이번에 정리해볼 논문은 ALBEF이다. 기존의 Multi modal이라는 분야에서 두 개의 다른 특징을 다른 입력 데이터를 다른 두 개의 모델을 사용해 최적화 하는 이 분야는, 최적화가 어렵다는 단점이 있다. 나는 수면 분야에서 이러한 Multi modality를 결합해보려고 시도하고 있는데, 최적화 문제를 마주쳤기에 간단한 방식으로 이 문제를 해결한 ALBEF를 정리하며 오랜만에 생각 정리도 하고, 교수님과의 디스커션도 준비하고, 생각 정리도 할겸 오랜만에 정리를 해보려고 한다.
논문 링크: https://arxiv.org/abs/2107.07651
제목 : [ALBEF] Align before Fuse: Vision and LanguageRepresentation Learning with Momentum Distillation
저자 : Junnan Li et al.
소속 : Salesforce Research
학회 : NIPS2021
인용 : 1021 (2024.01.27 기준)
사용 데이터 셋: UNITER (noisy dataset)

우선 이 ALBEF이 제기하는 점은 visual token과, word token 들이 unalign하다는 점을 제기하며, 이 둘이 상호작용하는 것이 어렵다는 문제를 제기한다. 따라서 ALBEF (Align before fuse)라는 방식을 제안하며, Cross-modal attention을 바탕으로 vision분야와 Language representation learning "more grounded"하게 근거 있게 Fusing할 수 있음을 보여준다.
추가적으로 ALBEF에서는 noisy한 web dataset에서 좋은 성능을 보여주기 위해 pseduo-target을 제공하는 momentum distillation이라는 방법론도 제시한다.
Drawbacks.
1. Image feature와 word token embedding은 사이의 정보는, 다른 공간에 존재하기에 상호작용하기 어렵다.
2. 기존 VLP 분야에서 사용되는 Object detector -> annotation-expensive + compute expensive. why? their bounding box 혹은 Higher resolution 문제 때문.
3. image-text dataset은 매우 noisy하기에, MLM 같은 작업에서는 불필요한 정보를 학습할 수도 있게 된다.
Solutions.
1. MoD (Momentum Distillation): noisy한 환경에서 더욱 좋은 supervision/pseudo-label을 만들기 위해서 도입.
2. ITC and MLM loss에 대한 mutual information maximization이 적용이 된다는 것을 수식으로 증명.
MoD (Momentum Distillation)
- noisy한 환경에서 더욱 좋은 supervision/pseudo-label을 만들기 위해서 도입.
- moving average를 사용하여 학습된 모델을 바탕으로 pseudo-target을 additional supervision으로 도입.
-> Web data의 적힌 label과 다르지만, 더욱 효과적인 pseudo label 만들 수 있음.

ALBEF의 동작과정은 다음과 같다.
1. ITC (Image-Text Contrastive Learning loss) 를 계산하는 부분
2. Fusing을 위한 Cross-Attention layer.
3. Masked Language modeling을 수행하는 부분
4. ITM (Image-Text Matching loss)를 계산하는 부분.
ITC loss function
우선 projection된 p들은 다음과 같이 나타낼 수 있다. 수식에서 tau는 learnable temperature parameter이다.

