 이라는 3억장의 이미지라는 엄청나게 많은 양의 훈련데이터를 필요로 하기에, Google이 아니면 시도조차 불가능했던 시도라고 생각된다.
따라서 본 논문의 저자가 속한 Google의 가장 강력한 경쟁자 FaceBook이 굳이 그렇게 까지 많은 양의 데이터가 필요해? 하며 Training data-efficient image transformers 즉 DeiT 논문을 제시한다.
사전 지식
Throughput: is measured as the number of images that we can process per second on one 16GB V100 GPU.
Presentation 1장 요약


Goal (Objective)
- To train a vision transformer efficiently using limited data and achieve competitive performance compared to CNN with similar parameters and efficiency.
Contribution
- we don't use Conv layer which can achieve competitive result against the SOTA on IN-1k with no external data.
- we introduce a new distillation procedure based on distillation token wihci plays the same as the class token.
Problem
- Developing a Transformer model for image classification that achieves competitive performance without the need for training on massive datasets, unlike previous models like ViT.
Methods – Experiment setup
- Introduced a data-efficient image transformer (DeiT) that utilizes novel distillation procedures and existing data augmentation strategies from convnets, without significant architectural changes beyond the distillation token.
0. Abstract
- Attention based model이 Image classification에서 두각을 들어냈고, ViT가 JFT-300M을 사용하여 좋은 성능을 보였다
- 우리의 DEiT는 Convolution-free Transformer구조 + ImageNet 데이터만 사용하여 ViT와 유사한 성능을 보인다.
- Teacher-Student 구조 및 distillation token을 사용, 하지만 Teacher Network는 ConvNet을 사용.
1. Introduction
- ImageNet을 통한 Classification의 시도, 그리고 BERT, Transformer와 같은 NLP 분야에서의 성공이 있었다.
- SENet과 같이 Attention mechanism을 CNN에 도입하려는 시도도 존재하였고, 둘을 섞는 모습도 있었다.
- ViT는 Transformer와 매우 유사한 구조를 바탕으로 raw image를 patch 단위로 쪼개서 입력으로 넣었다.
- 이 ViT는 성능은 좋았지만 JFT-300M이라는 큰 데이터 셋으로 학습이 되어야만 했으며, "do not generalize well when trained on insufficient amounts of data" 라는 결론을 내렸다. 또한 Computing resources도 엄청나게 많이 들었다.
- DeiT는 53시간의 Training시간, 20시간의 Fine-tuning시간이 소요되며 (GPU 8개) CNN과 비슷한 수준의 Parameter 수와, 효율성을 보인다.
- 또한 DeiT ⚗ 표시는 기존의 Distillation 방식과 다른 방식을 사용해서 적용했다는 것을 의미한다.
2. Related work.
Image Classification
- Image Classification (CNN) : AlexNet, VGG, EfficientNet, Fixefficientnet, Noisy-Student
- Image Classification 분야에 Transformer 접목 시도 : Generative pretraining from pixels (하지만 CNN 보다 성능 낮음)
- hybrid (CNN + Attention) : Visual transformers (classification), DETR, Relation networks for object detection (OD), Videobert, Non-local neural networks(video processing), .. ect
- 그리고 ViT가 효과적이기 위해서는 pre-train 단계에서 많은 양의 labeled 된 데이터가 필요. 하지만 DeiT는 필요 없다.
The Transformer Architecture.
- SENet, Selective Kernel, Split-Attention Network 등 이 있다. 아래 링크 참조
Vision 분야에 적용된 Self-Attention 알아보기 [Non-local Neural Networks, SENet, On the Relationship between Self-Atten
1. Non-local Neural Networks 제목 : Non-local Neural Networks 저자 : Xiaolong Wang , Kamming He et al 소속 : Carnegie Mellon University & Facebook AI Research 학회 : CVPR2018 인용 : 9010 (2023.09.24 기준) 링크 : https://arxiv.org/abs/1711.079
187cm.tistory.com
Knowledge Distillation
- Jeffery Hinton에 의해 제안된 Knowledge distillation은 Student model이 Teacher model에서 온 soft label (softmax function)을 학습하는 것이며 hard label (maximum score)를 학습하는 것 보다 더욱 효과적이라 하였다.
- 추후에 나온 논문 Revisit KD: a teacher-free framework에서는 이 soft-label로 학습하는 것이 label smoothing의 효과가 있다고 하였다. Circumventing outliers of autoaugment with KD에서는 Teacher Network에서 Augmentation이 중요하다고 말한다.
- 그리고 Transferring inductive biases through knowledge distillation에서는 Inductive biases를 KD를 통해 Soft하게 전달할 수 있다고 하며, 따라서 본 DeiT에서는 Teacher Model로 CNN or Transformer 모델을 사용하여 실험을 하였다.
3. Vision Transformer Overview.
- 아래 링크 참조.
논문 톺아보기 및 코드 구현 [ViT-1] - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR
필자가 이 논문을 처음 봤을 때가 2022.11.14일인데, 이 때 기준 인용 수가 8829이다. 현재 2023.09.22기준 21446회.. 그 당시에도 한달마다 몇백회씩 인용수가 늘어나는 것이 놀라웠는데, 이젠 그 이상으
187cm.tistory.com
4 Distillation through attention
- 이번 section에서는 Strong(성능이 좋은) Image classifier를 Teacher model로 사용하는 것을 목표로 한다. 위에서 잠시 언급했지만 이 Teacher Model은 ConvNet or ViT가 될 수 있다.
- 중점적으로 볼 내용은, Hard Distillation vs Soft Distillation 이 될 것이며, Classical distillation vs distillation token사이의 비교가 중심이 될 것 이다.
4-1. Soft distillation

