제목 : IMAGEBIND: One Embedding Space To Bind Them All
저자 : Rohit Girdhar et al.
소속 : FAIR, Meta AI
학회 : CVPR2023
인용 : 38 (Until 2023.10.20)
링크: https://imagebind.metademolab.com/
안녕하세요! 제가 오늘 소개할 논문은 "IMAGEBIND: One Embedding Space To Bind Them All" 라는 논문입니다. Facebook AI Research, Meta AI에서 만든 논문입니다. 이 논문은 CVPR 2023에 등재 되었습니다.
이 논문 같은 경우에는 2023년 3월에 처음으로 등장하게 되었는데요. 이 논문이 처음 나왔을 때 레딧라든지 텔레그램과 같은 그런 딥러닝 소식을 전달하는 커뮤니티에서 굉장히 핫한 그런 토픽/논문으로 소개가 되었습니다.
Multi-modality라는, Image와 Text 데이터를 같이 활용을 하는, 혹은 이처럼 다른 두개의 데이터 셋을 활용하는 분야인 Multi-modality라는 분야에서, 이 ImageBind는 이 두 개의 Modality 뿐만 아니라, 그 외에도 다양한 Modality를 합쳐서 좋은 성능을 보여주었습니다.
Multi-modality 분야에 관심이 있다면은 혹은 최근 Computer vision 분야, 그리고 그 외에도 Natural Language Processing, Audio 등 내 관심 분야가 어떻게 적용이 되고있냐라고 하면 모두 포함이 된다고 생각이 들기에, 이 논문을 한번 소개시켜드리고 싶어서 이 논문을 가져오게 되었습니다.
이 Tistory에서는 논문의 내용을 요약하는 형식으로 정리를 할 예정이고, 가볍게 보시고 싶다면 Medium에서 보시는 것을 추천드릴게요! (다만 영어로 작성되었습니다.)
0. Demo
https://imagebind.metademolab.com/
ImageBind by Meta AI
A multimodal model by Meta AI
imagebind.metademolab.com
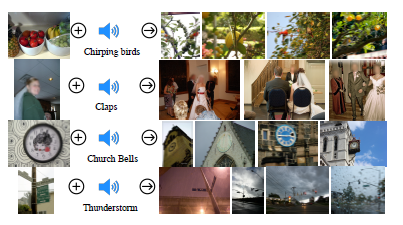
우선, 이 링크에서 Demo를 보면 여러가지 귀여운 사진과 오디오가 등장합니다.

총 5개의 section이 존재하며, 다양한 동물 사진이 있고 이 동물 사진을 누르게 되면 이와 가장 관련이 있는 오디오와 그에 대한 거리를 보여줍니다.
- 반대의 경우도 마찬가지로, Audio를 바탕으로 이와 가장 관련이 이미지, 이와 가장 Embedding space에서 가장 가까운 이미지를 가져와 줍니다.
- 또한 Audio-Image외에도 Text-Audio&Image도 매우 유사한 모습을 보여줍니다.
- 그리고 Embedding-Space arithmetic이라고 불리는, Embedding space 내의 vector 값들을 더하거나 빼는 작업을 통해, 그 거리만큼 특징이 더해해졌거나 빼진 새로운 정보를 제공하는 것 또한 가능합니다.
- 그리고 Audio를 통해 Text를 생성하고, 이를 바탕으로 DALLE-2에 입력으로 넣어 매우 관련이 있는 새로운 이미지를 만드는 것 또한 가능합니다.
1. Abstract.
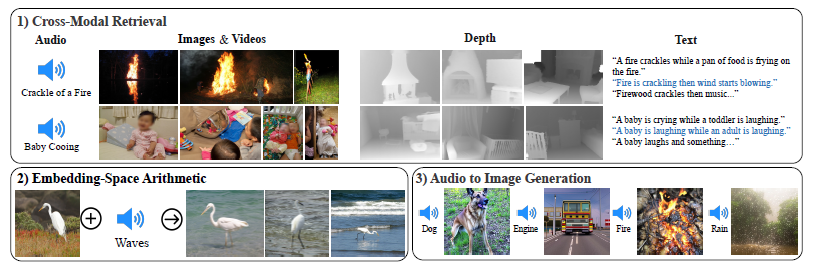
- image, text, audio, depth, termal, IMU와 같이 총 6개의 modality를 하나의 embedding space에 처리하는 것을 보여주며, 이 6개의 modelaity data pair쌍이 모두 모이지 않아도 된다는 것을 보여준다.
