이전 강의 요약 - XCS224U: NLU I Intro & Evolution of Natural Language Understanding, Part. 1 I Spring 2023
이전 강의 요약 - XCS224U: NLU I Course Overview, Part. 2 I Spring 2023
이전 강의 요약 - XCS224U: NLU I Contextual Word Representations, Part. 1: Guiding ideas I Spring 2023
이전 강의 요약 - XCS224U: NLU I Contextual Word Representations, Part. 2: The Transformer I Spring 2023
이전 강의 요약 - XCS224U: NLU I Contextual Word Representations, Part. 3: Positional Encoding I Spring 2023
강의영상 : https://www.youtube.com/watch?v=yqV_YfBBtK0&list=PLoROMvodv4rOwvldxftJTmoR3kRcWkJBp&index=7
강의자료 : https://web.stanford.edu/class/cs224u/slides/cs224u-contextualreps-2023-handout.pdf - GPT


이번 시간에는 ChatGPT의 GPT로, 요즘 너무 유명해진 GPT에 대해서 알아보자. 교수님께서는 Transformer-base architecture 중 가장 유명하다고 하시는데, 초기엔 BERT가 더 유명했으나, 지금은 GPT가 더 유명하단 말이 맞는 것 같다.
GPT: AutoRegressive Loss fuction
- 가장 먼저 봐야 할 부분은 NLP에서 종종 쓰이는 AutoRegressive Loss fuction이다. 주어진 token sequence x1, x2, ... x_{t-1} 을 기반으로 다음 토큰 x_t 를 예측한다.
- Position T에 대해, embedding layer에 대한 token의 representation은 e(X_t) 이다.
- 그리고 현재 time step t에 대해 초점을 두고 이전까지의 hidden representation과 dot-product 연산을 수행한다.
- 분모는 softmax normalization과 유사하게, 모든 토큰 x'에 대해서 logit score의 exponential 합을 취한 후, 이 값에 대해 가장 큰 값을 가지는 \theta를 구한다.
- 하지만 가장 중요한 점은 scoring이 dot-product 연산으로 이루어져있다는 것이다. 현재 time step에 대한 token embedding representation(우리가 예측하고 싶은 현재 시점의 토큰)과 이전까지 우리가 만들어온 Hidden representation의 time step 까지의 vector이다.
- Objective Function: 주어진 수식은 cross-entropy loss를 최대화하는 방식으로 파라미터 θ를 학습시키기 위한 objective function을 나타냄. 모델은 각 시점에서 실제 토큰의 로그 확률의 합을 최대화 시키려고 한다.

Conditional Language Modeling
- 그렇다면 예시를 통해서 Conditional Language Modeling을 파악해보자. 가장 먼저 입력 문장 The Rock rules라는 문장에 대해 start/end 토큰을 추가하여 x = [<s>, The, Rock, rules, </s>] 라고 정의를 하자.
- 그렇다면 t1, .., t4는 각각의 time step을 의미하게 된다.
- 분홍색 block은 모든 단어에 start/end token 단위로 쪼개고 입력으로 들어간다.
- 회색은 각 token에 해당하는 embedding representation이 회색 block이 된다. 노란색은 hidden representation이 된다.
- 파란색은 이 첫번째 time step에 대한 예측하고자 하는 output이 된다.
- 그리고 중요한 것. 이제 우리가 위에서 본 수식을 적용하게 되면, time step 2에 대해서, 위에서 본 Autoregressive 수식을 통해 dot-product 연산을 수행하게 된다.
- 우리가 예측하고자 하는 time step = t2이므로 e(x_t2) 가 될 것이며, hidden representation은 h1만 들어갈 것이다. 그리고 분모는 the에 대한 Normalized 된 확률이 나올 것이다. -> h1과 다른 모든 v들과 dot-product 연산을 진행하니까.
- 따라서 Rock에 대한 예측 확률은 x30과 h2를 dot-product를 한 것과 같게 되는데, 우리의 h2는 rock을 만들기 위해 가장 높은 확률을 가지게끔 만들어졌으며, 그리고 이 확률을 구하기 위해 rock에 대한 embedding vector를 가지고 dot-product를 하면, 이는 Rock에 대한 확률과 같아진다.


GPT
- 전통적인 Absolute positional encoding 방식을 바탕으로 기존의 Transformer 모델과 똑같은 방식의 학습을 진행한다.- 그리고 전통적인 Transformer 모델의 출력이 진한 녹색 block들이라면, 우리는 이제 여기에다가 하늘색의 embedding layer를 추가한다. 그리고 이 embedding layer를 바탕으로 실제 단어에 대한 예측을 수행한다.- 하지만 이것은 단지, Conditional Language Modeling에 embedding layer만을 추가한 것과 다를바가 없다. 실제로 Transformer는 그냥 모델 중 하나로 봐도 다른 점을 알기가 힘들다.

