FlexiViT 논문을 오타와 대학과의 저널 클럽에서 발표하기 전 미리 자세하게 포스팅을 해보는 시간을 가져보려고 한다. 지난 6월달에 열린 CVPR2023때문에 요즘 전부 CVPR2023 논문만 발표를 하고 있어서, 나는 아직 학부생이지만.. 열심히 따라가보려고 한다.. 후
논문 제목: FlexiViT: One Model for All Patch Size.
저자: Lucas Beyer at al.
소속: Google Research
인용: 14 (2023.08.05 기준)
링크: https://arxiv.org/abs/2212.08013
학회: CVPR 2023
코드: https://github.com/google-research/big_vision

Baseline.
Q1. 왜 FlexiViT인가요?
A1-1. 다양한 크기의 패치로 자를 수 있기 때문이에여
A1-2. flexibility한 backbone이 강력한 효과를 보여주기 때문이다. 심지어 고정된 크기의 patch-size를 통해 fine-tuning을 해도 성능이 여전히 좋다.
Abstract.
- ViT는 이미지를 patch단위로 잘라서 sequence로 만든다. 이러한 patch들은 speed와 accuracy간의 trade-off가 존재하는데, 작은 패치를 사용할 경우 더 좋은 Accuracy를 얻지만 높은 computational cost를 지불해야한다는 단점이 있다.
+ ViT의 저자도 이러한 이유로 related work에서 4x4의 작은 패치를 사용한 아이디어에서 수정된 32x32, 16x16, 14x14 크기 패치를 사용했다
- 따라서 fine-tuning 단게에서 patch size를 바꾸는 것은 retraining을 요구한다는 단점이 존재
- 본 논문에서는 학습 단계에서 Randomizing patch-size를 하는데, 이는 좋은 성능을 가지는 모델을 만들어 낼 수 있게한다.
- 또한 이를 바탕으로 depolyment time에서 computing budget에 맞춰서 배포가 가능하다. (Edge-device에서의 활용 가능)
- Classification, image-text retrieval, openworld detection, panoptic or semantic segmenataion 등 다양한 task에서 backbone 모델으로 유용하게 사용가능


- 왼쪽 그림의 original ViT는 고정된 크기의 패치로 잘리게 되지만, FlexiViT는 자유 자재로 자르면서 학습을 진행한다.
Training Process.
1. patch size를 random하게해서 학습을 진행
2. Positional and patch embedding paramter를 패치 사이즈게 맞게 resize를 해준다.
3. 이러한 과정은 이미 좋은 성능을 낸다고 검증이 완료되었기에, 1. 최적화된 resize 과정, 2. Knowledge distillation을 통해 더 좋은 성능을 내는 모습을 보여주었다.
1. Introduction.
- "Patchification": ViT에서 이미지를 non-overlapping하게 Patch 단위로 짜른 후, Embedding 과정에서 Positional Encoding과 같은 위치 정보를 더해 Token이 되는 과정이다.
- 이러한 Patchification은 기존의 small local filter를 중첩시켜서 만드는 CNN 방식과 비교하면 큰 변화를 보여주었으며, 아래와 같은 방법을 통해 간단한 Patchification을 통해 새로운 방법론을 제시하는 논문도 있었다.
1. dropping of image patch token : MAE [설명 보러가기] , DynamicViT, A-ViT ect.
2. adding specialized token for new task: DeiT, CaiT
3. mixing image tokens with tokens from other modalities.
- 위의 Patchification 방식이 주목을 받았지만 간단한 Patch-size 수정은 주목을 받지 못했다고 말하며 Patch size의 조절으로 모델의 parametrization을 바꾸지 않으면서 간단하고 효과적인 모델을 만들 수 있다고 주장한다.
- 또한 기존의 ViT는 고정된 파라미터 patch-size에 대해서만 훈련이 가능하기에, patch-size를 바꾸는 과정은 재학습 필요
- 이러한 문제를 해결하기 위해 다양한 patch-size를 사용하며 추가적인 cost 없이 기존의 ViT를 능가하는 FlexiViT 제안.
- explosion 문제를 피하기 위해 Data Augmentation은 조사하지 않음. 이 논문의 목표는 여러 패치 사이즈에 대해 flexibility한 단일 모델을 만드는 것.
2. Related work.
- 아래의 관련 논문 참고
3. Making ViT flexible
- Dataset: ImageNet-21k
- Model : ViT-B
- Augmentation: unregularized light2 setting from How to train your ViT?
- Mixup = 0.2 and magnitude 10 of RandAugment
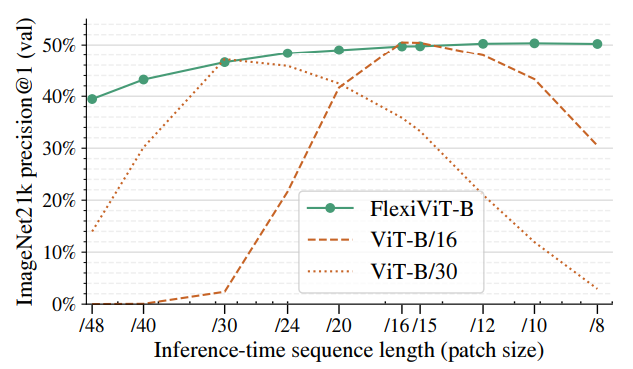
- Inference time에서 sequence length를 조절해가며 ViT-B 모델을 바탕으로 성능 실험을 하였을 때, FlexiViT는 어떤 Patch-size에서도 좋은 성능을 내는 모습을 볼 수 있다.
3-1. Background and notation.


