저자: Heng Pan
소속: Zhejiang Univ
출판: 2023.04.27 Arxiv
기초 개념
Masked Image Modeling(MIM)은 pre-training 단계에서 입력 이미지는 masked되어, unmasked부분을 바탕으로 original 이미지를 복원한다. 원본 이미지로 잘 복원시키는 모델은 downstream task에서 잘 동작할 것이라 믿어짐.
Problem
- 어떤 type의 deep feature가 MIM에서 적절한지 알아보기 위해 잘 훈련된 model을 feature extractor (teacher)로 사용
- 이미지의 특징을 생성하는 teacher model이 가벼울수록 성능이 더 좋은 현상 발견
- 기존의 Knowledge Distilation(KD)에서 Teacher 모델의 성능이 좋을수록 Student모델의 학습이 잘된다는 고정관념 타파.
- 그렇다면 KD에서 어떤 지표가 Student model의 성공적인 학습을 시키는지에 대한 의문점 및 해결책 제기.
요약
- Deep feature와 MIM를 사용한 Image to Vector(Img2Vec) 제안.
- Token diversity라는 평가 지표를 통해 모델이 특징을 얼마나 다양하게 생성하는지를 확인.
- 큰 모델이 MIM을 향상시킬 것이라는 인식이 아닌, high token-diversity를 중요하게 생각.
- High token-diversity를 바탕으로 teacher model 선정하여 IN, COCO, ADE20K 등 각종 Dataset에서 좋은 성능을 보였다.
- Teacher model으로 Convolution Model인 ResNet50을 DINO 방식으로 pre-training한 방식 사용.
1. Introduction


- MIM에서의 핵심은 어떤 부분을 복원시키냐인데, edge나, low-level feature를 복원할 경우(MAE - He et al., MaskFeat) complex or abstract한 부분을 복원시키는데 어려울 수 있으며, 반대로 high-level semantic(iBOT, MVP) 즉 전체적인 구조에 초점을 두면 세부적인 부분에서 어려움을 겪을 수 있다.
- High-level feature를 재건축하는것이 downsteam task에서 좋은 성능을 보였지만, 어떤 High level feature가 좋은지
밝혀지지 않았기에 실험을 통해 비교해보고자 하였다. 기존의 Pre-training model 사용 혹은 EMA 방식이 성능이 좋았다.
- Teacher 모델을 target provider로 사용했을 때, 성능이 좋은 teacher model이 좋은 student model을 이끌지 못한다. 이는 KD에서 직관적이지 않으며 말이 되지 않는다.
- teacher model과 student model의 target의 token이 높은 similarity를 공유할 때, Token 사이의 의미를 찾기 어렵다. 이는 MIM에서 harmful하다고 강조한다. 따라서 기존의 KD와는 다르게 teacher model은 high token diversity를 가져야 한다.
자세한 정보는 3-2에서 소개한다. Figure1에서 볼 수 있듯이, Token Diversity가 높을 수록 성능이 높은 모습을 볼 수 있다.
- Downstream task에서 좋은 성능을 내기 위해 global semantics를 주입했다. 따라서 Student encoder의 output을 aggregate하여 Teacher model의 output과 비교하는 multi-block feature leaarning 방식 사용 (Figure 2참조)
2. Related work.
Self-Supervised Learning(SSL)
- SSL은 non-annotated data를 효과적으로 학습할 수 있는 방법으로 discriminative or generative하게 나눌 수 있다.
- generative: corrupted 된 이미지 합성, 생성
- discriminative: task 해결이 주 목적. ex) 이미지의 회전 각도 계산, Similarity를 극대화 하는 Contrastive Learning.
Contrastive Learing에 대한 설명이 필요하다면 여기서 볼 수 있다.
논문으로 알아보는 Contrastive Learning (1) - DrLIM (Dimensionality Reduction by Learning an Invariant Mapping)
MoCo Review를 하기 전, MoCo에서 많이 언급되며, Contrastive Loss를 처음으로 사용한 논문으로 소개되는 Hadsell - Dimensionality Reduction by Learning an Invariant Mapping (DrLIM) in 2006 CVPR 논문에 대해서 먼저 정리하고
187cm.tistory.com
Masked Image Modeling (MIM)
- MIM은 masking strategies와 reconstruction target 파트로 나뉨.
- masking strategies: Random strategy와 Attention strategy를 사용한 부분으로 나뉨.
- reconstruction target: HOG를 이용하여 low level을 예측한 MaskFeat, high level을 예측한 iBoT🤖 등이 존재
논문 읽기 - MaskFeat: Masked Feature Prediction for Self-Supervised Visual Pre-Training
저자: Chen Wei 소속: Facbook AI Research and Johns Hopkins University. 학회: CVPR2022 인용: 2023.04.28일 기준 228회 BaseLine hand-crafted feature descriptor - Image, Video에서 기초적인 특징(Color, shape, texture, motion)을 묘사하는
187cm.tistory.com
3. Method
3-1. A unified framework for MIM
- 위에서 언급한 것처럼 High level feature를 복원시킨게 성능이 더 좋았다. (BEiT, data2vec, BootMAE)
- 하지만 BEiT는 pre-train model로 DALL-E를 사용하여 특징 비교가 어렵다. -> MAE와 비슷한 통합형 Framework 제작.
- 또한 Img2Vec은 Teacher Model은 MIM Learning단계에서 Frozen시킴.
3-2. Token diversity for teacher evaluation.
- Only ImageNet-1k에서만 pre-train된 model 사용. (MAE ViT-B, MAE ViT-L, DINO ViT-B)