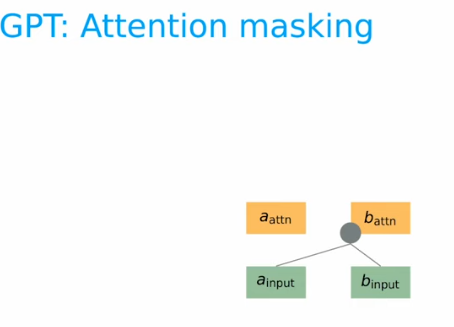

GPT: Attention Masking
- 그리고 우리의 Transformer모델은 예측시, 문장을 한번에 뱉는 것이 아닌, 단어 하나씩 들어가서 하나씩 나오기에 Attention mechanism에서 Masking 작업을 필요로 한다. (근데 이건 Transformer에도 있는거 아닌가..)
- 물론 지금까지의 conditional language modeling 작업은 마찬가지로 미래를 볼 수 없기에 이런 작업이 필연적이다.
어쨌든 설명을 하자면, a_input만 들어왔을 경우에 우리가 볼수있는것은 없다. 따라서 그냥 a_attn 이 출력된다. 그리고 b_input이 들어오면, 현재의 예측하고자 하는 b_attn을 위해서 a_input과 b_input을 사용할 수 있다.
- 마지막으로, c_attn을 위해서는 기존의 우리가 사용했던 a,b,c를 모두 사용할 수 있기에, 위의 3개의 그림이 순차적으로 진행이 된다는 것을 알 수 있다


GPT: Training with teacher forcing
- GPT 계열 모델의 특별한 점은 이 Training with teacher forcing이라는 것인데, 이것은 우리가 어떤 위치에 있는 time step t를 예측하더라도, t+1 시점의 입력으로 정답을 이용할 수 있다는 것이다.
ex) 나는 고양이를 좋아한다. 그리고 ..ect (정답) -> 우리의 예측: 나는 사과를 ... 이 되면, 그 뒤에는 모두 틀린 정보가 들어가게 되기에, 사과를 이란 틀린 정보가 들어가도, 그냥 나는 고양이를 으로 그 다음 t+1 step이 진행된다는 것이다.
- 그림 설명을 진행하면, 입력 vector가 one-hot으로 들어갈 때, 위에서 설명한 masking 방법이 적용되게 된 그림은 위와 같다.
- 이 Transformer의 출력에 embedding layer를 적용하고 이 출력과 가장 가까운 단어들을 뽑아내서 우리의 출력 문장을 완성시킬 수 있다. [Teacher forcing에 대한 설명은 아래에서 계속]
++ BOS는 Begining of Sequence로 시작 토큰이라는 뜻이다


- 위에 이미지에 이어서 teacher forcing이란 개념은 위에서 빨갛게 칠해진 부분과 같이, 우리의 predict vector의 argmax값이 잘못되었을 때, 원래 우리의 모델은 이 부분부터 잘못된 출력값을 내보내게 된다. 하지만, Teacher forcing은 앞에서 보여준 것 처럼, 잘못된 예측을 해도 그 다음 입력으로 정답이 들어가게 된다.
- 그 옆에 Generation 부분은 틀린 에측을 했을 때의 결과를 보여준다. 여기서 Teacher forcing이 사용되지 않으면 The rock rolls along이라는 틀린 문장을 출력하게 된다.
- 또한 우리는 이 Teacher forcing을 사용하게 됨으로써, 단어를 예측하는 것이 아닌, scoring을 하는 것에 초점을 둘 수 있다. 어짜피 우리는 정답을 가져다가 쓸 것이기 때문에, 가장 scoring을 각 step에서 잘 하게끔 만든다고 해석할 수 있다.



- 우리의 GPT는 final_output을 만들어 낼 때, 다음과 같이 Classification에도 사용될 수 있고, 여러개의 output을 Global pooling을 통해 나온 값으로 downstream task에 적용 할 수 있다. 또한 기존의 task와 유사한 task에 사용할 수도 있다.


- 마지막으로 모델의 사이즈 변화이다. 1세대 GPT는 우리가 아는 일반적인 Transformer의 parameter를 따라간다고 볼 수 있다. 하지만, 2, 3세대 부터는 layer 및 dk 수가 급격하게 늘어나는 것을 볼 수 있다.
- GPT-2는 1.5 bilillon 으로 매우 큰 수의 parameter를 가진다. GPT-3은 175 billion parameter로 진짜 많다.
- GPT-3세대의 d_ff는 약 12000정도이다. 하지만 정확하게 알 순 없다.
- 그리고 오른쪽 이미지는 Open source로 공개된 모델 중, 교수님이 아시는 방법론이다.



