오늘 가볍게 요약한 논문은 CVPR2023에 올라온 Masked Image Modeling 분야의 논문이다. Masked Image Modeling(MIM) 방식을 siamese form으로 변형하여 특징을 이해해보는 논문이다.
제목: Understanding Masked Image Modeling via Learning Occlusion Invariant Feature
저자: Xiangwen Kong
소속: MEGVII Technology china
학회: CVPR2023
등재: 2022/8/8 Arxiv, CVPR에 올라온 논문과 Figure 차이가 있으니 더 보고싶다면 Arxiv 참조.
인용: 14
0. Abstract
- MIM에 대한 관심은 증가했지만, 여전히 MIM이 어떻게 동작하는지는 잘 알려지지 않았다, 그 이유는 siamese approach와 같은 방법론과 다른 접근법이기 때문. ex) Contrastive Learning
- 따라서 해당논문에서는 MIM이 occlusion-invariant feature를 다른 siamese 방식과 유사하게 학습한다는 것을 밝히며, siamese 방식은 다른 invariant feature를 학습한다는 것을 밝힌다.
- 위의 특징을 밝히기 위해 MIM을 siamese방식과 유사하게 바꾸며, a) data transform, b) similarity measurement. 이 두가지가 다르다는 것을 밝힌다.
- 그리고 MAE의 성공 요인을 2가지로 파악했는데, L2-norm을 사용한 것은 약간의 도움이되며, masking방식을 통한 occlusion invariant feature를 ViT에 넣는 것은, 초기 initalization에서 도움이 된다는 것이다. 즉, Patch masking 방식이 큰 성공의 요인이라고 생각한다.
- Patch masking이 중요하는 것을 증명하기 위해, 딱 한장에 이미지에 대해서 MIM방식을 수행하고, Random initializing 한 fine-tuning 방식과 비교를 통해 성능이 더 높다는 것을 증명해야한다. 이 과정을 통해 MIM이 data agnostic occlusion invariant features를 학습한다는 것을 보여준다.
1. Introduction
- self-supervised Learning에서 Invariance는 label이 주어지지 않은 상황에서 매우 중요했음. Contrastive learning또한 이 invariance를 학습하는 것으로 이득을 많이 봤다.
1-1. Contastive Learning

- 다음과 같이 주어진 Contrastive Learning에서 τ를 통해 입력 이미지 x에 대해 Transformation을 하는 과정이 핵심. 왜냐하면 이 이미지들은 변형에 둔감하기 때문에 τ = (colorjitter, RandomCrop, resizeing) 와 같은 과정을 통해 invariance 학습
- ℳ은 distance function or similarity measurement. D는 Input Data Distribution
1-2. Masked Image Modeling

- 이 수식은 MIM방식의 수식이다. M은 masked token을 의미하며 ⨀ 는 element wise를 의미한다
- 위의 Contrastive Learning방식과 비교하였을 때, MIM은 Augmentation에 그렇게 큰 노력을 하지 않는다. 또한 ViT에서 MIM이 더 좋은 성능을 보여주었기에, 큰 모델에서의 확장 가능성또한 MIM이 더 높다.
1-3. Summarize
1. MIM framework와 Contrastive Learning의 framework를 통합하여 이해를 하려고 노력.
2. MIM이 성공을 거두었지만 왜? 그런지는 아직 모름
3. 이전 논문들이 MIM은 풍부한 hidden representation을 거둔다고 주장하며 (MAE 2020 Kamming He), 수학적인 이해를 제공하기도 하였지만(How to understand masked autoencoders 2022 Shunhao Cao) 여전히 명확하지가 않음.
2. MIM intrinsically learns occlusion invariant feature
- MAE와 같이 l2 loss를 쓸 때, 수식은 아래와 같다.
- 입력 이미지 크기를 224x224라고 가정하고, 패치로 나누면 16x16의 크기로 나눌 수 있고, 각각의 패치는 768 차원의 Vector와 mapping이 되니까 16x16x3 <= (768 or 1024) 이기에 lossess하게 Encoder는 mapping 또는 학습이 될 수 있다.
- 크게 보면 224x224x3 = (196+1) x (16x16x3 혹은 MLP(16x16x3)=1024) 가 된다. 참고로 MLP는 ViT에서 Head 전 layer

