논문 링크: https://arxiv.org/abs/2308.00261
제목 : Improving Pixel-based MIM by ReducingWasted Modeling Capability
저자 : Yuan Liu et al.
소속 : Shanghai AI Laboratory
학회 : ICCV2023
인용 : 3 (2023.12.14 기준)
Abstract
Masked Image modeling (MIM) 은 크게 2개의 그룹으로 나눌 수 있다.
1. Pixel-based
- SimMIM, Masked AutoEncoder(MAE)와 같이 Raw pixel을 예측하는 방법이다.
- 이 Pixel-based 방법론의 장점은 MAE를 보면 잘 알 수 있다.
1. Simple pipeline
2. Lower computational cost
3. biased to High frequency details (ex. edge, line, textures or specific parts in object)
- 하지만 이 Pixel-based approaches의 단점은
1. Learning mechanism이 Corrupted된 주위의 토큰을 복구시키는 것이기에, Low frequency detail에 대한 Wasted
되는 capacity가 생기게 된다(Figure 2에서 제시).
2. Figure 1을 보면, 1에서에 이유를 바탕으로, Shallow layer의 Normalized weighted values가 Deeper layer에 비해 더 높은 경향을 보여준다. 이는 모델이 Shallow layer 부분에 초점을 맞춘다는 것을 볼 수 있다.
2. Tokenizer-based approaches.
- EVA, CLIP과 같은 additional tokenizer를 사용해서 MIM 방법론을 사용.
3. Proposed method.
- 따라서 이 논문에서는 간단하게 Feature를 섞는 방법을 통해, Shallow layer에만 모델이 focus하는 문제를 해결하자 했다.
- 이 방법론을 통해 1. convergence speed 상승, 2. wasted capability 문제 해결, 3. Downstream task에서 성능 상승. 4. ViT와 같은 isotropic/columnar architecture에서 처음으로 Feature를 fusion하려고 시도함.
Introduction
1. Introducing background knowledge
- SSL이 최근 remarkable한 성능을 NLP/CV 분야에서 보여주고 있다.
- 이 SSL은 크게 Contrastive Learning / Masked Image Modeling과 같이 나눌 수 있다. 하지만 이 논문에서는 Contrastive learning은 딱히 언급하지 않는다. 따라서, MIM approach의 장점을 정리해보자면 아래와 같다.
1. effective framework. (SimMIM, MAE와 같은 논문은 간단하면서도 SL을 넘는 성능을 보여주었다)
2. few handcrafted data augmentations
3. high performance accross downstream tasks.
- Pioneering works of MIM approaches
1. BEiT: 40% random masking, visual tokenizer는 DALL-E로 Reconsturcting 시도, random masking된 부분의 output과 visual tokenizer가 최대한 유사하게 한다. 구체적인 설명은 아래 링크 참조.
논문 읽기 - BEIT: BERT Pre-Training of Image Transformers
저자: Hangbo Bao 소속: Harbin Institute of Technology(하얼빈 공대) and Micrisoft research 학회: ICLR2022 Oral 인용: 991 (2023.04.30 기준) BaseLine - Bidirectional Encoder Representation from Transformers (BERT)는 NLP분야에서 뛰어난
187cm.tistory.com
2. MAE: More efficiently changed architecture. 구체적인 설명은 아래 링크 참조.
- simple pre-training pipeline
- minimal computational overhead.
- There still exists the problem of bias in high-frequency detail.
-> This problem lead to waste capability capturing the low-frequency information.
논문 읽기 [MAE] : Masked Autoencoders Are Scalable Vision Learners
논문 링크 : https://arxiv.org/abs/2111.06377 저자 : Kamming He 인용 : 2170 (2023.06.22) 소속 : FaceBookAI Research (MetaAI) 학회 : CVPR2022 Summarize - 아래의 왼쪽 이미지가 이 논문의 처음이자 끝이다. 이미지를 일정한
187cm.tistory.com
3. 그 외에도 CMAE, MILAN 과 같은 방법론이 존재한다.
2. Training Objective
- 위와 같은 방법론, 문제점을 바탕으로 저자가 해결하고자 하는 바는 다음과 같다.
1. reducing wasted modeling capacity.
2. Based on 1, expecting the performace increased in downstream tasks.
3. Methods.


