Google for developers 에서 진행하는 ML Reading CLUB에 참여해 다양한 구글의 ML chatboot? LLM 모델을 읽어보고 각자 리뷰하는 시간을 가졌다. 1주차에는 Gemini 논문을 읽었고 추후에 2,3주차는 Gemma, Gemini-1.5를 리뷰할 계획이다.
원래라면 한번 읽어보고 생각을 공유하는 정도에서 마무리하려고 했는데, 다른분들이 내가 생각하는 내용과 다른 부분을 매우 꼼꼼하게 생각해주셔서, 그냥 잊어버리기엔 아깝다라는 생각과, 그리고 좀만 다음은 후, 정리를 해두면 나중에 오타와 대학과의 공동 저널클럽에서 한번 다룰 수 있지 않을까 싶어서 정리해두려고 한다.
영상: https://www.youtube.com/watch?v=CiVA8PmR2Do
제목: Gemini: A Family of Highly Capable Multimodal Models
저자: Gemini Team, Google
인용: 419 (2024.04.19 기준)
사실 Introduction은 건질만한 내용이 별로 없다,, 그래서 어떤 내용을 중점으로 봤는지 요약하자면
1. 본 내용은 AlphaCode2가 탑재되어 성능이 높았다는 것.
→ 거의 끝부분에 존재.
2. 각 모델 크기별 벤치마크 성능
++ 이 보고서에서는 당연하게도 Gemini가 더좋다고 하지만, 왜 체감상 OpenAI의 ChatGPT-4 혹은 3.5가 더 좋다고 느낄까
→ 성능 부분 첫번째 단락
3. Model architecture (근데 이 보고서에 너무 적어둔 내용이 없다),
→ 바로 아래의 Introduction 다음 존재.
4. 개인적인 Gemini의 후기로는 민감한 답변에 대해서 매우 엄격하다는 것인데, 이에대한 수치가 얼마정도 나올지, 아니면 왜 그런지에 대한 기술을 보고자 함. 특히 Hallucination에 대해 왜이리 엄격한 것인지 확인해보고 싶었음.
→ 전반적으로 왜 그런답을 하는지에 대한 힌트가 군데군데 존재.
요약 해보자면, Gemini가 좋다라고 하지만 정작 좋은 Ultra는 공개가 되지 않았으며, 성능이 높은 이유도 CoT(Chain of thought)을 적용할 때만 더 나은 모습을 보여준다. 더 나아가 Hallucination을 억제하기 위한 많은 시도를 하였으며, 이에 답변이 좀 답변에 성의가 없달까,, 좀 엄격한 모습을 보여준다. 굳이 이 Gemini를 써야겠다라고 생각이 든다면, Code의 디버깅이나 프로그램을 만드는 개발자 입장에서는 Alphacode 2를 결합했기에 코딩용으로는 더 좋지 않나 라고 생각한다.
Abstract.
Model Introduce: Gemini 라는 새로운 Multi-modal계열의 모델이 소개, 이는 image, audio, video, text 이해에 걸쳐 뛰어남.
Model configure: Ultra, Pro, Nano 세 가지 크기로 제공, 복잡한 추론 작업부터 메모리 제약이 소형기기에서의 사용 가능.
Performance: Ultra 모델은 2개 중 30개의 벤치마크에서 SOTA. MMLU 시험에서는 인간 전문가 수준의 성능 최초 달성
Application and Deployment:
1. 이 모델들은 교차 modality 추론 및 언어 이해 능력을 통해 다양한 사용 사례를 가능하게 할 것.
2. 제미니는 Google AI Studio와 Cloud Vertex AI를 포함한 여러 서비스를 통해 사용자에게 책임 있게 배포될 계획.
Introduction.
Introduce and Goal
- Gemini는 구글에서 versatile multi-modal 모델 계열을 만드는걸 목표로, 이미지, 오디오, 비디오, 텍스트 데이터를 통합하여 훈련하였고 모델 구조인 Section 2에 설명이 나온다.
- 모든 modality 분야에서 강력한 일반적인 능력과 각 도메인에서의 최첨단 이해 및 추론 성능을 목표.
Model inspection.
1. 첫 번째 버전인 Gemini 1.0은 복잡한 작업용 Ultra
2. 확장된 성능 및 배포를 위한 Pro
3. 소형 기기 내 응용 프로그램을 위한 Nano
Training // Post training methods
1. 대규모 Pre-training 후,
2. 포스트 트레이닝을 실시 (목적은 아래와 같다).
