저자: Hangbo Bao
소속: Harbin Institute of Technology(하얼빈 공대) and Micrisoft research
학회: ICLR2022 Oral
인용: 991 (2023.04.30 기준)
BaseLine
- Bidirectional Encoder Representation from Transformers (BERT)는 NLP분야에서 뛰어난 성능을 보인 논문 중 하나
- BERT는 Masked Language Modeling 분야에서, 단어를 Masking 후, Mask된 단어를 예측하는 방식의 Pre-train 방법사용.
- Masked Image Modeling (MIM) 분야는 이미지를 Patch 단위로 쪼개 입력으로 넣고, Mask된 Patch를 복구하는 방식
- Bidirectional Encoder representation from Image Transformers (BEiT) 는 BERT에서 영감을 받아 Image 분야에서 MIM 방식과 BERT를 결합한, BEiT를 제안
from-scratch training: 모델의 Pre-train weight을 가져다 쓰는 것이 아닌, random weight 사용하여 학습하는 법.
Problem
- BERT에서 단어의 정보를 Dictionary라는 이름으로 저장하지만, vision 분야에서는 Dictionary가 없다.
- Transformer는 이제 vision 분야에서도 Convolution Network Model에 비해 뛰어난 성능을 보이지만, Transformer는 data hungry issue가 발생하며, 추후의 논문은 self-supervised를 이용해 이 문제를 해결하는 것을 보여준다.
(Contrastive Learning, Efficient training of ViT)
- masked patch의 raw pixel value를 예측할 순 있지만, 짧은 범위의 dependency와 높은 주파수 (복잡한 부분)에 대한 capacity낭비가 심하다.
Abstract
- NLP 모델인 BERT와 유사한, MIM 분야에서의 Self-supervised 방식의 Vision Representation model인 BEiT 소개.
- 이미지는 image patches, visual tokens의 2가지 관점으로 나뉜다.
- 하나의 이미지를 하나는 Tokenisze하여 visual token으로 만들고, 하나는 patch단위로 쪼개 mask작업을 진행하여 Transformer backborn에 삽입한다. (Figure 1 그림 참조)