- ViT paper를 읽고 정리를 안해뒀는데, 그 외의 Noation은 ViT 논문으로 정리된 걸 참조하는 것이 더 편할 것 같다. 나중에..
- 그리고 여기서 중요한 점은 patch size가 달라짐에 따라 모델의 파라미터가 바뀌는 부분은 patch embedding weight wk와 positional embedding π 이다. FlexiViT에서는 패치 사이즈가 달라져도 효과적으로 둘을 동시에 처리할 수 있게 만들었다.
3.2. Standard ViTs are not flexible
- 위의 Figure 3에 대한 내용이다. standard ViT는 Figure 3처럼 training time에 쓰인 Patch size에서만 좋은 성능을 보인다.
- 특히 Positoinal Encoding 파라미터 π는 기존 ViT에서도 fine-tuning단계에서 해상도를 높이는데 사용되었었음.
- 어찌됐던, 기존의 방식과 매우 유사하게 학습을 진행했으나, FlexiViT는 모든 패치 사이즈에서 좋았다라는 말씀.
3.3. Training flexible ViTs
- 기존과 차이점은 랜덤한 positional embedding weight 및 patch embedding weight 사이즈를 고르는 과정 정도..?

- 구체적인 설명을 붙이자면, 입력 이미지는 240x240이기에, patch-size는 1부터 240까지 가능하지만, 학습 시 8 ~ 48 사용
- 3번줄에서 볼 수 있듯이, uniform distribution한 Patch size 선택을 거친다.
- Patchification 동작을 위해 들어가는 weight와 Positional encoding weight는 모두 Bilinear Interpolation을 진행.
- 32x32와, 7x7을 고른 이유는, Appendix에서 설명하지만, 초기 설정 파라미터가 그렇게 큰 차이를 보이지 않았기 때문.
3.4. How to resize patch embeddings
- 이제 Resize에 대한 부분을 조금 더 알아보자. 필자도 논문을 읽으며 아무렇게나 resize해도 되나..? 이생각이 들었다.
- 그래서 저자도 이런 부분에 대해 section을 따로 마련했는데, 주요 내용은 다음과 같다.
1. embedding 전 Normalize 방법.

1. 위와 같이 패치 사이즈를 2배로 resize 해야하는 상황이 오면, bilinear interpolation 과정에서 patch value와 weight는 4배로 늘어나, dot product 연산은 4배로 늘어난 token value(norm) 이 나오며, 이는 inflexibility 한 Model을 만들게 될 것이라는 설명이다. [Patch embedding을 Conv를 사용하여 진행할 시에 나오는 문제이다.]
2. 따라서 이러한 문제를 해결하기 위해 쉽게 설명하자면, 패치 사이즈 2배 증가는 4배의 큰 토큰이 생기므로, 1/4를 해준다그리고 더 나아가 patch value가 늘어나면 늘어난 만큼, 줄어들면 줄어든 만큼 반영한다.
++ 이런 정보를 반영하기 위해 위에서 non-negative value만 처리한다는 가정을 한다.
2. PI-resize method.
- 위의 방법을 포함하여, embedding 전 normalize, LayerNorm을 추가할 수 있지만, 이는 원본 ViT 구조와의 차이가 생긴다. 성능또한 LayerNorm이 가장 우수하지만, 원래 모델을 변형시키지 않으면서, 그 다음으로 우수한 bilinear-interpolation + PI-resize 방식을 사용하였다. (아래 참조)


- 위의 resize function은 다음과 같다. p를 p*로 바꿔주는 Resize 행렬 B를 사용하고 이는 bilinear interpolation 이며,
- 우리의 patch-embedding weight을 구하기 위한 optimization problem이 아래와 같다는 정도만 확인하면 될 것 같다.

- Figure 4를 보면, PI-resize를 사용하여 높은 해상도로 바꾸어도 손실 없이 Resize를 할 수 있다는 것을 보여주는데, 평가지표로 precision을 사용하였다. 높은 해상도로 변환한다는 것은 더 많은 정보를 포함한다는 것을 의미하고, 잘못된 resize로 인한 해상도 상승은 그저 블러링된 이미지만 만들어 내는 과정으로 이어져 False-Positive인 잘못된 예측을 만들어 낼 것이라 생각하기에 저자가 Precision을 사용하지 않았을까 하는 개인적인 생각이다.