그리고 s(I,Tm)는 그 반대의 경우는 아래와 같이 표기할 수 있다. 추가적으로 ALBEF는 뒤의 오는 embedding feature에 대해서만 normalize를 진행했다. 이렇게 할경우 비교 대상인 Feature에 대해서 coagulate된 feature들이 만들어지기에, 조금 더 유사성을 가질 수 있으며, 비교하고자 하는 feature에 대해서는 유지하는 이유는 이 반대의 이유로 여러가지 특징을 보존하기 위해서지 않을까라고 생각이 든다. (혹시 기 기술이 어디서 기원됐는지 아시는 분 있으면 댓글 부탁드립니당)
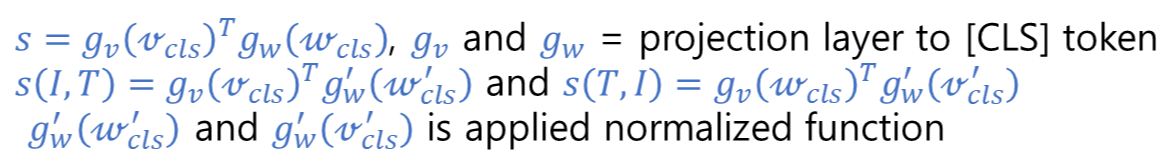
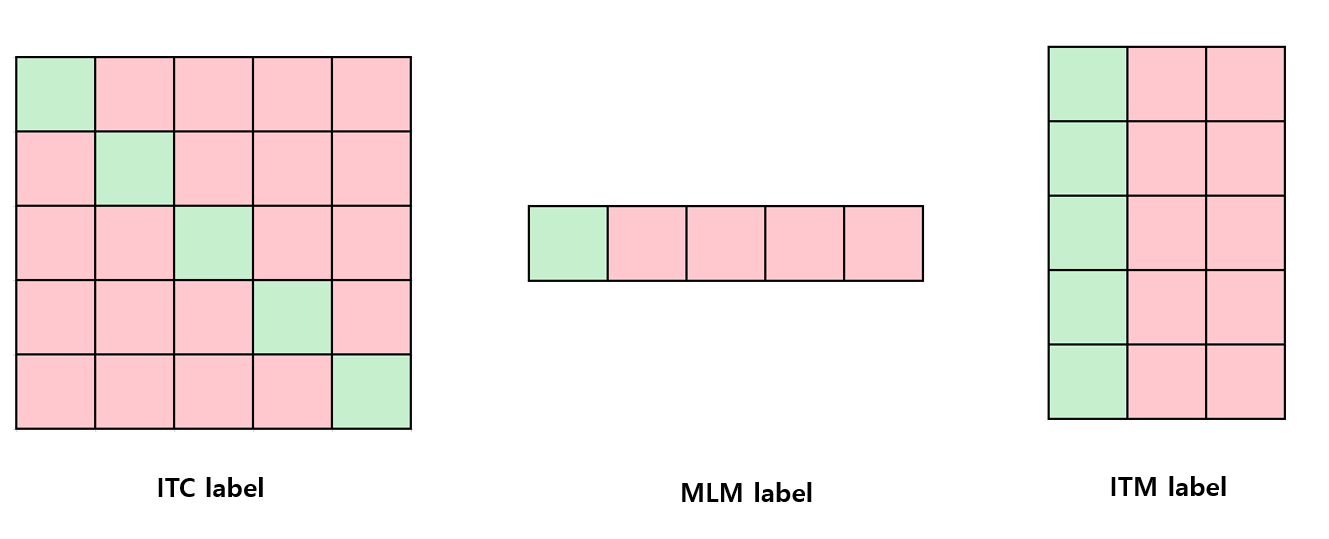
이렇게 하여 ITC loss는 아래와 같이 정의가 된다. H는 Cross entropy인데, 여기서 정답 레이블을 바탕으로 one-hot similarity matrix를 만들고 (대각선 1, 나머지 0), 이를 바탕으로 softmax함수가 정답이 되고, 나머지 부분은 대각선에 채우는 방식을 선택했다. 우측 상단 그림을 약간 참조하면 어떤 느낌인지 감이 올거라 생각한다.

MLM loss function
우선 MLM loss function의 수식은 아래와 같으며, Masking 비율은 15% 정도이다. T^hat은 masked text로, Masking 된 부분에 대해서만 예측을 수행했다. H는 마찬가지로 Cross entropy loss 이며, 이번에는 one-hot vocabulary distribution이다. 위와 아래에 대해서 똑같은 CE지만 형태가 다른 이유는, MLM은 단어 예측이기에 (해당 단어가 올 확률) / (Vocalbulary len)이며 ITC는 서로 다른 두 embedding vector간의 같은 class 정보를 최대화 시키기 위해 Matrix형태로 만들어 취급한다.

ITM loss function
우선 이 ITM loss는 유사한 의미를 공유하지만, fine-grain한 세부사항에서는 차이가 있는 Image-text쌍에 대해 구별하기 위해 사용하는 Loss이다. Contrastive similarity를 통한 image와 가장 유사한 text가 negative sample이 결정이 되고, 반대의 경우도 따져보기에, 1:2 비율의 pos:neg 샘플을 뽑아서 진행한다.
위의 Figure 1을 보면, Joint encoder를 통과한 output vector의 CLS token을 "image-text pair의 representation"으로 취급하고 MLP layer를 추가해서 softmax probability를 만든다. 그 후, Align된 부분에 존재하는 부분을 바탕으로 Contrastive similarity를 구하고 나머지는 위에서 설명한 것과 같다.

코드는 아래와 같다. 1:2 비율의 pos:neg는 코드에서 확인할 수 있다. itm_head는 nn.linear(text_width ,2) 크기의 MLP layer이다. 아 그리고 여기서도 2차원 크기의 label matrix를 사용하는데, 방식은 ITC와 약간 다르다.

이렇게 해서 등장한 Full pre-training objective는 아래와 같다.

