이전 강의 요약 - XCS224U: NLU I Intro & Evolution of Natural Language Understanding, Pt. 1 I Spring 2023
강의영상 : https://www.youtube.com/watch?v=J52Dtu40esQ&list=PLoROMvodv4rOwvldxftJTmoR3kRcWkJBp&index=2
강의자료 : http://web.stanford.edu/class/cs224u/slides/cs224u-intro-2023-handout.pdf 65페이지부터
강의자료 : https://web.stanford.edu/class/cs224u/slides/cs224u-contextualreps-2023-handout.pdf (다음 강의부터)
Better and more diverse benchmark tasks.



- 우선 강의 중간에 교수님께서 Jacques Cousteau씨는 물과 공기가 쓰레기가 되었다고 하는 말을 보여준다. (왼쪽 상단) 우리의 교수님께서 우리 분야에서의 이 물과 공기는 데이터 셋이라고 하신다. 필요한 존재지만, 이젠 쓰레기다. 이제는, 데이터를 그만큼 효율적이게 써야하지 않나라는 것을 암시하시는 것 같다.
- 요즘 추세는 데이터를 reliable and high quality 하게 써야한다
- 또한 데이터 셋은 많은 곳에 쓰이고, 매우 중요한 역할을 수행한다. (가운데 그림)
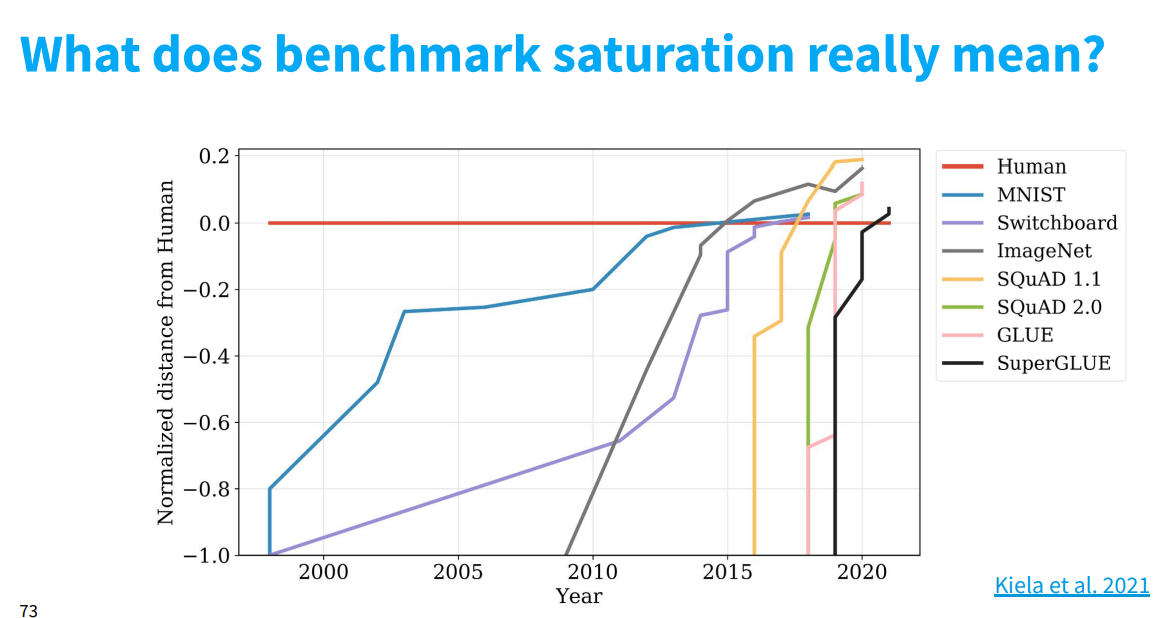
- 지난 강의에서 보여준 그래프, 이제는 모든 면에서 Human을 빠르게 능가함.
- 하지만 이 데이터 셋의 evaluation은 machine task임, Human task가 아님. 그 말은, Human + machine task 모델은 새로운 시대를 열 수 있지 않을까 생각함.
Compositional Generalization


