Original DeiT에 이어 DeiT III를 리뷰해보려고 한다. MMCV에 올라온 Figure를 보고 DeiT III를 읽어야겠다 다짐했는데, DeiT III를 BootMAE로 잘못 올려뒀다. (매우 화가난다) DeiT III는 실제로도 별 내용이 없기에 간단하게 리뷰해보려고 한다. DeiT에서 등장한 aggrasive한 augmentation 기법에을 바탕으로 self-supervised learning과, Supervised learning의 ImageNet 정확도가 왔다갔다 하는 상황에서, 기본적인 ViT만으로도 DeiT와 유사한 Augmentaiton, 더욱 강한 augmentation을 적용한다고 보면 될 것 같다.
저자 : Hugo Touvron
소속 : MetaAI, Sorbonne University
학회 : ECCV2022
인용 : 141 (2023.10.14 기준)
링크 : https://arxiv.org/pdf/2204.07118.pdf
The Author make a start to mention that ViT shown amenable result in Computer Vision task. However they have a limited architectural priors such as spatial information and translation invarient. Recent work try to incorporate their priors, input data or specific tasks, and Self-supervised method [BeiT]
These self-supervised learning method are shown the superior result than supervised learning manner. [BeiT], [MAE] However, in this paper, we proposed new data-efficient pre-training method using original ViT based on the DeiT augmentation method, which can solve the huge training training data problem in ViT. DeiT III can surpass agian to the self-supervised learning method without knowledge distillation. That's the reason of our paper titled "Revenge of the ViT"
1. Introduction
- Original CNN architecture have a built-in "translation invariance" properties, providing a foundational approach towards understanding and interpretnig visual data.
- Numerous attempts have been made to supplment or create alternatives for the original ViT priors, showcasing not only faster convergence compared to original CNN models but also superior performance when juxtaposed with both CNNs and Data-efficient Image Transformers (DeiT).
- Despite the monumental success of ViT, the prevailing focus on accuracy has somewhat overshadowed pursuits to enhance efficiency, thereby leaving a gap in the related work in this specific context. Moreover, a lingering question remains unresolved: when a hybrid model architecture - which combines convolutional layers and ViT architecture - is proposed, is its efficacy attributed to the optimization assistance from the convolutional layer or the attention-based architectural design?
- In this paper, we'll talk about "renewing the training procedure for vanilla ViT architectures", drawing inspiration and cues from BERT-like pre-training methods.

- Significant modifications, as compared to the original Vision Transformer (ViT), are delineated in the table above.
- The authors articulate three pivotal alterations: [1. RRC or SRC, 2. 3 Augment, 3. A lower resolution at training time.]
Moreover, we employ the Binary Cross Entropy loss in the ImageNet-1k dataset.
2. Method.
- The 3augment method is adopted in this approach. As we acknowledged in the previous review, original DeiT utilize the strong augmentation to overcome arising from the smaller dataset problem. However, in DeiT III, we implement a stronger augmentation setting. This is pivotal since the augmentation method, like RandAugment, is derived from the CNN architectures. Thus, we must further investigate which augmentation method is correct and how it is implemented
- 3-augment makes a new paradigm in ViT's training. We select one from among (grayscale, Gaussian blur, solarization) and employ the color jitter method.


- Additionally, we employ the SRC (Simple Random Cropping) method to diminish overfitting issues in the ImageNet-21k dataset, while maintaining the RRC (Random Resize Cropping) method for the ImageNet-1k dataset.
- The primary distinction between the two learning processes lies in their resize and cropping sequence. RRC, a widely used method, operates by initially cropping images randomly and subsequently enlarging/downscaling them when utilizing the RandomResizeCrop function in torchvision. Conversely, SRC follows a reversed sequence, first resizing and then performing random cropping.
- While RRC is considered a more aggressive augmentation method, our examination of the IN-21k dataset indicates that such aggressive augmentation can cause unstable training and potentially introduce noise into the model.


- Last, we utilize the low resolution in the training time. when we utilize the 128x128 size resolution image, we can reduce the memory about close to 80%
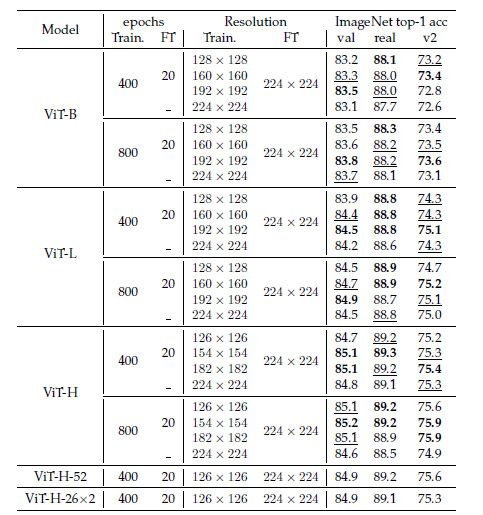
Result.