- ImageBind는 image를 활용한 pairing을 통해 audio분야에서의 강력한 zero-shot capabilites를 보여준다. (SOTA)
- Cross-modal retrieval이 별다른 fine-tuning없이 "바로" 나타나며 (1번), modelities with arithmetic한 one-embedding space를 보여준다. 이는 DALLE-2를 이용한 Audio to Image generation으로도 이어진다.
2. Introduction
- 해변을 보면,파도 소리를 들을 수 있고, 산들바람, 그와 관련된 시 등, 이러한 "binding property"는 많은 visual features가 다양한 정보를 제공할 수 있다는 것을 의미한다. 실제로 이런 Modality를 전부 가진 데이터를 모으는 것은 불가능하다.
- Image-text, Image-audio 등 여러가지 Multi-modalities를 사용하려는 시도는 많아왔지만, Image-text embedding이, video-audio embedding에 바로 사용되지 못하는 것처럼, 가장 큰 문제는 이러한 large quantities of multimodal data를 함께 넣는 것이 불가능하다는 것이다.
- 따라서 ImageBind에서는 Image를 기준으로, (Image,text), (Image depth), (Image, Thermal) .. ect와 같이 이미지를 기준으로 single joint embedding space를 구축한다.
- 또한 CLIP (Contrastive Language-Image pre-training)을 구조를 (Image,text)를 바탕으로 모든 Modality를 활용하여 강력한 zero-shot classification & retrieval 효과를 제시한다.
- Figure 1에서 볼 수 있는 것 처럼 cross-modal retrieval, arithmetic embedding, detecting audio sources in image and audio를 통한 generating images와 같이 다양하게 응용할 수 있다.
3. Related work.
- 논문의 내용을 요약하기 보단, 제가 직접 Google for Developers Machine Learning Meetup 행사에 참여하여 사진찍은 내용을 수정하여 보는 것이 더 낫다고 판단이 들어, 이 사진을 첨부한다.