- Cog challenge dataset은 다음과 같이 구성이 되어있다. 우리는 입력으로 다음과 같이 평범한 문장을 넣지만, label, 즉 정답은 아래와 같이 logical representation으로 되어있다. semantic parsing task? 라고 할 수 있다.
- 즉, 모델이 진짜 systematic solution을 배웠는지 확인할 수 있다. Task는 쉽지만, 일반화가 조금 많이 어렵게 되어있다.
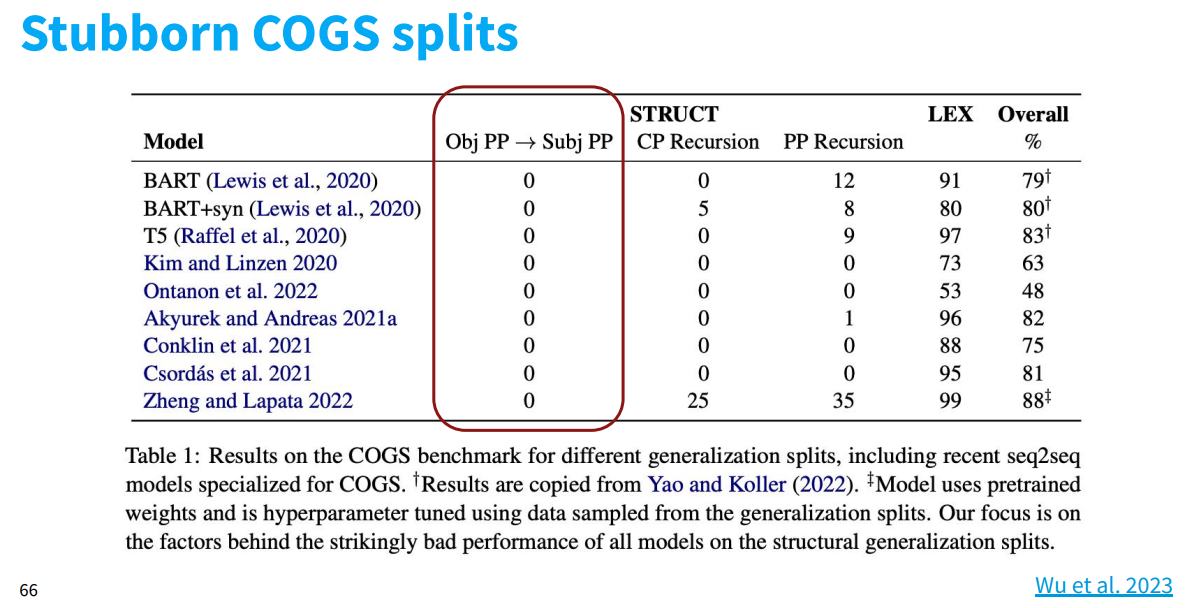
- 하지만 Obj PP -> Subj PP로 바꾸는 task의 경우에는 성능이 매우 낮은 것을 볼 수 있다. 왜 그럴까?


- 이러한 0이 이어지는 이유는 학습이 어렵기 때문이다. 위의 COGS들이 인공적으로 만들어 졌기에, 우측과 같이 기존의 COGS 방법론을 ReCOGS라는 방법론을 통해 불필요한 정보는 버리고, 필요한 정보만 남겨서 학습 및 요약한다. (왼쪽)
- (우측 상단) obj pp → subjPP에서는 성능이 여전히 낮은 것을 볼 수 있다. 이것은 “입력 문장이 매우 simple”함에도 불구하고 이 task가 매우 어렵고 이를 해결하지 못했다는 것을 의미한다. 따라서 돌파구가 필요하다고 생각함.
- 솔직히 ReCOGS가 최신이고 더 좋다는데, 나는 이해를 잘 못하겠다.
More Meaningful evaluations



- 왼쪽의 Strathern's Law는 우리가 AI를 할 때 가장 근본적으로, 가장 신경쓰는 것 중 하나인 성능(Accuracy)에 대해서, Strathern's Law를 적용할 수 있는데, 우리가 성능, 혹은 그 평가 지표만 쫒는 것이 목표가 되면, 그 지표는 더이상 유용하게 작되지 않을 가능성이 크다는 것이다. 우리가 그 외의 중요하게 생각하는 것들을 전부 외곡시킬 가능성이 커지기 때문.
++ 이러한 현상은 과적합, imbalanced Problem등 과 같은 문제를 야기할 수 있을거라고 생각한다. (내 생각)
- 그리고 우측의 논문에서 중요한 가장 중요하다고 말한 것은 → Performance, 즉, 성능이다. 그 다음으로 중요한 것은, 아래의 Efficiency, Interpretability, ... ect 가 있다.
- 색이 칠해진 것은 덜 중요한 것으로 영향력이 없을것이다. 퍼플 오렌지 색은, 더 widely하게 사용하려면, 중요한 것이다. 예를 들어 서비스를 출시한다던가, 어플리케이션을 만든다던가 할 때의 고려해야할 점이라는 것.