- siamese 관점으로 수식을 바꾸어서 생각해보자. 위의 내용을 바탕으로 d' 라는 이상적인 decoder는 원본이미지를 완벽하게 복구할 수 있다(마스크 안된 정상 부분). 따라서 뒤의 || ||2 안의 수식을 쪼갰을 때, 오른쪽에 있는 수식을 아래와 같이 정리 가능.
- 그림으로 설명하면, 왼쪽의 MAE에서 마스크 된 부분은 우측의 수식에서 decoder d라고 생각하고, 마스크 안된부분은 lossess하게 복원이 가능한 decoder d'라고 생각하자. 그리고 ϕ는 d'를 가장 이상적으로 만들 수 있는 parameter이다.


- 조금 더 간단하게 정리하면 수식 (4)를 (5)로 바꿀 수 있다. 그리고 이에대한 정리는 수식 (6)


- 따라서 우리는 다음과 같이 정리가 가능하며 이 공식을 siamese form of MAE라고 부른다.

2-1 Discussion
- 위의 수식을 분석해보았을 때, 우측의 수식은 Contrastive Learning의 다른 꼴로도 볼 수 있다. 두 masking 변환된 representation의 차이를 줄이려고 하니까.
- 차이점이 있다면, 초반에 Transformation, Similarity를 l2를 쓰는 과정 말고는 없다.
- 또한 (7)에서 뒤의 수식은 AutoEncoder의 form으로도 볼 수 있는데, 이러한 관점에서 unmasked 된 부분 또한 decoder를 통과한다는 것은 collapse of the similarity measurement를 피할 수 있게 해주는 역할이 된다. Decoder 또한 유의미하게 학습되게 만들 수 있다는 말인 것 같다.

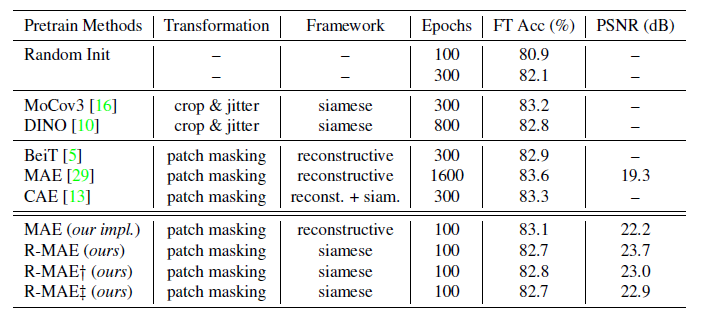
- invariant한 특성이 부족한 수식 (7)의 단점 -> nested optimization을 보완하기 위해 위와 같이 수정된 RelaxMIM/R-MAE를 제시한다.
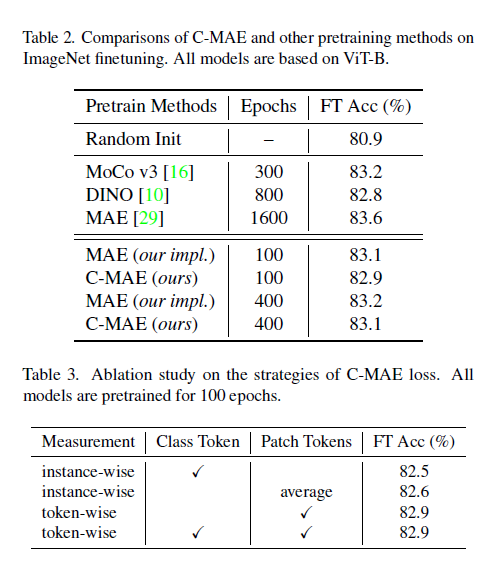
2-2. Empirical evaluation.
- CKA를 시각화 했다. R-MAE가 좋았다.
- 기존의 성능보단 떨어지는 결과를 보였다.

3. Similarity measurement in MIM is replaceable
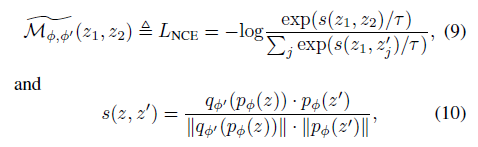
- 그렇다면, siamese network로 바꾼김에 Loss function또한 InfoNCE로 바꿔보자. (C-MAE)