- 화질구지라 약간의 디자인 수정을 하였다.
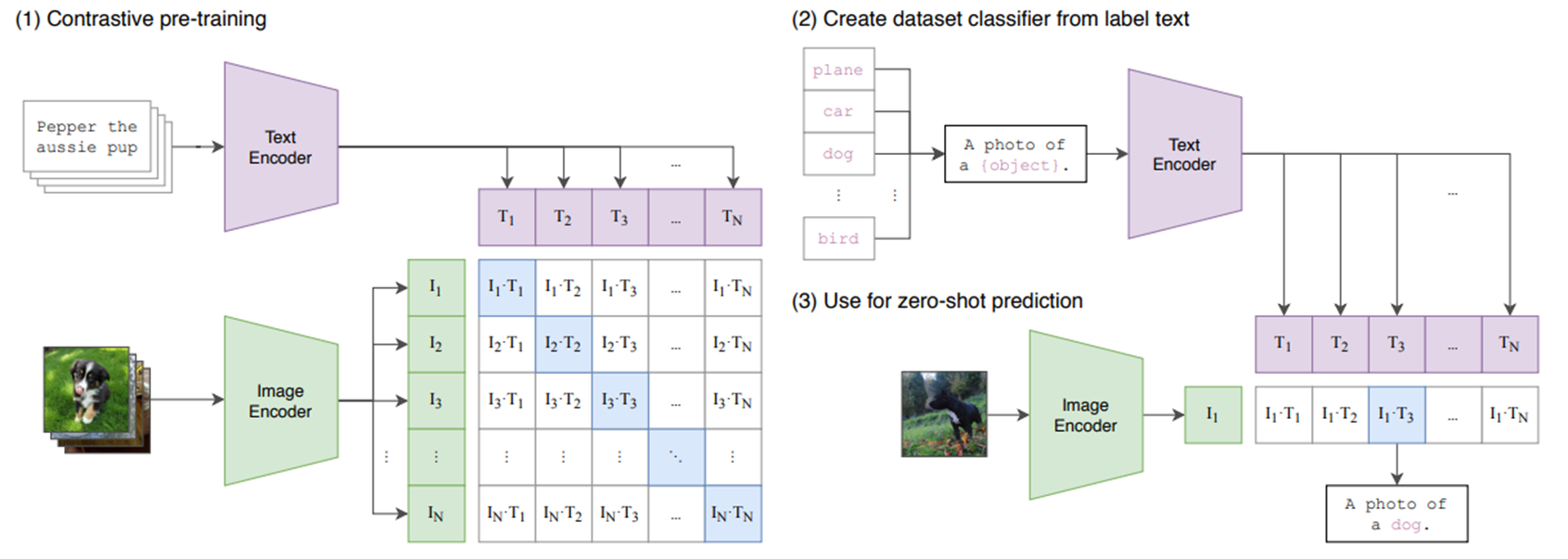
- 아래의 그림은 CLIP의 구조이다. 각각의 Modality에 대한 Encoder가 존재하며, 이를 압축한 후, 같은 크기의 feature vector를 만들어 낸 후, similarity matrix를 만들어 낸다. 대각선 부분은 자기 자신과 같은 index이기에, positive area라고 불리며 아래에 등장하는 InfoNCE loss 내부의 분자에 해당하여, 유사도를 높게 만들고, 나머지 부분은 낮게 만든다.
- 그리고 Zero shot prediction을 위해 (2)번은 fine-tuning을 하는 과정이라고 보면 되며, 마지막으로 입력 이미지를 넣어서 zero-shot prediction을 진행한다.
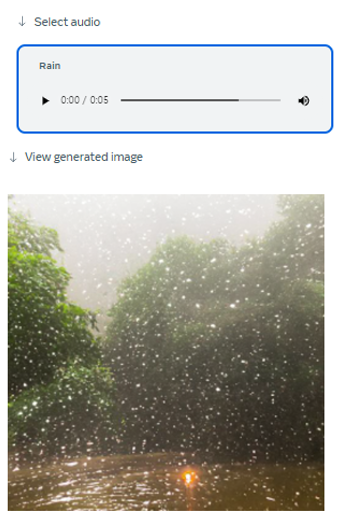
4. Method

- ImageBind의 가장 큰 목적 중 하나는, 이미지를 바탕으로 이 6개의 Modalities를 학습하는 것이다. 위의 Figure 2를 참조하여, (Image, Text), (Image, Depth), (Image, Video) and (Image, Thermal) 을 묶고 (Video, Audio), (Video, IMU)를 묶어서 한번에 입력으로 집어넣는다.
- 기존의 Multi-modality의 경우, 이러한 데이터들을 한번에 모으는 것이 어려우며, (Video, Audio) > (Image, Text)로 적용이 되는 것이 불가능했다.
- 또한 기존의 CLIP base의 Zero shot classification은 paired text를 사용해야한다는 점이 있었지만, ImageBind는 이 paired text data 없이 가능하게 만들었다.
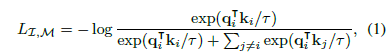
- Loss function은 InfoNCE loss를 사용했다. 여기서 I는 Image modality를, M은 다른 Modality를 의미한다.
- 두 Modalities의 내적을 통해 유사도를 구하고, 유사도가 높을경우 가까운 거리에 mapping, 낮을경우 서로 먼 거리에 mapping하는 방법론이다.
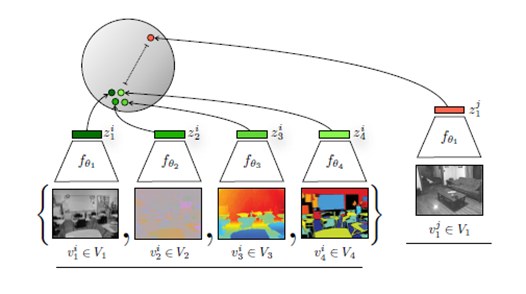
- 이러한 과정은 위와 같이 그림으로 나타낼 수 있는데, 실제 ImageBind의 동작 방식과 매우 유사하다고 볼 수있다.
