이전 강의 요약 - XCS224U: NLU I Intro & Evolution of Natural Language Understanding, Pt. 1 I Spring 2023
이전 강의 요약 - XCS224U: NLU I Course Overview, Pt. 2 I Spring 2023
강의영상 : https://www.youtube.com/watch?v=J52Dtu40esQ&list=PLoROMvodv4rOwvldxftJTmoR3kRcWkJBp&index=2
강의영상 https://www.youtube.com/watch?v=FEFeeRONEdw&list=PLoROMvodv4rOwvldxftJTmoR3kRcWkJBp&index=4
강의자료 : https://web.stanford.edu/class/cs224u/slides/cs224u-contextualreps-2023-handout.pdf
요약에 앞서, 기존 2-1의 후반부 내용은 뒤에 20분씩 끊어서 올리신 내용과 똑같기에 그냥 PASS 했다. 따라서 지금부터는 20분짜리 강의를 요약했다고 봐도 될 것 같다.
Contextual Word Representations
Guiding ideas


- 이번 강의에서는 언어학자이신 Potts 교수님께서 보시는 word representation - context representation에 대해서 알아보자
- 우선 이 둘 사이에는 상당한 연관성이 있으시다고 하셨다. 자세한 설명은 아래에서 이어서 하겠다.


1. Feature-based : 아주 오래전, feature-based 라는 모델이 있었는데 이 모델은 feature function을 가지고 있다. yes or no를 -ing로 끝나는 단어에 대해, 혹은 동사인지 아닌지에 대해 등등 해서 여러가지 1, 0으로 구성된 여러 vector로 표현된 representation을 가지고 있다. 따라서 Sparse 한 vector를 가지고 있으며, classical lexical representation이라 불린다.
2. Count-based methods : Point wise Mutual information or TF-IDF 와 같은 방법론은 매우 기초적임. TF-IDF같은 경우에는 관련이 있는 문서를 query에서 찾아낸다. 또한 이 방법론은, co-occurrence패턴을 보고, 학습하며 count를 세고 weight를 조정한다.
3. Classical dimensionality reduction : PCA, SVD, LDA (Latent dirichlet allocation)은 count 된 데이터를 받아서 reduce dimenstion을 수행한다. → 이러한 과정을 통해 High compress된 co-occurrence 패턴을 얻게 된다. capture를 매우 잘함.
4. Learned dimensionality reduction : Autoencoder, Word2Vec, GloVe, 등이 있다
1. The vase broke, Dawn broke, The news broke .. ect 와 같은 문장은, 표면적으로 같으나, 뜻은 다르다. 즉, 주어지는 단어에 따라 뜻이 다르다. (동사 예시)
2. flat tire/beer/note/surface or throw a party/fight/ball/fit 등, 어떤 단어가 오는지에 따라 adjective 또한 뜻이 바뀐다
3. Crane 또한 새 혹은 기계로, 여러가지 뜻이 있는데, 그렇다면 I saw a crane이라는 문장에서 crane은 무슨 뜻일까?
→ 정답을 알기 위해선, 조금 더 긴 text나, 아니면 뒤에 남아있는 문장을 봐야한다.
4. Are there typos? I didn't see any // Are there bookstores downtown? I didn't see any. 이 문장에서도, I didn't see any라는 문장은 같지만 각각 가리키는 대상이 다르다.
- 위에서 볼 수 있듯이, 문장에서의 내용을 바탕으로 뜻이 조정된다. 고정된 표현은 제대로 된 학습을 가져오지 못할 것이기에, 따라서 이런 상황을 포용할 수 있게 모델을 짜야한다.
- 교수님의 시점에서, static vector representation 방법론은 절대 안될 것이라 생각했다. 왜냐하면, broke, flat 모두 뜻이 다르지만 하나의 vector로 mapping되기 때문이다. 하지만 우리의 단어들은, 주위의 단어에 따라 뜻이 달라질만큼 유연하게 변경될 수 있으며, 이러한 문맥적 뉘앙스를 포착하기 위해 Context word representation이 사용되며, 이를 통해 단어가 다양한 상황에서 어떻게 사용되는지 알 수 있다.