- 또한 PI-resize를 하기 위해 여러 수식을 붙이면서 pseudo-inverse matrix를 사용한 이유를 설명하는데, 그냥 행렬 B가 애초에 정방행렬이 아니라 기존의 역행렬이 사용이 불가능해서 위의 수식을 만족시키기 위해 pseudo-inverse matrix를 사용한다고 보면 될 것 같다.
- 물론 (B^T)+ 를 풀면 B(B^T B)-1 이 되며, 논문의 수식들과 일치한다.
3.5. Connection to knowledge distillation
- 또한 저자는 Knowledge Distillation (KD)을 적용하였는데, 위에 그림에서 볼 수 있듯이 동일한 크기의 모델을 사용했다.
- 대부분 KD는 큰 teacher model과 작은 student 모델을 사용하였는데, FlexiViT는 같은 모델이므로, 기존의 KD 방법론들이 겪던 optimization problem을 같은 weight로 초기화 해주는 방식을 사용해 이를 해결했다.
- teacher model의 weight는 ViT-B/8 을 How to train your ViT 논문에서 가져왔고 (아마 저자가 같아서...) 이 weight를 32x32의 PI-resize에 해당하는 weight로, patch embedding또한 7x7으로 reshape하였다.
- 그 후 training방식은 student 모델은 patch size를 조절하며 FunMatch 방식의 KD를 통해 진행하였다.
- KL Divergence loss는 아래와 같다. teacher model ViT-B 8이 주어졌을 때의 student FlexiViT의 확률 값이 되겠다.

- 그림을 정말.. 후.. 이상하게 그린 Figure 5이다. Random init의 경우 distillation을 하지 않는 것과 비슷한 성능을 보이며, ViT-B/8의 weight를 똑같이 복사해서 사용했을 때, 성능이 더 제일 좋았다.
- 우측 그림은 Figure 6인데, 작은 동그라미가 grid size = 5 부터, 큰 동그라미 30까지 주로 layer끼리 비슷한 표현을 보인다.


4. Using pre-trained FlexiViTs

-- 전체적으로 좋은 성능을 다양한 task 에서 보인다.


- 다양한 패치 위치에서의 representation도 유사하며, TPU core Hour에 따른 IN-21k 의 precision은 비슷한 성능에서의 TPU core Hours는 더 적게 걸리는 모습을 보여준다.
Conclusion
- Dynamic patch라는 아이디어는 간단하지만 효율적인 경량화 기법임을 보여주었다. 하지만 논문에서 accuracy가 매우 비슷하기에 precision을 주요 평가 지표로 사용했다는 점이 찝찝하게 만든다. 그래도 학습 중 patch size를 바꾸는 점과 PI-resize를 수행하는 부분은 매우 효율적으로 resize를 진행하였다고 생각한다.
관련 논문 및 간단한 설명.
1. MAE [블로그 설명 보러가기]:
- 논문의 목표: 원본 이미지를 패치 단위로 나누어 masking 후, 최대한 비슷하게 복구하는 것.
- 입력 이미지를 패치 단위로 자른 후, 75%의 비율로 랜덤 mask 진행. 그 후 unmasked 된 부분만 모델의 입력으로 투입
- encoder 통과 후, decoder에서는 다시 masked 된 패치와 unmasked 패치가 합쳐져서 원본 이미지 복구 진행.
논문 읽기 : Masked Autoencoders Are Scalable Vision Learners
논문 링크 : https://arxiv.org/abs/2111.06377 저자 : Kamming He 인용 : 2170 (2023.06.22) 소속 : FaceBookAI Research (MetaAI) 학회 : CVPR2022 Summarize - 아래의 왼쪽 이미지가 이 논문의 처음이자 끝이다. 이미지를 일정한
187cm.tistory.com
2. Auto-scaling Vision Transformers without Training [링크]
- 1번의 MAE와 다르게, structed 된 기준으로 token을 제거하였다.
3. DynamicViT [링크] or A-ViT [링크]
- 학습 중 token의 중요도를 계산하여 덜 중요한 token 제거.
4. Patch Slimming for Efficient Vision Transformers [링크]
- 위의 3번 방식과 다르게, 학습이 끝난 후, 덜 중요한 token 제거.
5. Not All Images are Worth 16x16 Words: Dynamic Transformers for Efficient Image Recognition [링크]
- 위의 방식(1,2,3,4)와 다르게 토큰 수를 늘린 후, 모델의 학습을 일찍 끝내버리는 방식 사용.
6. Swin-Transformerv2 [링크], EfficientNetV2 [링크], DeiT-||| [링크]
- 학습 도중 입력 이미지의 해상도를 바꿔서 속도를 올린다. 하지만 우리의 FlexiViT는 패치 사이즈를 다르게 한다.
7. SuperViT: Super Vision Transformer [링크]
- FlexiViT와 가장 유사한 paper로 소개됨. Neural Architecture Search(NAS) 분야의 논문.
8. How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers [링크]
- 이 논문의 1저자인 Lucas Beyer가 교신저자로 들어간 논문. ViT에 Training에 대해 적은 논문이라고 보면 될 것 같다.