- visual token을 바탕으로 이 mask된 patch들을 복구시키는 것이 목표이다.
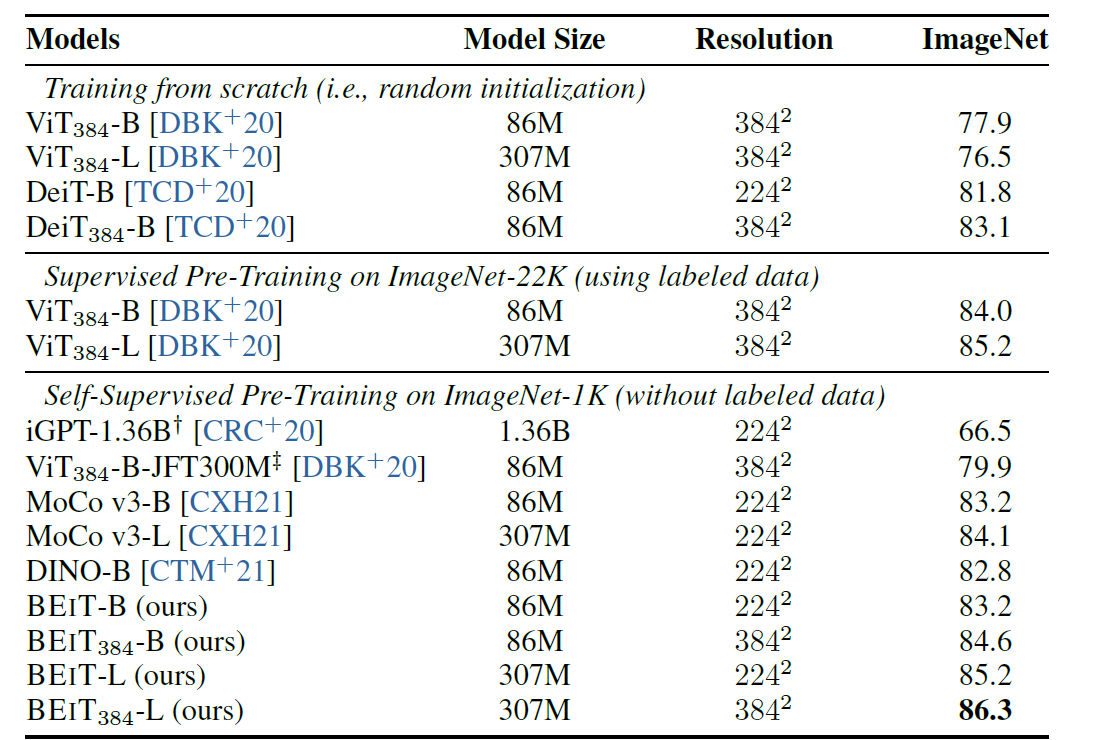
- downstream task인 image classification, semantic segmantation에서 from-scratch training, 기존의 pre-train 방법보다 더 좋은 성능을 보인다.
1. Introduction.
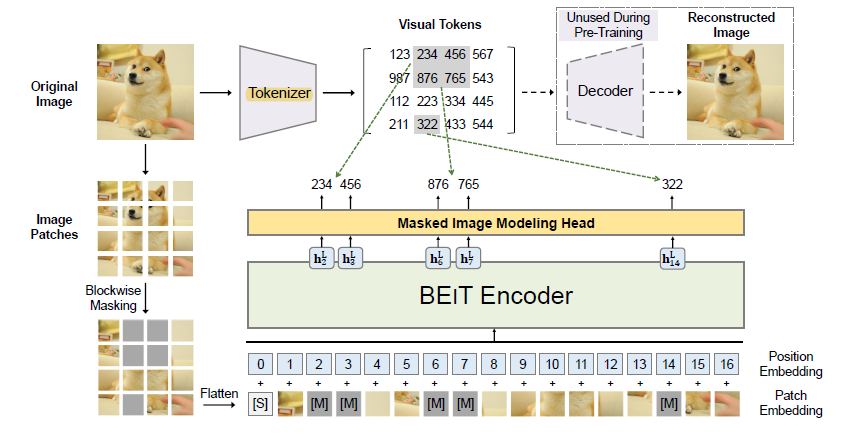
1. 하나의 이미지에 대해 Patch단위로 쪼갠다.
2. Blockwise masking을 한다.
3. Flatten한 후 [S] (Special) Token과 masking된 부분은 learnable paramter인 [M]으로 대체한다.
4. Patch Embedding과 Positional Embedding을 실시한다.
5. 원본 이미지에 대해 또 다른 하나의 Encoder를 통과하여 Tokenize를 실시한다.
6. Tokenize된 값과 또 다른 하나의 Encoder를 통과하여 나온 값인 [M]+ PaE + PoE 를 복원한다.
- 원본 이미지의 Raw value를 예측하는 것이 아닌, deep feature(latent vector)인 visual token을 이용한다.
- BEiT는 IN-1k에 대해 Supervised Learning으로 추가학습 했을 경우 더 좋은 성능을 보였다. 즉 SL의 단점을 보완한다.
(SL의 경우 정답을 맞추는데 초점을 두어 이미지가 어떤 모양인지가 아닌, 정답이 무엇인지에 초점을 두게 된다.)
2. Method
2.1 Image Representations
- image patch, visual tokens의 두 가지 관점이 있다.
- image x의 크기 224x224x3 (HxWxC), patch의 수 N은 HW/P^2 (N=14, P=16), xp는 patch들의 shape이다. ViT와 똑같다.
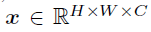
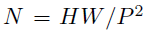
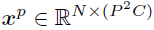
- tokenize된 Image(token)은 z로 표현이 가능한데, 여기서 V는 개별적인 token의 index를 담고있는 dictionary이다.
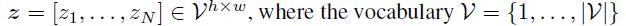