- 가장 먼저 보이는 Soft distillation이다. Soft인 이유는 KL divergence 부분 때문인데, Zt가 logit이기 때문에 logit과 logit 즉 분포와 분포를 비교하기에 KL divergence loss를 사용하며 Soft distillation이라 불리는 것 이다.
- CrossEntropy와 KL divergence loss 간의 λ hyperparameter를 통해 조절이 가능하다는 것이 특징이다.
- 두 CE, KL loss 모두 일반적인 수식을 그대로 따르기 때문에 딱히 이야기 할 것은 없는 것 같다.
- Zs, Zt는 Logit이다. (Student/Teacher의 distribution 그 자체)
- ψ = softmax function
- Section 6에서 언급하는 Soft distillation에서의 hyperparameter setting은 λ = 0.1, τ = 3.0이다. τ = 3.0이면 Smoothing을 좀 심하게 주는 것을 볼 수 있다.
4-2. Hard distillation
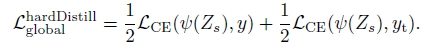
- 이 Hard Distillation은 약간 다르다. 멀리서 보면 같은 CE x2로 보이겠지만, 여기서 yt = argmax_c(Zt(c))이다.
- 즉 Teacher의 비교 대상이 Soft에서는 KL divergence를 이용한 Loss였다면, 여기서는 one-hot vector가 되는 것이다.
- 따라서 KL divergence loss가 아닌 Cross-Entropy를 사용했다.
- 위의 2-Related Work에서 언급한 것 처럼, Hard Distillation은 잘못된 Augmentation이 문제를 일으킬 수 있다고 하였다. 하지만 우리의 DeiT는 ViT에 비해 적은 Dataset을 사용하므로 Strong Augmentation을 적용해야하기에, 이러한 문제를 잘 신경써서 Augmentation을 진행 해야한다.
- 이러한 Hard Distillation의 사용이 τ, λ와 같은 파라미터의 사용을 줄일 수 있으며, y와 y_hat이 유사하므로 CE loss를 사용하기에 conceptually simpler하다고 말한다.
- 또한 이런 Hard Distillation은 hard-label을 사용하므로 label smoothing 사용이 가능, hyperparameter인 ε = 0.1로 설정.
4-3. Ditillation Token
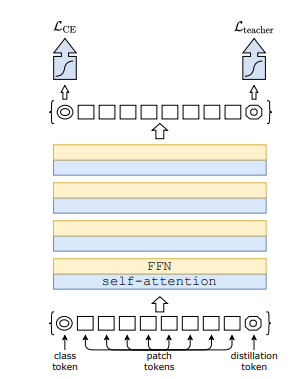