- 각각의 Augmented 이미지는 각각의 Modality가 된다고 생각하고, fθ1, fθ2 .. 이 각각의 feature vector를 만들어낸다고 생각하면 될 것 같다. 그리고 이 feature vectore를 통해 유사도를 구하는 InfoNCE loss를 구하고 같은 Modality끼리는 최대한 가깝게 매핑하려고 시도한다.
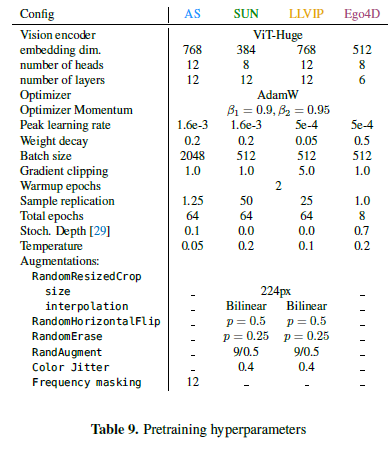
- Implementation detail은 아래의 hyper-parameter setting을 참고하자.
5. Experiment
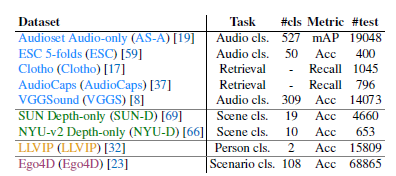

- 우선 왼쪽의 등장하는 데이터 셋 들은 zero-shot classification에 사용 된 데이터 셋 이다.
- ImageBind는 CLIP과 유사하게 (Image, text)는 Web-scaled 데이터로 4억장이 학습이 되었으며, 그 외에 데이터 셋은 Audio를 제외하고 왼쪽 위에 표기된 (파란색 제외) 데이터 셋들이 쓰였다고 보면 될 것 같다.
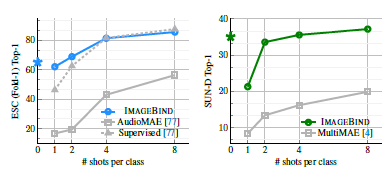
- 이 그림은 few-shot learning에서 supervised learning AudioMAE와 self-supervised AudioMAE를 ImageBind와 비교하였을 때의 성능차이를 보여준다. 기존의 Audio 분야의 SOTA인 AudioMAE를 작은 shots에서 앞서는 모습을 보인다.
- Embedding-Space arithmetic 이란? Vector 공간에서 의미론적 관계를 표현하는 능력.
- NLP에서는 King - Man + woman = Queen 이 되는 embedding space를 구축하는 것을 시작으로, GAN에서 Interpretable Vector Math이라는 것을 통해 “웃는 여자 – 일반 여자 + 일반 남자”를 활용하여 웃는 남자를 만들어 낼 수 있다.
- 이는 embedding에서 space에서 다양한 의미론적 변화나, 상관관계를 매핑하기 위해 노력했으며, 이는 Multi-modality를 고려하는 one-embedding space로 확장 하였을 때도 동일하다.
++추가적으로 OpenAI는 데이터 수가 증가함에 따라 성능이 올라간다는 내용 또한 밝혔다.
6. Conclusion
Goal (Objective)
- 웹 스케일 이미지 데이터 세트 및 다양한 Multi-modality 데이터 셋을 기반으로, 6개의 Modality를 One-embedding space에 통합한 모델을 개발.
Contribution
- IMAGEBIND는 Multi modality를 통제하기 위한 하나의 embedding space를 생성하여 다양한 modality를 embedding space에서 통합한다.
- IMAGEBIND를 통해 Audio&Text Zero-shot benchmark에서 최첨단(SOTA) 결과를 달성한다.
Problem
- 3개 이상의 Multi modality의 구성은 일반적으로 모든 modality에 걸쳐 완전한 데이터를 필요로 하며, 이는 종종 다양한 제약 및 한계로 인해 실행 불가능(infeasible)하다.
Methods (Experiment setup)
1. Image 중심의 Training data 구축 및 Image에 대응하는 Modality 데이터만 준비하면 된다.
2. 모델은 InfoNCE loss을 기반으로 CLIP에서 사용하는 방법론을 사용하여 훈련된다