- 1. 모델의 전반적인 품질을 향상
- 2. 특정 기능을 강화,
- 3. 안전성과 일치성 기준을 충족
3. 다양한 하위 응용 프로그램 요구에 맞춰 두 가지 post training 모델 변형을 생산. (아래 참조)
4. 아 이 post training은 fine-tuning과는 약간 다르다.
- 기능 향상: 코딩 또는 다국어 기능과 같이, 특정 유형의 작업에서 더 나은 성능을 발휘하도록 모델을 조정
- 안전 및 정렬: 윤리적 지침 및 안전 표준, ex) 인종차별질문에 답 안하도록 보장, 개인 정보 보호, 공정성/신뢰성 처리
- 다양한 애플리케이션을 위한 변형: 대화형 AI(Gemini Apps 모델) 혹은 개발자 중심 애플리케이션(Gemini API 모델)
Performance
- Gemini 모델은 내부/외부 벤치마크의 광범위한 세트에서 평가되며, 언어, 코딩, 추론, 멀티모달 작업에서 평가.
- Gemini Ultra 모델은 다양한 벤치마크에서 인간 전문가 수준의 성능을 달성 및 SOTA 달성.
Training and Applicability
- Gemini 모델의 멀티모달 추론 기능을 사용하여 복잡한 문제를 이해하고 해결하는 예시를 제공.
ex) 물리학 문제를 해결하는 시나리오에서 모델은 문제를 올바르게 이해하고 수학적으로 변환하여 올바른 해결책을 제공.
(아래 이미지 참조)

Prospect
- AlphaCode 2와 같은 새로운 에이전트를 통해 Gemini 모델의 추론 능력을 활용, 이는 프로그래밍 문제를 효과적으로 해결
- 또한, Gemini Nano 모델은 소형 기기 내 작업에서 좋은 성능 보여줌.
Architecture
Basic architecture
- Gemini 모델들은 향상된 트랜스포머 디코더를 기반으로 구축
- Google의 텐서 처리 장치(Tensor Processing Units, TPU)에서 추론을 가능하게 하는 아키텍처 개선/모델 최적화가 적용.
- 또 한가지 그래도 유의미해보이는 특징은 Multi-query attention을 사용했다는 점.! (왜 썼는지는 안나왔다)
Input & Output
- 이 모델들은 텍스트와 함께 자연 이미지, 차트, 스크린샷, PDF, 비디오 등 다양한 오디오 및 Visual Input 처리 가능.
- 모델은 텍스트와 이미지 출력을 생성할 수 있으며, 비주얼 인코딩은 Flamingo, CoCa, PaLI의 기반으로 함.
Multi-modal capability
- Gemini는 비디오를 대규모 컨텍스트 윈도우에서 프레임 시퀀스로 인코딩하여 비디오 이해를 달성.
- 비디오 프레임이나 이미지는 모델 입력의 일부로서 텍스트나 오디오와 자연스럽게 결합될 수 있다.
Audio Processing
- 16kHz에서 Universal Speech Model의 신호 처리할 수 있으며, 텍스트로 단순히 매핑될 때 손실되는 뉘앙스를 포착가능.
Model size and characteristic
- Gemini 1.0은 다양한 응용 프로그램을 지원하기 위해 세 가지 주요 크기(Ultra, Pro, Nano)로 제공.
- Pro 모델은 인프라(TPU)와 학습 알고리즘의 확장성을 활용하여 몇 주 안에 사전 훈련을 완료 가능,
- Nano 시리즈는 추가적인 Distillation/training algorithm 활용하여 다양한 작업에 적합한 소형 언어 모델을 생산
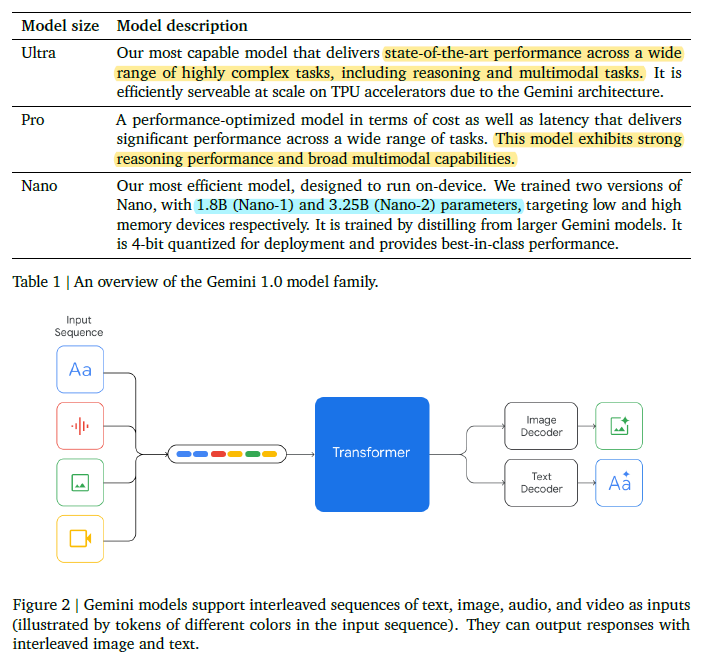
- 실제로 Gemini에 PDF나, 이미지, 텍스트를 동시에 넣을 수 있는 것 처럼, 이러한 동작 매커니즘의 비결은 위와 같이 토큰 형태로 쪼개서 입력이 들어간다는데에 있다.