- 그리고 Dynascoring이라는 이 논문은, 여러가지 평가측도를, 여러가지 우선순위를 통해 점수를 매기는데, 왼쪽은 Performance에 가장 큰 8이라는 점수를, 다른 평가측도에 2라는 점수를 주고 평가했을 때, DeBERTa가 가장 좋은 성능을 거두었다. 하지만, Performance를 제외한, Fairness를 5점, 다른 점수를 1점을 주고 평가를 하였을 때는 ELECTRA-large가 더 좋은 성능을 거둔 모습을 볼 수 있다.
- 아 여기서 Fairness는 Memory, 즉 메모리 사용량과 다르게, 어떤 환경에서 학습이 되었는지가 될 것 같다. 요즘 논문을 보면 V100 36개를 썼다고 그런 부분에 대해서 점수를 매긴다고 보면 될 것 같다.

- 그래서, 새로운 시대에는 어떤 evaluation이 사용될까? 그리고 기존의 Evaluation 방법과 비교를 하자면?
- 예전에는 One-dimensional 즉, 하나의 차원인 성능에 대해서만 평가를 한다면, 미래에는 위에서 본 것 처럼, 여러가지 기준에 대해서 평가를 시행한다.
- 또한, 이전에는 방대한 양의 데이터 셋을 사용했다면, 이제는 효율적이고, 효과적인 데이터 셋만 사용하는 것이 추세가 될 것 이다.
- 그리고 이전에는 machine task가 주를 이뤘다면, 이제는 Human task가 주를 이룰 것이다.
- 그리고 옛날엔 데이터 셋 만드는거 시간이 엄청 오래걸렸기에, 그냥 사용하는 것을 추천했다면, 요즘은 그냥 너가 직접 효율적인 데이터 셋을 만드는 것을 추천하신다. 내가 전문 지식도 있고, 한 분야의 전문가라면, 나만의 기준 가지고 만들어도 좋을 것이라는 조언을 하신다.
Faithful, human-interpretable explanations of models



- 왼쪽 위와 같이, 크고 불안정한 모델이 있을 때, 이걸 분석할 수 있을지에 대해 회의적인 생각을 가지겠지만, 우리 교수님은 가능하시다.. 하지만 그래도 어려운건 사실.
- 특히, 우리 모델이 특정 dimension에서 bias를 가지지 않는다. 라고 말하기 어렵다. 우리가 예상하지 못한 여러가지 일이 있을 수 있고, 우리의 evaluation에서만 bias가 없었을 수 있다.


- 그래서, 위와 같은 LLM 모델이 있을 때, 이를 전통적으로 분류하는 방법에는 2가지가 있다.
- Human interpretable : Low level의 수학적 설명을 원하지 않는다. (복잡한 계산 x) High level 설명 즉, 주로 개념적인 이해, 큰 그림에 중점을 둔다고 보면 될 것 같다. 수학적 설명이 가능하지만, 때로는 이 방법이 실패할 수도 있기 때문이다.
- Faithful : 내부적으로 모델이 어떻게 동작하는지 완벽하게 이해. 때로는 수학이 맞지 않을 수 있지만, 제공된 설명이 사람들이 이해하기 쉬운 형태거나, 그 설명이 모델의 실제 작동 방식과 얼마나 정확히 일치하는지에 대한 보장이 없다면, 우리는 혼란스러워질 것이라고 한다.
→ Goal: Concept level causal effect.
- 그리고, NLP 모델을 설명하는 방법에 대해서는 우측 위와 같은 방법론이 존재한다.
1. Train/test evaluations : 새로운 샘플에 대해 동작 원리? 동작에 대한 guarantees를 딱히 주지 않음
ex) 특정 데이터 셋에 학습시킨 후, 다른 데이터 셋으로 평가
2. Probing method : Hidden representation을 이해하기 위한 시도. 하지만 casual inference는 딱히 제공하지 않음.
ex) 모델의 layer를 임의로 고른 후, 해당 layer의 출력을 보며 어떤 역할을 수행하는지 확인.
3. Attribution method : representation의 중요도(입력, 출력, 히든)를 확인한다. 하지만 모델의 내부 표현 자체를 깊게 탐색하진 않음.
ex) 입력, 중간, 출력 layer의 특정 부분이 최종 결과에 어떤 영향을 미치는 확인
4. Active manipulations : causal insight 와 그 상태의 자세한 rich characterization을 확인 가능하다.
ex) 모델의 내부 상태를 직접 조사하여 출력이 어떻게 변화하는지 관찰
5. interchange intervention training : 고수준의 심볼릭 모델의 구조에 맞게 훈련하여 보다 신뢰할 수 있는 모델을 생성
ex) 모델이 고수준의 심볼릭 규칙/이론을 따르도록 데이터를 조작하거나 목적 함수를 수정.