1. Fuse shallow layers.
- 왼쪽 그림은 Pre-training 단계에서 각 iteration에서의 layer별 weight의 value를 Normalize 하여 시각화 한 것이다. 이 Normalized weight가 크다는 말은, 해당 모델이 특정 iteration에서 Output을 만드는 데에 중요하게 사용되었다는 것을 의미한다.
- 왼쪽 그림에서 Shallow layer들의 Normalized weight value가 전반적으로 Deeper layer에서의 weighted sum보다 크다. 왼쪽 그림이 주로 모델의 output을 만들어 내는 데에 중요하게 사용된다는 것을 의미하기에, 후반부는 중요도가 떨어지는, 낭비가 발생한다고 볼 수 있다.
2. Frequency Analysszis.
- 우측 그림은 각 layer의 Feature에 대해서 frequency domain의 amplitude를 확인하는 과정이다.
- 이 amplitude가 높다는 것은 특정 layer가 high frequency information을 더 많이 포착한다는 것이다.
- 즉 MAE는 High frequency를 shallow에서 사용하고, 1번 특징과 이어져, high-frequency 특징이 Reconstruction task에서 많이 사용된다고 보면 될 것 같다
즉 우리의 Original MAE는 low-level detail, high frequency information에 정보가 치우져 있다는 문제가 존재한다.
그리고 이 문제는 Low Linear probing accuracy로 이어진다.
4. Expectation.
- 따라서 이 문제를 해결하기 위해 shallow layer에 과도하게 집중하는 부분을 완화시켜서 deeper layer에서 low-frequency 부분을 집중하게 만드는 것이 목표이다.
- 저자가 주장하는 제안한 방법론은 Multi-level Feature Fusion (MFF)라고 불린다.
- 이 방법론은 기존의 MIM 방법론에 drop-in하게 (쉽게, 추가적인 작업 없이) 추가할 수 있다.
2. Related work.
- 생략.
3. Methods.
3-1은 저자가 자기가 쓴 논문 홍보하려고 쓴 내용이라 판단되기에 패스하겠다.
3-2 MIM with Multi-level Feature Fusion
- X = E(I), I∈ℝ^{HxWx3}. X는 latent representation이다.
- X = {x0, x1, ... x_N-2, x_N-1}으로 표시가 가능하며, 각각의 small x는 Original ViT의 latent space의 크기 정보와 같다.
- N은 encoder의 depth이다. 즉, X는 Image I를 입력으로 넣어서 가질 수 있는 모든 Representation space의 집합이다.
- 하지만, 이 모든 small x를 섞는 것은 optimize의 어려움을 겪기에, 최적의 M개를 찾아서 fusing을 진행한다.
- Shallow layer M=5개 + last layer까지 fusion해서 총 6개 layer를 fusing한다. (아래 그림 참조)
- 그래서 저자가 주장하는 것이, shallow layer의 feature를 fusion함으로써, 너무 많이 초점을 안둬도 된다고 주장.
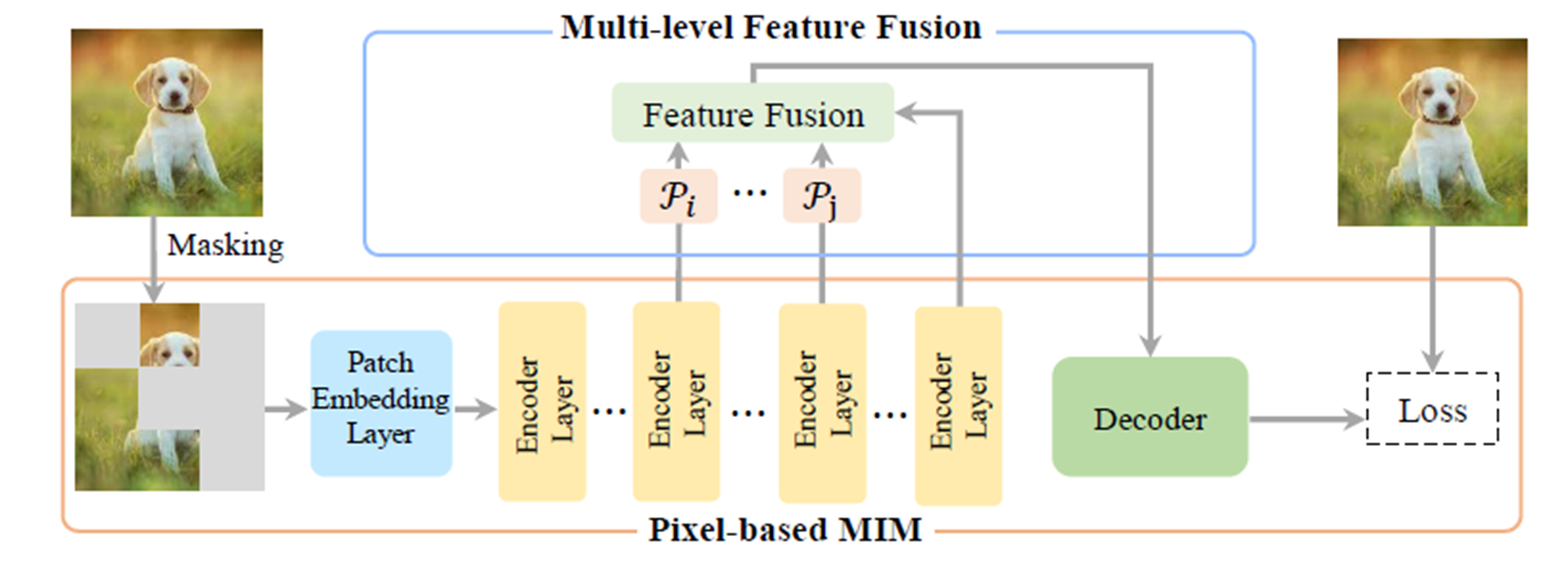
- ~X는 fusing된, Multi-level features이다.
- Pi는 projection layer로, Linear-GLEU-Linear 조합으로 이루어져있다.
- 𝒲는 selected layers의 indices이다. |𝒲|는 selected layers의 합이다. |𝒲|=M=5이다.