- Nano의 경우는 위의 테이블과 같이 실제 파라미터 수를 명시 해 두었으며, 생각보다 작은 크기를 보여준다.
Training Infrastructure
1. 하드웨어 및 구성: Gemini 모델은 TPUv5e 및 TPUv4를 사용하여 훈련.
2. 네트워크 인프라 및 통신: TPUv4 가속기는 4096개의 칩으로 구성된 ‘SuperPods’에 배치되며, 이들은 전용 광 스위치에 연결되어 약 10초 만에 임의의 3D 토러스(topologies)로 동적 재구성이 가능.
3. 프로그래밍 모델 및 컴파일러: Single controler 모델을 사용하여, 하나의 Python 프로세스가 전체 훈련 실행을 조정.
4. GSPMD 파티셔너와 MegaScale XLA 컴파일러는 훈련 단계 계산을 분할하고 적절한 콜렉티브를 정적으로 스케줄링하여 계산과 최대한 겹치게 하여 훈련진행.
5. 데이터 안전 및 복구 전략: 기존의 주기적인 체크포인트 저장 방식 대신, 모델 상태의 중복 메모리 복사본을 사용하여
-> 하드웨어 장애가 발생해도 PaLM 및 PaLM-2에 비해 빠르게 복구 가능
6. 시스템 실패 모드 및 SDC 대응: 대규모 훈련은 시스템 실패 모드가 많기에, 특히 ‘Silent Data Corruption (SDC)’과 같은 문제를 결정적 재생과 능동적 SDC 스캐너를 사용하여 잘못된 하드웨어를 신속하게 감지하고 제거
Pre-Training Dataset
Dataset configuration.
- Gemini 모델은 web document, pdf, image, book, code 등을 포함하는 다양한 멀티모달 및 다국어 데이터로 사전 훈련.
Tokenizer.
- SentencePiece 토크나이저를 사용,
+ 이 sentencePiece 토크나이저가 Pro급에 쓰일만큼 좋은 토크나이저가 아닌데, 어떻게 쓰였는지에 대한 의문 존재.
++ 특히 많은 토큰 수와 함께, 메모리 문제를 어떻게 해결했는지에 대한 의문 존재.
- 전체 훈련 코퍼스의 큰 샘플에 대한 훈련을 통해 추론된 어휘를 개선하고, 이는 모델 성능, 훈련 속도, 추론 속도를 향상
- 특히, 비 라틴 문자 스크립트의 효율적인 토크나이징이 가능.
토큰 사용 및 모델 성능:
- 가장 큰 모델의 훈련에 사용된 토큰 수는 Chinchilla의 scaling 법칙을 따름
- 작은 모델은 주어진 추론 예산에 대한 성능을 향상시키기 위해 더 많은 토큰으로 훈련.
데이터 필터링과 안전성:
- 모든 데이터셋에 Heuristic 규칙과 모델 기반 분류기를 사용하는 품질 필터를 적용,
- 해로운 내용을 제거하기 위한 안전 필터링을 수행.
- 평가의 무결성을 유지하기 위해 훈련 데이터 사용 전에 훈련 코퍼스 내 평가 데이터를 검색하여 제거.
데이터 믹스 및 훈련 단계 조정
- 최종 데이터 믹스와 가중치는 작은 모델에서의 소거 실험을 통해 결정 (누가 이걸 모르냐;;)
- 훈련 중 데이터 혼합 구성을 변경하여, 훈련의 끝에 가서 도메인 관련 데이터의 비중을 증가시킴.