- 간단한 역사를 정리해둔 내용이다. 더욱 간략히 요약하자면
1. Dai and Le (2015) Language model style의 pre-training이 정의되었다.
2. McCann (2017) Pre-trained 된 bi-LSTM을 Machine Translation task에 적용
3. Peters (2018) ELMo가 큰 사이즈의 pre-training을 성공적으로 시키는 것을 보여주었다.
4. Radford (2018) GPT 1세대가 세상에 등장
5. Devlin (2019) 구글이 BERT를 등장시킴.
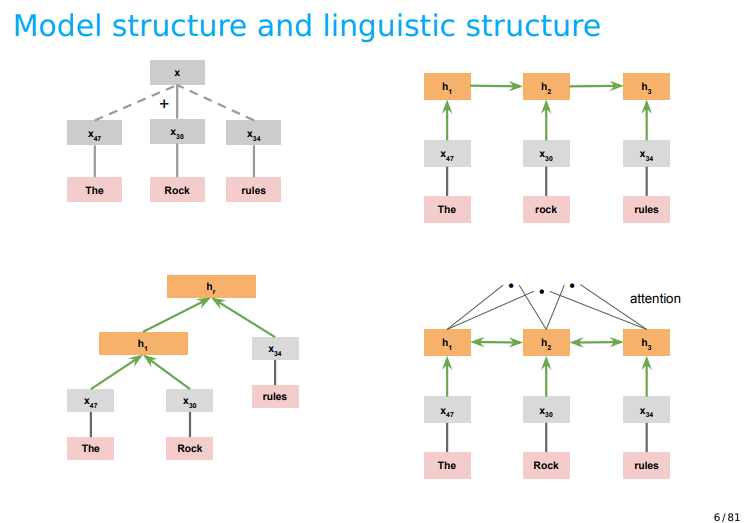
- 또한 이에 따른 모델의 구조를 시각화 했을 때, 다음과 같으며, 어떤 structual bias를 가지는지 알아보자.
1. 첫번째 모델은, GloVe, word2vec과 같은 모델에서 사용되었는데, addition에 의해 representation이 합쳐진다. 이 모델은 high-biased model이라고도 불리는데, ex) "king" - "man" + 'woman' = 'queen' 과 같이 이루어진다. 하지만, 어디까지나 approximate 된 수치일 뿐이며, 미리 이런 조합을 정해야하기에 high-biased model이라 불린다.
2. RNN 구조, 1번보다 적은 bias를 가짐, 하지만, 왼→ 오 방향의 단점으로 앞선 시간의 정보를 가져오고 싶다면 매우매우 앞으로 가야하는 단점이 존재한다
3. Tree 모양이다. 매우 훌륭한 구조이지만, 한번 틀리면 계속 틀릴 것. 그게 단점이며, high-biased이다. 그 이유는, 미리 이 tree를 구성하기 위한 constitude를 미리 구성해야하기 때문이다.
4. 4번은 Attention 모양. 여러개를 건너 뛸 수 있으며, 모든 연결을 공평하게 처리하기에, Bias가 없다.



- 그렇다면 이 bias가 없는 Attention이란 뭘까?
- 위의 왼쪽 그림을 예시로, hc를 그냥 쓰게 된다면 h1에 대한 정보를 매우 적게 가지게 될 것이다. 즉 RNN은 뒤쪽에 있는 hidden representation을 (h1, h2, h3)을 제대로 반영해주지 못하지만, 반대로 앞 쪽 정보는 많이 반영. high biased model!
- 따라서, 마지막 output이 이전 입력에 대해 생각해 볼 수 있게 하는 작업이 필요하다. 따라서, hc와 h1, h2, h3에 대한 곱을 가지고 connecting을 시도함 == dot product == Attention scores == Attention이 된다.
- 또한 이 Attention 방법론을 가지고 Transformer라는 모델을 제안한 논문인, Attention is All you need라는 제목이 다음과 같이 주어진 이유는 ⇒ lstm과 같은 게이트가 더이상 필요 없다. 그냥 이러한 Attention 연결을 계속 모델위에다가 더하고, 그러고 나면 모델 내부의 단어들이 서로 bias 없이 정보를 주고 받으며 효과적인 성능을 내기 때문이다.
- 또 한가지 유용한 방법론 중 하나는 ELMo이다.
- 이 ELMo의 특징은 character level representation인데, 여러개의 Conv filter를 가지고 Maxpooling을 하여 위와 같이 요약된다. 이러한 과정을 통해, subword의 정보를 파악한다는 것이다. 대략 100,000개의 단어를 사용하였다.
- Real world Problem에서 unseen 단어를 보게 될 것이고, 단어를 2,3배 늘려서 학습해도 여전히 같은 문제가 발생할 것.
- 하지만 여기서 중요한 것은 word piece tokenization인데, 이 작업을 수행하면 우측과 같이 나눌 수 있다.
- 이러한 방법론을 바탕으로 BERT에서는 30,000개의 embedding space를 사용했다. 매우 작은 크기!
- 더 나아가 Few shot learning을 LLM에 적용하는 것을 배울 예정.


- 그리고 또 다른 아이디어로는 Positional Encoding이 존재하는데, 이 방법론은 다음 강의인 Transformer에서 더 자세하게 다루기에 여기서 넘어가도록 하겠다.
- 이 Positional Encoding은 문장의 순서는 배우지 않는 Transformer에서 유일하게 Position정보를 바탕으로 이러한 정보를 넣어주며, 이는 문장의 순서를 알 수 있게 해주는 Transformer에서의 유일한 부분이자, 큰 장점을 보여준다.
- Fine-tuning은 너무 유명하니까 PASS



