강의 제목 : Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018)
강의영상: https://www.youtube.com/watch?v=jGwO_UgTS7I&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=1'
강의 자료: http://cs229.stanford.edu/main_notes.pdf
CS229 Syllabus Spring 2023: https://docs.google.com/spreadsheets/d/12ua10iRYLtxTWi05jBSAxEMM_104nTr8S4nC2cmN9BQ/edit#gid=639488399
CS229를 듣기 전 봐야할 PPT: https://cs229.stanford.edu/materials/ML-advice.pdf
CS229를 듣는 학생들은 기말 프로젝트로 어떤걸 할까: https://docs.google.com/document/d/11WOBZKXOIwo0JbQCQaqzZCFBB8ho2Hn-BhA2wwnh1N4/edit
CS229 한장 요약: https://stanford.edu/~shervine/teaching/cs-229/cheatsheet-supervised-learning
CS229에 들어가는 선형대수학 요약: https://cs229.stanford.edu/notes2022fall/cs229-linear_algebra_review.pdf
CS229에 들어가는 확률이론 요약: https://cs229.stanford.edu/notes2022fall/cs229-probability_review.pdf
강의 정보 : http://cs229.stanford.edu/syllabus-autumn2018.html
CS229: Machine Learning
Syllabus and Course Schedule Time and Location: Monday, Wednesday 4:30-5:50pm, Bishop Auditorium Class Videos: Current quarter's class videos are available here for SCPD students and here for non-SCPD students.
cs229.stanford.edu
우선 이 강의는 너무 유명해서 별다른 언급은 별로 필요하지 않을 것 같다.
이 포스팅은 1. 내 복습, 2. 누군가 틀린점이 있다면 고쳐주길 바라는 마음, 3. 누군가 CS강의를 대충 보고싶다면 추천한다.
+ 1강은 별다른 내용이 없다. 1강을 건너뛰고 싶은 사람이 봐도 좋을 것 같다.
Supervised Learning, Regression Problem and Classification Problem
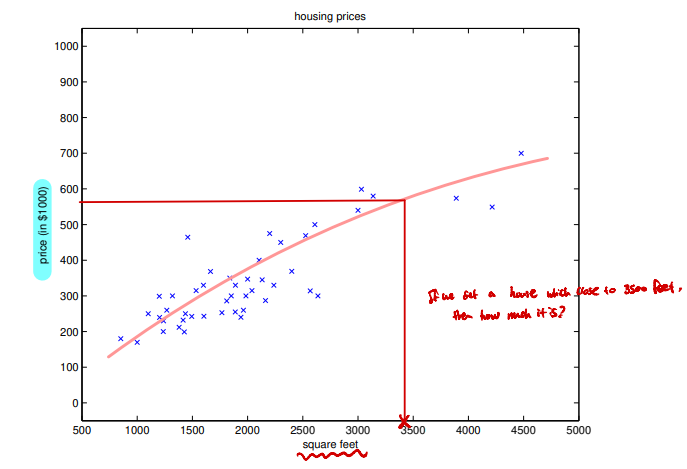
- 우리가 3500평 정도의 땅을 가지고 있다면, 과연 얼마를 주고 팔아야 할까?
- 우리가 팔아야 하는 가격을 알고 싶으므로 Regression Problem이다. 반대는 Classification Problem이다.
- Classification Problem으로는 malignant 여부, 즉 암이냐 아니냐가 되겠다. 1혹은 0으로 판단하므로 Classification이다.

- 위의 예제를 바탕으로 입력 값 square feet, tumer size를 x(i) 즉, input, input feartures라고 부른다.
- y(i)를 output, target 으로 부른다. price 혹은 malignant가 된다.
- 강의 노트엔 없지만, m은 training examples 즉 학습 데이터의 수 이며, n은 number of features이다. 여기서 n = 1이다.
- 입력 데이터는 쌍으로 (x(i), y(i))가 training example으로 불린다. 확장하면 {{(x(i), y(i); i = 1, ..., n} 으로, training set 이다.
- 입력 데이터 x(i)를 모아둔 것을 X, y(i)를 모아둔 것을 Y로 정의한다. (티스토리 LaTex안되는거 화난다)
- 따라서 X = Y = ℝ와 같이 정의가 가능하다. ℝ은 실수의 집합이다.
- 우리의 목표는 함수 h를 학습하는데, h는 다음과 같다. h : X → Y 즉 X와 Y를 잘 mapping하는 함수 h(x)를 만드는 것이다.
- h는 hypothesis (가설) 이라고 불린다.


- Flow를 그린다면 다음과 같다. Training set {{(x(i), y(i); i = 1, ..., n} 을 가지고 Learning algorithm을 통해 h를 잘 만들면 된다. 그리고 새로 들어오는 입력 X에 대해 잘 예측된 y가 나오게 하면 된다.
- 파란 형광펜은 다음과 같이 써져있다. How to represent the hypothesis?
-> Hypothesis를 설정하는 방법은 위의 네모와 같이 Training set을 정의한 후, 모델의 구조, 학습 알고리즘, 하이퍼파라미터 등을 설정하는 것과 같다고 볼 수 있다.
- 그리고 입력 특징 집 값 예측에서의 땅 크기와 같을 때 우리는 h(x) = θ0 + θ1x1 으로 정의할 수 있다. 입력 특징이 하나니까! 그리고 이것은 수학에서의 Affine Matrix라고도 불리는데, 뭐 그렇게 중요하진 않다. 강의노트에 내가 적어뒀길래 가져왔다.
- 그래서 Supervised Learning이란? 위와 같이 입력 데이터 X가 들어왔을 때, 이를 가장 잘 표현하는 Y를 뽑아내는 h를 만드는 것이다. h : X → Y 를 기억해도 좋다.
- 이 내용 외에는 전부 잡담이라고 봐도 될 것 같다. 2강 부터 길어지니 2강에서 보자.
Stanford CS229 강의 요약 Machine Learning - Linear Regression and Gradient Descent | Lecture 2 (Autumn 2018)
Chapter 1. Linear Regression. - 이번엔 bedrooms라는 정보가 포함이 되었다. multi feature가 되었다. 따라서 x는 ℝ이 아닌 ℝ^2 가 된다. (LaTex화난다) - 따라서 수식은 아래와 같이 x2에 대한 항이 하나가 추가
187cm.tistory.com



