1. Non-local Neural Networks

제목 : Non-local Neural Networks
저자 : Xiaolong Wang , Kamming He et al
소속 : Carnegie Mellon University & Facebook AI Research
학회 : CVPR2018
인용 : 9010 (2023.09.24 기준)
링크 : https://arxiv.org/abs/1711.07971v3
Abstract 요약: Video Processing에서 전통적인 CNN + RNN 조합 대신 "non-local block"을 제시하여 긴 범위의 의존성을 포착 가능. Non-local block은 모든 위치의 특징(Time, Height, Weight)의 가중치 합으로 계산. 이 방법은 다양한 작업에 적용될 수 있으며, 비디오 분류와 이미지 인식 작업에서 탁월한 성능을 보여줌.
Goal: Long Range dependency를 포착하기 위한 새로운 non-local block을 제시.
Conclusion: Non-local block은 video processing, object detection, segmentation, pose estimation등 다양한 작업에서 우수한 성능을 보여주며, 이 block만 따로 떼서 사용할 수도 있다.
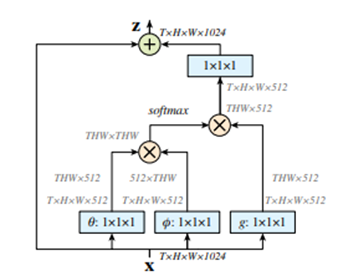
Method: 1x1x1 Conv filter를 사용하여 정보를 압축한 후 Scaled dot Product 연산과 유사하게 행렬 곱 연산을 Time, Height, Weight에 대해서 수행한 후, Softmax() 함수를 사용하여 확률 값을 얻은 후에 다시 원래 X에 elementwise 연산을 진행하여 원래 X에 확률 값을 넣는 Self Attention과 유사한 non-local block을 도입.
Problem: 전통적인 CNN과 RNN은 localized된 정보만을 처리하기 때문에 Long Range dependency을 제대로 포착하지 못한다.
Main Idea – Video Processing에서 Self-attention을 사용하여 프레임간의 연관성을 확인.
저자는 video processing에서 long time dependency를 잡을 수 있는 non-local network block을 제시. 또한 1x1x1 연산을 사용하기에 Cost가 크지 않아 baseline network에 추가하면 적은 Cost로 유의미한 성능 향상을 얻을 수 있다고 소개.
2. SENet(Squeeze and Excitation Network)
제목 : Squeeze-and-Excitation Networks
저자 : Jie Hu et al.
학회 : CVPR2018
인용 : 24480 (2023.09.24 기준)
링크 : https://arxiv.org/abs/1709.01507
Abstract 요약: SENet은 채널 간의 관계에 중점을 둔 Squeeze-and-Excitation (SE) 블록을 소개. 이 블록은 Channel-Attention을 명시적으로 모델링하여 채널별 특징 반응을 다시 조정. SE 블록을 여러 개 쌓아서 구성된 SENet은 다양한 데이터셋에서 잘 일반화되며, 최소한의 추가 계산 비용으로 성능을 크게 향상. SENet은 ILSVRC 2017 분류 대회에서 우승하며, 2016년 우승작보다 약 25%의 상대적 개선을 보임.
Goal: CNN에서 채널 간의 관계를 강화하여(Channel Attention) 모델의 Representation을 향상시키기 위한 새로운 Squeeze-and-Excitation (SE) 블록을 소개하고, 그것을 기반으로 한 SENet 아키텍처를 개발.
Conclusion: SENet은 최소한의 추가 계산 비용으로 성능을 크게 향상시킬 수 있다. 이는 ILSVRC 2017에서의 우승과 같은 성과를 통해 입증.