- 데이터 품질이 고성능 모델에 중요하다는 것을 발견하고, 사전 훈련을 위한 최적의 데이터셋 분포를 찾는 데 여전히 많은 관심이 있음.
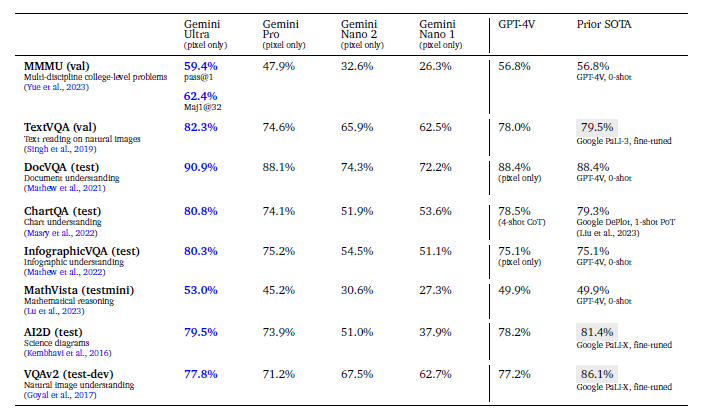
성능
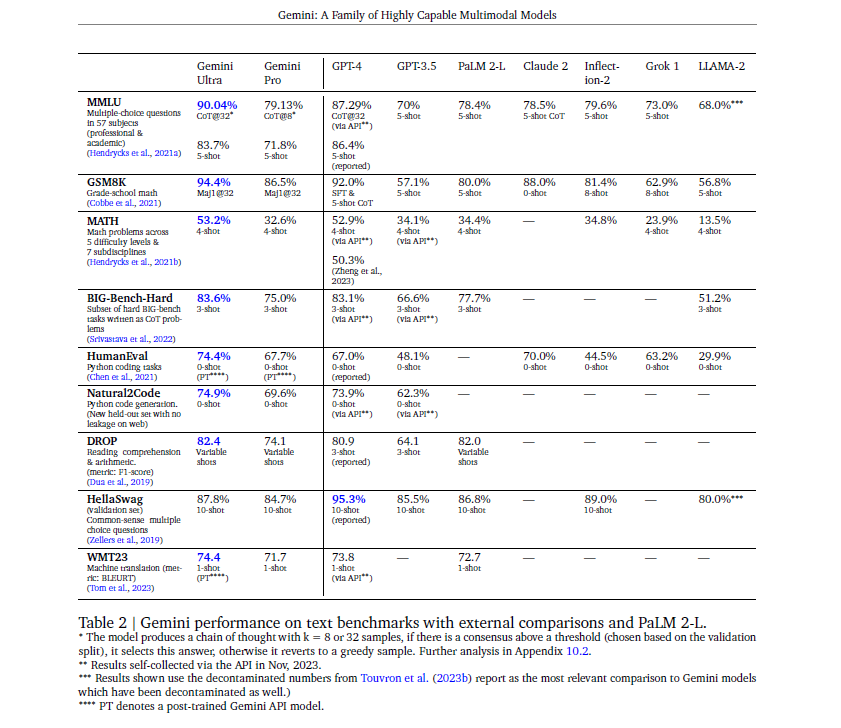
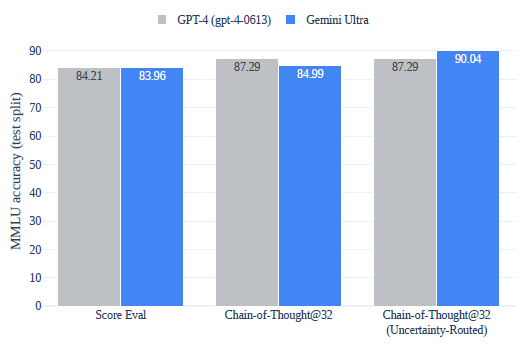
- 우선 Gemini가 표 상으로 보기에는 GPT-4보다 뛰어나다? 라는 생각이 들게 만들지만, 실제 Gemini Ultra는 공개가 되지 않았기에 사용감은 GPT-4가 당연히 더 좋다라고 느끼게 되며, 실제로 3.5와 Gemini-pro를 비교해본다고 하더라도, 정말 그정도로 뛰어난가? 하는 의문을 가지게 한다.
- 필자는 이 우측 그림을 해석할 때, 아무리 GeminiUltra가 GPT-4보다 좋다고 하더라도, 실제 사용감은 별로일 것이라 예측했는데, 그 이유는 애초에 기본적인 score가 우측 그림에서 더 낮기 때문이다. chain of thought을 적용해도 낮을 뿐더러, 실제 사용자는 chain of thought 기술을 잘 활용하지 않기 때문이다.