Momentum Distillation
momentum model? : teacher-student 구조에서 teacher가 EMA를 통해 지속적으로 업데이트 되는 모델
- Web data는 매우 noisy하기에, 아래와 같은 문제가 발생한다.
ITC learning:
Positive pair는 weakly correlated한 문제 -> Image와는 상관없는 text, 혹은 text와 상관없는 이미지 등장.
반대로 Negative pair에서도 Positive pair처럼 유사한 Image-text가 등장가능.
MLM: learning:
Mask된 부분의 단어를 예측했는데, 기존의 정답보다 더 잘 설명하는 Masking단어 존재 가능.
-> 종합적으로 One-hot label을 둘 다 사용하기에, 둘 다 Negative sample에 대해서 정확도와 관계없이 penality를 줌.
이를 해결하기 위해 우선 s'를 정의해주고, 위와 차이점이 있다면 처음으로 들어가는 embedding vector에 대해서도 normalize를 해준다. 아무래도 pseudo-label로 들어가다보니 안정성을 제공하기위해 이런 행동을 한 것 같다.

다음과 같은 최종적인 ITC loss가 들어가게 되는데, 이는 q에서 사용되는 ITC loss가 s -> s'로 바뀌는 것 말고는 없다.
최종적으로는 embedding feature와 Label matrix간의 CE에서 momentum과 embedding feature를 비교하는 KL loss로 바뀌는게 끝이다.

이와 유사하게 Masking 부분도 momentum encoder를 사용해서 업데이트 한다.
alpha = 0.4 정도로 1/(1-a) 로 근사를 해보면, 1.67xx 정도이다. 즉 1.67 effective window 크기를 가지고 있다고 이해하면 되겠다. 이는 batchnormalization에 사용되는 EMA a = 0.99와 비교하였을 때, 매우 작은 수치이다. a=0.99일 때, effective window의 크기는 100으로, 꽤 많은 양의 과거 weight를 바탕으로 현재 weight를 업데이트 한다고 보면 된다. 하지만 우리의 0.4 alpha는 과거보다는 현재의 weight를 바탕으로 그 다음 weight를 산출하는데 의미를 둔다고 보면 될거같다.
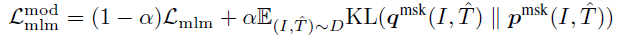
Does ALBEF loss function and increase the upper bound??
ITC loss function
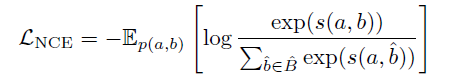

- 우선 다음과 같이 InfoNCE loss function을 적을 수 있다. a,b는 two random variable이고, s(a,b)는 scoring function이다. B_hat은 positive sample b를 포함하고 있는 집합이고, 1개의 positive sample(b) N-1개의 negative sample을 가지고 있다.
- 그리고 위에서 보이는 것 처럼 우리는 InfoNCE loss를 위와 같이 ITC loss로 재정의할 수 있고, 이 ITC loss를 최소화 하는 것은 InfoNCE를 최소화 하는 것과 같다 (수식이 같으므로). s(I,T)인 positive pair의 scoring이 가장 높고, negative pair의 scoring가 가장 낮을 때, 분수의 값은 최대화가 되기에, 위의 수식은 Mutual information uppder bound를 올릴 수 있다.
MLM loss function
ψ는 lookup function이고, 모델 f의 입력으로 들어간 I = Image, T_hat = corrupted token T의 출력은 corrupted token의 output 값이다. 이 둘의 내적이 최대화를 통해 무작위 masked token 복구, masked token과 관련이 있는 image 학습 가능.
기존 MLM은 단어 예측을 하기에 Cross Entropy를 사용하는데, 이 내적을 구하는 과정은 ψ를 통한 index가 어떤 단어인지 확인 x 모델의 output을 바탕으로 Softmax function인 logit을 구하는 것과 같다고 생각하면 될 거 같다.

Momentum ITC
이 수식에서 KL divergence는 KL(q, p) = q(x) log(q(x) / p(x)) 인데 수식 11은 cross entropy와 똑같은 모습을 보여주고 있다. q는 momentum model, p는 student model이다. KL(q, p) = q(x) log(q(x) / p(x)) = q(x) log (q(x)) - q(x) log(p(x))에서 momentum model의 파라미터는 이론적으로 변하지 않으니까? (보통 momentum을 사용하면 0.9라서 생략하면 이해하는데.. 0.4라서 생략 되는진 모르겠지만) 여기서 entropy는 생략하므로, 아래와 같은 수식만 남게되어 위와 같은 논리로 upper bound 상승이다.

Experiment results

- VQA와 NLVR을 수행할 때의 ALBEF의 모델 구조는 다음과 같다.