- 위의 그림에서 볼 수 있듯이 Distillation Token은 Class Token이 뒤에서 만들어진 것과 매우 유사하다.
- 이 Distillation token의 목표는 Teacher model의 CLS 토큰에서 나온 hard label을 Student model에서 이 Distillation token을 사용하여 예측하는 것이다.
- 이 CLS token과 Distillation token의 cosine similarity를 계산해봤을 때, 0.06 → 0.93 까지 올라가는 것을 볼 수 있다. 이 뜻은 distillation token이 backpropagation을 통해 CNN의 discriminative feature를 학습하며 target의 예측과 유사해지지만, 완전 똑같은 것은 아니라는 것이다.
- Conv Teacher를 사용하여 얻을 수 있는 discriminative feature를 Student Model이 참조할 수 있게 뒤쪽에 넣어주고, Transformer기반의 DeiT가 얻을 수 있는 discriminative feature를 활용할 수 있게 만든다고 볼 수있다.
참조 1. CNN의 discriminative feature: inductive bias로 인해 spatially hierarchical, localized feature가 될 것 이다.
참조 2. ViT의 discriminative feature: Attention mechanism으로 얻을 수 있는 이미지 내의 전체적으로 연결된 물체들 간의 정보.
- 추측이 가능한 이유는 Distillation token을 CLS token바로 뒤에 두었을 때, 둘의 cosine similarity가 0.999 였기 때문
- 우측의 그래프를 보면 ↑⚗ 표시가 가장 높은데, Fine-tuning 단계에서 Student 모델의 해상도를 높여서 진행한다는 표시이며 ⚗는 Distilation token을 활용한 distillate 방법론의 결과이다. 두 방법론 모두 좋은 성능을 보여준다.
- 우측의 표는 Hard label 방식이 soft label 방식보다 항상 좋다는 것을 보여준다.
4-4. Fine-tuning Method
- fine-tuniung단계에서는 Fixing the train-test resolution discrepancy NIPS 2019 논문을 참고하여 Teacher Model의 해상도는 fine-tuning task의 해상도와 동일하게 만들고, student 모델의 입력은 더 큰 해상도를 가지게 한다. (224→384)
- 일반적인 fine-tuning과 같이 Distillation없이 fine-tuning 진행 시 성능 감소하는 현상 존재.
++ lower teacher input resolution & higher student model input resolution.
4-5. Classification with our approach: joint classifiers.
- 풀어서 설명하면, CLS token - fc layer - softmax를 통과한 output 1, distillation token - fc layer - softmax를 통과한 output2를 구해서 output1 + output2를 해서 classification을 진행한다.
5. Experiment
DeiT 특징 1: ViT와 유사하지만 MLP-Head에서 MLP layer를 사용하지 않고 direct하게 linear classifier 붙임.
DeiT 특징 2: 별다른 언급 없으면 ViT-B 모델
DeiT 특징 3: ⚗ 표시는 Distilation token을 사용하여 distillation 작업을 진행했다는 표시




- 유의미한 정보는 Throughput 정도가 되겠다. 우측의 성능표는 Fine-tuning을 한 것이 확실히 좋다.
- 추가적으로 우측 상단 성능 표에서 DeiT를 Teacher로 썼을 때 보다, ConvNet을 Teacher로 썼을 때 더 좋다.
- DeiT의 파라미터 수는 ViT와 매우 유사하다. (아래 Table 1 ViT 파라미터 수 참조)
5-1. CIFAR10
- training from scratch성능 비교