- z는 위에서 본 tokenize된 image(token)이며, q는 tokenizer(encoder), pψ는 decoder이다.
- 따라서 tokenizer의 목표는 위의 수식과 같다. 이미지 x가 tokenizer q에 들어왔을 때의 확률 분포 q(z|x)를 통해 생성된 z에서 decoder p를 통해 가장 큰 log-likelihood를 만족시키는 값이 된다. 결론은 x를 maximum log-likelihood를 가지게 하여 원본 이미지에 가깝게 복구하는 것이다.
- visual token은 14x14 크기를 가진다. vocabulary V의 크기는 |V| = 8192이다.
- visual Token은 196개 지만, V의 크기는 8192, nn.Conv2d(input = hidden_dim, output = 8192, kernel = 1)가 일어난다.
- 아래의 코드에서, init은 num_token(vocabulary size) = 512, enc_layers.append(nn.Conv2d(hidden, num_tokens, 1))으로 output이 512로 될거같지만, dVAE를 정의하는 곳으로 넘어가면 NUM_TOKENS 8192로 선언한 것을 볼 수 있다.
- 2-2 notation은 skip한다. 기존의 ViT notation과 너무 똑같다. [S]는 special token이다.


2.3 Pre-Training BEIT: Masked Image Modeling
- Blockwise masking을 40% 진행.
- masking 된 이미지는 수식으로 다음과 같이 나타낼 수 있다. xp = 정상, e[M] = Masking. N는 Patch의 수

-xM을 입력으로 하는 MIM(BEiT Encoder + MMH)은 softmax를 통해 visual token(14x14) -> (Hidden) -> (8192)중 하나를 고르게 된다.
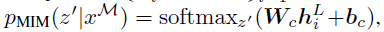
- 그리고 pre-training의 objective는 다음과 같이 log-likelihood를 최대화 하는 방향으로 학습하게 된다.
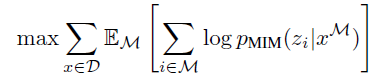
- Blockwise Masking을 사용하여 masking을 진행하였는데, 알고리즘은 다음과 같다.

1. s <- Rand(16, 0.4N - |M|) . s는 16부터 0.4N - |M|까지의 랜덤 숫자.
2. r <- Rand(0.3, 1/0.3) r은 0.3부터 3.33 정도까지의 랜덤 숫자로 종횡비를 나타낸다.
3. a <- (s x r )^(1/2); b<- (s/r)^(1/2)
4. t <- Rand(0, h-a); 224-a값 중 랜덤 값. l <- Rand(0, w-b)는 224-b의 값 중 랜덤 값.
5. M <- M U {(i,j); i \in [t, t+a), j \in [l, l+b)} 여기서 a, b크기의 마스크를 M에 추가함.
- 즉 Blockwise Masking은 랜덤한 직사각형 크기의 mask를 사용하게 된다. 불규칙한 masking 방법을 사용함으로써,
학습을 더 어렵게 만들 수 있다.
- 이미지의 pixel-level의 auto-encoding이 아닌, discrete visual token을 예측함으로써, high-level detail추출이 가능하다.
2.4 From the Perspective of Variational Autoencoder
- 위에서 Visual Token Reconstruction을 최대화시키는 것이 Tokenizer의 목표라고 언급했다. 여기에 KL divergence Loss를 추가하여 evidence lower bound (ELBO) 형태를 가지는 최종 목표를 완성한다.
- KL Divergence를 통해 encoder의 출력과 decoder의 출력을 같으면 0, 다르면 다를수록 더 커지는 KL loss를 사용합니다.
- pθ(z|~xi)의 경우 손상된 이미지에 대한 latent vector z의 확률 분포 이므로, 추정을 통해 바꾸어주어야 합니다.

- image tokenizer를 dVAE로써, reconstruction은 maximize하는 것을 목표로 합니다. (Visual Token Reconstrution)
- 또한 tokenizer qϕ, decoder pϕ 의 weight를 보존하며, latent vector pθ를학습해야 합니다.

- 위의 pθ(z|~xi)를 one-point distribution으로 바꾸어 argmax로 표현하면 최종 목표는 아래와 같은 수식으로 바꿀 수 있다.
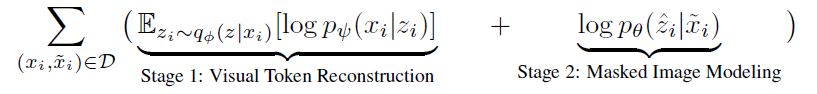
2.5 Pre-Training Setup
- 12 layer의 Tranformer, 768의 Hidden size, FFN은 3072, patch size = 16^2, 224x224 image, 14x14 grid image patches
- IN-1k에 대해 pre-training. (Self-supervised Learning), random mask at most 75 patches (40%)
- Augmentation: random resize crop, horizontal flipping, color jittering.
3. Experiment and Result.