이전 강의 요약 - XCS224U: NLU I Intro & Evolution of Natural Language Understanding, Part. 1 I Spring 2023
이전 강의 요약 - XCS224U: NLU I Course Overview, Part. 2 I Spring 2023
이전 강의 요약 - XCS224U: NLU I Contextual Word Representations, Part. 1 I Spring 2023
강의영상 : https://www.youtube.com/watch?v=yqV_YfBBtK0&list=PLoROMvodv4rOwvldxftJTmoR3kRcWkJBp&index=5
강의자료 : https://web.stanford.edu/class/cs224u/slides/cs224u-contextualreps-2023-handout.pdf


이번 강의 주제는 너무나도 유명한 Transformer 모델 구조이다. 논문 이름은 Attention All you need. 구글에서 발표한 논문으로 지난 강의에서도 살짝씩 다뤘었다. 이번 강의에서는 왜 Transformer가 좋은지, 뭐가 핵심인지에 대해 알아보자.
Conceptual understanding


- 왼쪽 부분은 static word representation로 변환되는 부분(Word2Vec, GloVe)과, Positional Encoding이 결합된 부분이다.
- 우측 부분은 word representation vector와 positional encoding을 결합한 부분이다. dimention wise 연산을 수행했다.
- 실제로 논문 그림을 보면, Input Embedding을 수행하고 난 이후의 차원은 [B, seq_len, d_k * head_num] , Positional Encoding을 수행하는 값의 차원은 [seq_len, d_k*head_num] 이기에, Positional Encoding을 einops 라이브러리에서 repeat으로 늘려준 다음 수행했던 것으로 기억한다.


- 이 부분은 Attention layer에 대해 수행하는 내용이다. 이 논문의 이름이 Attention is All you need가 되는 이유를 설명해주는데, 이전 RNN 모델 구조에 모든 내용물을 연결하는 Attention layer를 위와 비슷하게 쌓았고, 현재는 Recurrent한 구조를 모두 제거 한 후, 이 노란색 블럭인 Attention layer에 모든 것을 의존하기에, Attention is All you need가 된다.
- 그 외에도 많은 중요한 요소가 존재하지만 가장 핵심은 recurrent mechanism을 제거한 것이라고 본다.
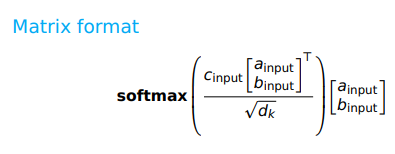
- 이 dot-product attention 연산은, transformer 이전 시대에 보여주었던 내용과 매우 유사하다. 차이가 있다면 저기서 d_k 를 통해 Normalize를 해줬다는 것인데, 여기서 d_k 는 모델의 dimensionality이다. (조금 더 깊게 들어가면 query, key의 dimensionality) 그리고 많은 작업(feed-forward, attention)을 하기 위해 representation의 차원을 같게 만들어 주어야 한다.


- 이전 image의 주황색 layer까지는 contextual representation* 결과이기에, 다시 원래의 초록색 값과 더해줌으로써 완전한 노란색 layer가 완성이 된다. 그리고 이 노란색 layer가 되기 위해서는 간단한 regularization 기법인 Dropout도 적용된다.
contextual representation* : 주황색 layer는 주위의 단어에 대한 정보를 포함하는 representation. 즉, 해당 초록색 layer에서 어떻게 주위의 단어를 어떻게 생각하고 있는지가 주황색 layer의 결과이다. 이 주황색 layer 값에 따라 원래 정보가 손실 될 수도, 더 좋아질 수도 있기에 residual connection 연산을 수행한다. 물론 이 residual connection을 함으로써 모델의 학습이 더 쉬워지기도 한다 (ResNet원리/잔차학습)
- 그리고 layerNorm을 적용한다. 이 layerNorm의 역할은 값들을 scaling해주는 역할이다. 이는 일반적으로 평균을 0으로 만들어주어, 이상적인 가우시안 분포를 만들어준다.


- 그리고 교수님께서 강조하시는 2층짜리 layer로 구성이 된 FF-layer이다. 유일하게 Transformer에
d_k와 다른 차원을 가질 수 있다. 2층의 layer이기에, 확장했다가, 줄어드는 과정에서 많은 representation을 볼 수 있다.
-> Attention layer 자체는 선형이니까 비선형 layer가 필요하지 않을까..
- 그리고, 이 전과 같이 Residual connection을 만든 후, layer norm까지 추가하여 마지막 출력인 c_out을 만든다.
Computing the atttention representations.

- 그리고 왼쪽이 논문에서 제안하는 수식, 그리고 우측이 최적화 된 코드이다. 와우.. 이건 처음보는데 좀 놀랍다.
Multi-headed Attention
- 그리고 이거는 위에서 concept만 간단하게 설명할 때, 빼둔 Mutli-Head Attention부분의 설명이다.



- 왼쪽, 중간, 오른쪽 중에서 유일하게 Multi-Head 안에서 수정된 것은 노란색의 Weight 뿐이다.
- 그리고 출력 결과는 위와 같이 같은 Attention block 끼리 모을 수 있다.


- 그리고 우리는 다음과 같이 파란색 부분을 반복해서 block 처럼 쌓을 수 있다.
- 그리고 주황색 layer가 위에서 보여준 것 처럼 여러개의 Multi-Head로 쌓일 수 있다.
- 논문에서 제시한 논문의 구조는 우측 그림과 같다. 논문에서는 seq2seq 문제를 해결하기 위해 Encoder-Decoder 구조로 되어있다. 우리가 앞에서 본 부분은 Encoder 부분이다.
- 추가적인 부분은 masked-Multi-head Attention을 하는데, 그 이유는 우리가 예측을 할 때 미래를 못 보기 때문이다.

- 그리고 이건 BERT 구조인데, 실제 모델이 어떻게 되어있는지 확인해보기 좋다. 여기서 d_k = out_features = 768 이다.
- Positional Encoding은 512를 써서 maximum으로 sequence length를 사용한다.
- token_type_embedding은 BERT에만 존재하는건데, 내 기억이 맞다면, BERT는 2개의 문장을 입력하기에 이 둘에 대한 정보를 넣어주는 것으로 기억한다.
- layernorm과 dropout을 넣어서 Regularization을 수행한다.
- 그리고 Attention layer는 768의 d_k가 어디에나 존재하는 것을 알 수 있다.
- 중간 output_feature는 3072이다. 이건 MLP layer에 존재한다.
- (1) : BertLayer에서 다시 반복되는 것을 볼 수 있다.