- Gemini ultra에 대한 사용을 조금만 풀었어도 더 많은 것을 분석할 수 있다 생각했지만, Ultra의 정보는 아직도 미지수이다
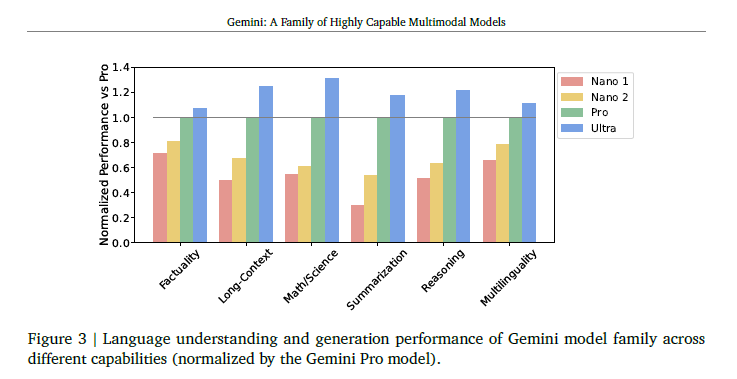
- Gemini pro를 기준으로 한, Gemini nano와 Ultra의 상대적인 성능 수치
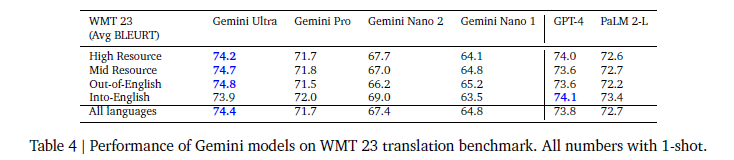
- 아래는 문장 번역 테스크에서의 성능을 보여준다. Into-English에서는 가장 좋은 모습을 GPT가 보여주기에, 그리고 일반적이라고 생각되는 Gemini pro또한 GPT-4보다 낮기에, 그냥 GPT를 쓰는 것이 더 낫지 않나 라고 생각을더 심어준 테이블이다.
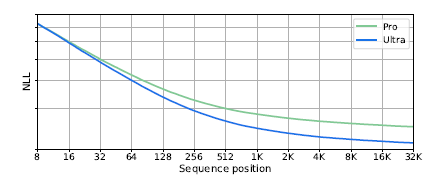
- 이 이미지는 토큰 수에 따른 NLL loss를 시각화 한 것인데, 32k의 아주 긴 sequence length token에 대해서도 여전히 좋은 loss function 그래프를 보여준다.
그리고 Faculty
1. Closed-Book Factuality:
Gemini API 모델은 출처 없이 제공된 사실 탐색 프롬프트에 대해 잘못된 정보를 생성하지 않아야 함.
ex) "인도의 총리가 누구인가요?"와 같은 정보 탐색형 질문뿐 아니라 "재생 에너지 채택을 지지하는 500단어의 연설을 작성하시오"와 같은 반창조적 요청까지 다양하게 적용됨.
2. Attribution:
주어진 맥락에 기반하여 응답을 생성하도록 지시받은 경우, Gemini API 모델은 맥락에 충실한 응답 생성하도록 함.
ex) 이는 사용자 제공 출처의 요약, 질문에 대한 인용 생성, 책과 같은 장문의 소스에서 질문에 대답하거나 주어진 소스를 원하는 출력으로 변환하도록 함.
3. Hedging:
“대답할 수 없는” 입력에 대해 프롬프트되었을 때, Gemini API 모델은 대답을 할 수 없다는 것을 인정/
++ hallucination을 피하기 위해 언급하는 것을 포함
ex) 입력이 거짓 전제 질문을 포함 or 맥락에서 답을 도출할 수 없음에도 개방형 QA 수행을 지시하는 경우가 포함

AlphaCode 2
- AlphaCode 2는 Gemini Pro를 기반, 프로그래밍 데이터 만드는데 특화된 버전으로 튜닝. 가장 유망한 코드 후보를 식별
- AlphaCode 2는 Codeforces 플랫폼에서 12개 대회의 77개 문제를 대상으로 평가되었으며, 이 중 43%를 해결하여 이전 시스템인 AlphaCode의 25% 해결률보다 1.7배 향상된 성능을 보였음.
- 이는 경쟁 순위에서 평균 85번째 백분위로, 참가자의 85%보다 더 뛰어남.
Vision 모델의 성능.