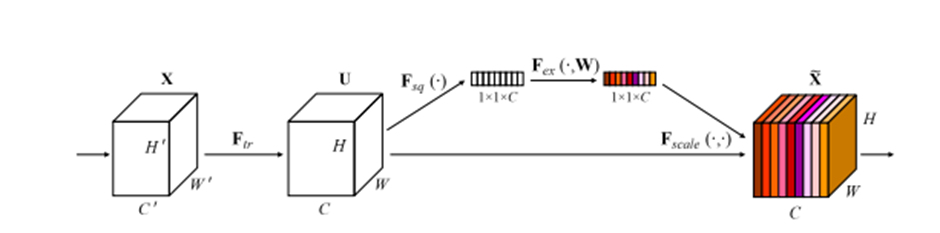
Method: Squeeze-and-Excitation (SE) 블록은 채널 간의 의존성을 명시적으로 모델링하여 채널별 반응을 재보정하는 방식을 사용. 이러한 SE 블록을 여러 개 쌓아서 SENet 아키텍처를 구성.
Squeeze연산 - Image를 GAP를 통해 1x1xC 형태로 압축 후, 1x1 Conv filter를 사용하여 채널 기준으로 압축을 진행
Excitation연산 - Vector 보정(Recalibration)을 fully connected layer를 이용하여 수행합니다.
이 과정에서 Vector를 줄이고 늘려서 원래 channel 수와 동일하게 만들어준다. 그 다음 원래 이미지에 채널 별로 값을 곱해주어 채널마다 중요도를 가지게 만들어줍니다. 압축 비율은 16배.
Problem: 기존의 CNN은 receptive field 내에서 spatial 및 channel 정보를 통합하여 유익한 특징(semantic information)을 추출하는데 중점을 둡니다. 그러나 이러한 접근법은 채널 간의 복잡한 관계와 상호 작용을 충분히 고려하지 않을 수 있다.
++ 이 Channel Attention이 왜 좋은지 내 짤막한 지식으로 설명하자면, Channel 정보는 색상을 조합하는데 쓰이기에 이 색상 정보를 바탕으로 물체의 식별/구분에 기여 가능하다. 그리고 CNN에서 layer가 깊어질수록 channel은 더 많아지며 다양한 representation을 의미하는데, 이 representation 간의 중요도를 파악하여 물체 식별/인식/구분 하는데 이점을 준다.
+++ GAP가 또 중요한 역할을 수행할 수 있는데, GAP는 하나의 스칼라 값으로 정보를 요약하지만, 이는 이미지의 전체적인 정보를 요약한 것이기에, 다른 물체끼리의 연관성도 어느 정도 확인할 수 있다. 이게 무슨 말이냐면, 자동차가 달리는 이미지가 있다고 하면 채널별로 바퀴, 차체, 배경 등이 색상에 의해 구분이 될 것이며, 유의미한 상관관계가 있는 바퀴, 차체의 채널 연관성을 높을 것 이기에 이러한 과정에서 GAP가 유의미한 차이를 제공할 수 있다는 것이다.
3. On the Relationship between Self-Attention and Convolutional Layers.
제목 : On the Relationship between Self-Attention and Convolutional Layers.
저자 : Jean-Baptiste Cordonnier et al.
학회 : ICLR2020
인용 : 489 (2023.09.24 기준)
링크 : https://arxiv.org/abs/1911.03584
Main Idea – 앞서 소개한 논문 중에서 가장 Vision Transformer와 유사한 구조. 우선 이 논문의 특징은 이미지를 2x2 크기의 패치 단위로 잘라서 패치들 간의 연관성을 학습. 패치들의 상대적인 위치를 바탕으로 Self-attention 연산을 수행. 또한 이 Attention layer가 Convolution layer를 대체할 수 있다는 것을 보여준다. 하지만 2x2 단위로 이미지를 쪼갰기 때문에 연산 비용이 많이 든다는 점에서 이미지의 크기가 작은 경우만 가능하다는 제한이 있다. 그럼에도 충분한 수의 Multi-Head Attention layer는 Convolution layer만큼 효과가 있다는 것을 보였으며, 2x2 단위의 Self-Attention layer는 pixel-grid pattern을 따르며 학습이 된다는 것을 시각적으로 보여주었다.