- MAE와 SimCLR은 Masking 사이즈는 32x32를, ViT의 경우 Patch사이즈와 동일하게 16x16을 사용하였습니다.
- SOTA를 달성한 ViT model이지만, MIM을 위한 KD에서 Teacher Model은 Parameter가 더 적은 ResNet기반 모델이 더 좋았다. 따라서 저자는 teacher의 quailty에 영향을 주는 지표에 대해서 얘기를 한다.

- Teacher model과 Student model의 Cosine similarity를 Figure3의 같은 빨간 패치(query)를 기준으로 모든 토큰들과의 Similarity를 구한다. MAE ViT-B와 DINO RN-50과 비교를 하면, DINO가 query을 기준으로 했을 때, 더 다양한 값을 가지는 것을 볼 수 있다. 특히 MAE ViT-B의 경우 Similarty가 높기 때문에 여우의 몸에 대해서는 예측하지 않는 모습을 보인다.
- 아래의 수식은 Token-diversity를 구하는 수식이다. K는 Token의 수, N은 IN-1k의 Training sample 수 이다.
Input Image 224 고정, ResNet계열은 32x32, ViT 계열은 16x16 Patch를사용하므로, K는 각각 7x7, 14x14가 된다.
N은 140만쯤 될 것이다. 2중 for loop를 돌며 i != k 일 때를 제외하고 더한 후, K(K-1)로 나눠 평균을 구해주면 된다

- masked target(Figure 2의 Student)와 visible target(Figure 2의 Teacher)의 similarty가 높을 경우,
visible특징을 예측하지 않아도 similarity가 높아 Representation Learning의 목적을 위반하고, Student model의 성능을 저하시키는 모습을 볼 수 있다. Figure 3의 MAE ViT-B와 DINO ResNet50을 비교해보자
- ViT의 경우, global attention mechanism을 사용하므로, output token끼리 유사해지는 현상이 발생한다. 하지만 ConvNet의 경우, inductive bias와 locality로 인해 인접한 특징을 더 잘 뽑아낼 수 있다. 따라서 결국 diversity가 높은 모델은 Convolution 계열의 모델이 되며, Teacher Model이 된다.
3-3. Img2Vec
- MAE와 다르게 raw level의 RGB값을 복원하는 것이 아닌, deep feature학습.
- Multi-block feature learning과 Global semantic learning 이라는 것을 사용
- Decoder layer는 MAE와 다르게 2층(ViT-Base), 4층(ViT-Large) 사용.
- Masking 비율은 60%, 32x32 크기의 Masking 사용.


- Patch Loss의 수식은 (2)와 같으며 smooth L1 loss를 사용했다. Beta = 2이다. 오메가와 M은 각각 Cardinality와 패치이다.
- Multi-Block feature learing을 사용하여 lower-level semantics가 무시되는 것을 방지하며 동작방식으론, 모든 인코더의 layer를 합쳐서 하나로 만든 후 평균을 취한다.
- Global semantic learning: MIM에서 masked된 이미지를 예측하는 것은 이미지 관점에서 시각적인 감각을 이해하지 못해 성능이 저하되는 문제가 발생 가능하다. 따라서 Global smoth L1 Loss를 하나 더 사용한다. ViT에서 GAP를 output에 대해서 실시하는 것처럼 GAP를 실행한 후 Global L1 Loss를 구한다.
- 또한 Figure 2에서 보이는 것처럼 Projection Head가 존재하는데, MLP layer와 ReLU로 구성되어있다.
- K는 teacher output token의 수, V는 visible patch를 가르킨다.
- 람다 값은 0.5로 균일하게 사용하였다.



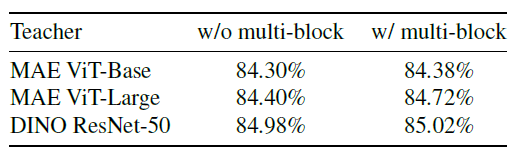
성능

결론
- 핵심적인 부분은 MIM에서는 기존의 KD의 통용되는 지식과 다른 Teacher Model을 써야한다.
- 그 지표로 Token diversity를 새롭게 제시하여 사용하였고 ResNet50을 사용하였다.