5-2. ImageNet Score
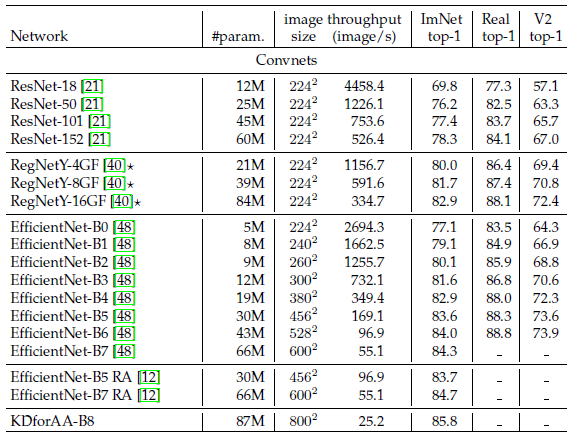
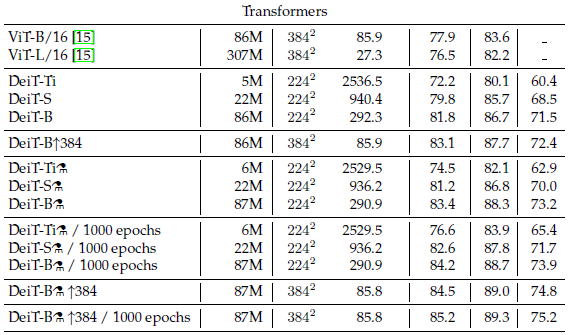
- Batchsize는 쓸 수 있는 최대한으로 사용. throughput은 30번 평균
- 주요 특징은 IN-1k 데이터 셋으로만 훈련시켰을 때, ConvNet과 DeiT가 유사한 성능을 보인다. (EfficientNet-B7이 0.1 더 높다) 또한 ViT-B를 IN-1k로만 훈련 시켰을 때, 77.9%의 정확도를 보이지만, 같은 환경에서 우리의 DeiT는 6.3% 더 높은 정확도를 보인다. (DeiT-B ⚗/1000 epochs = 84.2, fine-tuning X)
- ⚗ 표시가 붙은 Distillation 방법론을 사용한 모델은 Teacher Model의 Accuracy 및 Throughput을 능가한다.
- ViT-B best accuracy vs DeiT-B↑⚗ / 1000 epochs ⇒ (84.15% vs 85.2%)
- DeiT-H ↑⚗ / 1000 epochs = 88.55%

6. Training details & ablation


- Augmentation 우측 표 참조. Rand-Aug, Mixup, Cutmix, Erasing prob 사용.
- EMA사용! λ = 0.1, 따라서 학습이 끝나면, Teacher와 Student 모두 성능이 비슷해짐.
7. Conclusion
1. 이 논문에서는 Data efficient Image transformer - DeiT를 소개.
2. 이는 개선된 학습 방법(Hard Distillation token, Augmentation)과 특히 새로운 distillation method 영향이 크다.
3. CNN은 거의 10년 동안 아키텍처와 Optimization측면에서 최적화되었다. (Bag of trick)
4. EfficientNets와 같은 경우처럼 광범위한 아키텍처 검색은 Overfitting 위험성이 큼.
5. DeiT에서는 CNN에 대한 Augmentation 및 regularization 전략을 시작으로, 새로운 distillation 토큰을 제외하고는 모델의 구조적인 변화를 도입하지 X
6. Transformer에 대한 더 효율적이고 적합한 모델에 대한 연구나, Augmentation에 대한 연구가 기대될 것 같다. 결과를 고려하였을 때, Transformer는 이미 CNN과 동등한 수준이므로, 주어진 Accuracy 및 더 낮은 메모리 사용량을 감안할 때, Transformer의 발전 가능성이 무궁무진하다.