- fusion layer ℱ는 이전 Projection layer에서 얻은 정보 ~X 를 바탕으로 Decoder로 들어가는 Output O를 만들어낸다.
- fusion layer ℱ는 아래와 같이 2개로 구성이 될 수 있는데, 논문 저자는 왼쪽의 간단한 Simple weighted average pooling을 사용했다. 이 방법이 더 효율적이고, Cost또한 더 저렴하다.
- 아래의 수식에 weighted average pooling에 대한 표기는 따로 안한 것으로 보인다.
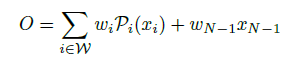

3.3. Instantiation of Projection and Fusion Layers
- Projection layer에 대한 설명은 위에서 했다. Pi = Linear-GLEU-Linear
- fusion layer ℱ에 대한 설명도 바로 위 섹션 참고.
4. Analysis


1. Frequency Analysis
- 앞서서 본 Figure2와 유사한 frequency amplitude분석이다.
- 마지막 layer의 feature frequency amplitude를 계산하였으며, 차이를 더 극명하게 보여주기 위해 log amplitude가 쓰인 것이 아닌, 그냥 amplitude가 사용이 되었다.
- high frequency amplitude는 더 낮아지고, low frequency amplitude는 더 증가한 것을 볼 수 있다.
- 이는 High frequency를 조금 희생시키면서 low frequency 를 더 잘 추출한다는 것을 의미한다.
- Deeper layer를 fusion 하는 방식을 제안하며 low frequency를 보완하는 방법을 도입했으므로 원하는 대로 low frequency를 잘 추출했다고 볼 수 있다.
2. Optimization Analysis
- MFF MAE의 Hessian max eigenvalue는 MAE보다 더 작은 것을 볼 수 있다.
- Hessian max eigenvalues는 loss함수의 곡률을 표현한다고 볼 수 있는데, 높은 Hessian max eigenvalues는 곡률이 크기에 Generalize가 어렵다는 것을 의미하며, 낮은 Hessian max eigenvalue는 평평한 loss landscape를 가진다고 보면 된다.
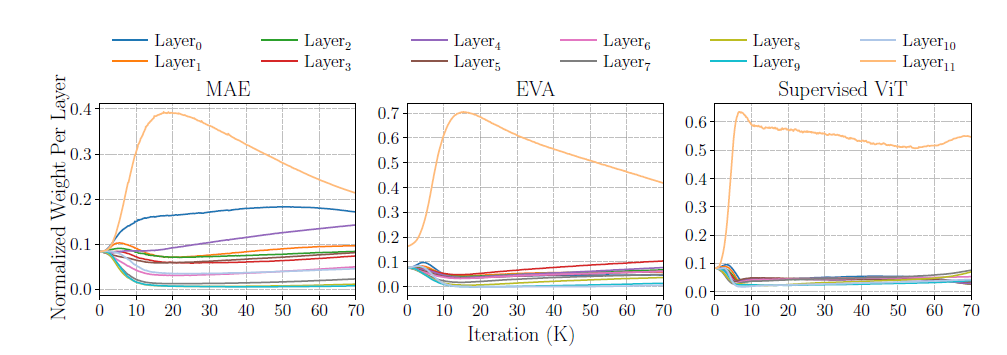
3. Feature Bias of Different Pre-training Methods
- 이 그림에서는 MAE와 EVA, ViT의 Normalized weighed per layer를 분석하였다.
- EVA는 CLIP을 사용해서 high-level features에 초점을 둔 대표적인 모델이다.
- ViT는 DeiT를 사용했다.
- 전반적으로 MAE를 제외한 다른 두 모델은 high frequency detail을 잘 추출하지 못한다.
5. Experiments


- 가볍게 요약하면 VIT-B, ViT-S에서 더 나은 성능을 보여주었다.

- 어디에서 fusion하는 것이 좋은지에 대한 설명



