Title: Will we run out of data An analysis of the limits of scaling datasets in Machine Learning
Published: ArXiV 2022
Citation number: 75 (2024.03.11 기준)
Author info: Company Epoch, University of Aberdeen, MIT Computer Science et al. 인데 Epoch이라는 예측 전문 회사에서 이 논문을 출판했다고 보면 될 것 같다.
오타와 대학과의 공동 저널클럽에서 발표한 논문이며, 재미있어보이는 논문이 뭐가있을까 하다가 뉴스에서 학습 데이터가 고갈된다는 그런 내용을 봤고, 관련 내용을 찾아보다가 Google Deepmind의 친칠라 데이터 스케일링 법칙을 살펴보다가 이 논문까지 넘어오게 되었다.
유튜브에서 아주 좋은 발표 영상을 보게 되었는데, 이 블로그 포스팅보다, 아래의 영상을 보는걸 더 추천한다.
https://www.youtube.com/watch?v=STmnqgF66ck&t=126s
우선 결론부터 이야기 하자면, 학습데이터는 고갈이 될 것이라 말한다. Vision이든, NLP든, 필자는 학부생을 벗어난지 얼마 안됐고 Vision이 더 익숙하지만, 이 저자들은 NLP 전문가들이고 Vision은 잘 모르기에 이 논문에서 Vision은 대략적으로 예측했다.
Chinchilla data scalling 법칙과, 자기들만의 예측모델을 바탕으로 한 것이지만, 그래도 틀린 말은 아닌 것 같아서 주의깊게 볼만 했던 논문이라 생각한다. 아 그리고 여기서는 GAN과 같은 syntatic data를 포함하지 않았는데, 2023-2024 AI시장에서 현재 가장 hot한 분야가 이런 생성형 데이터 분야이다보니, 이를 고려했다면 어쩌면 논문의 아래 Figure에서 말하는 2026년보다는 훨씬 더 지연되는 그런 현상이 일어날 것이라 생각한다. 그리고 OpenAI, Google과 같은 기업이 데이터를 다 써서 (더 쓸 데이터가 없어서) GPU를 더 쓸 수 있는데도 못쓴다면, 아마 Syntatic data까지 고려하지 않을까 싶다.
정보 요약
- Low quality NLP data: 주로 인터넷 사용자가 생성한 내용에서 비롯됩니다. 여기에는 소셜 미디어 플랫폼, 블로그, 포럼 등에서 사용자가 생성한 텍스트 데이터가 포함됩니다. 이러한 데이터는 대량으로 존재하며, 다양성과 넓은 범위를 제공하지만, 오류가 많거나 주제에 따른 일관성이 부족할 수 있음.
- High quality NLP data: 전문적으로 생성되거나 검증된 내용을 포함. 이에는 과학 논문, 전문적으로 작성된 뉴스 기사, 공식 문서, 책 등이 포함. 또한, Wikipedia와 같은 고도로 관리되는 온라인 지식 베이스나 Peer (동료) 리뷰를 거친 학술적 내용도 포함. 이러한 데이터는 일반적으로 높은 정확성과 신뢰도 + 이 논문에서는 평가를 한번 데이터를 의미하며, 모델 학습에 있어서 우수한 품질의 결과를 도출하는 데 기여할 것이라 예측되는 데이터
- Computer vision data: 주로 이미지와 비디오로 구성되며, 다양한 소스에서 수집 (근데 저자의 전문지식 부족도 고려). SNS에 업로드된 사진과 비디오, 공개적으로 사용 가능한 이미지 데이터베이스, 위성 이미지, 의료 이미지 등이 포함. 컴퓨터 비전 모델의 학습 및 개선을 위해 사용되며, 객체 인식, 이미지 분류, 시각적 내용 이해 등 다양한 응용 분야에 기여.
- 파란색 선: 현재의 스케일링 법칙과 기존의 컴퓨팅 가용성 추정치를 고려하여 최적의 데이터셋 크기를 계산한 결과
- 빨간색 선: 과거의 트렌드를 바탕으로 한 예측 결과입니다. 이는 매년 약 50%의 성장률을 기반으로 한 것으로, 데이터셋의 사용량이 늘어나고 있음을 보여준다.
- 검정색 선: 이는 사용 가능한 데이터의 총량을 나타낸다. 현재 데이터셋의 크기는 사용 가능한 데이터의 총량에 비해 매우 작으며, 이는 시간이 지남에 따라 데이터의 사용 가능한 양이 줄어들 것임을 시사.
결론 그리고 한계:
1. 데이터셋 크기의 지속적인 증가와 데이터의 사용 가능한 총량 간의 괴리는 결국 데이터 고갈로 이어질 것. 특히 고품질 언어 데이터의 경우, 이러한 고갈은 더 빠르게 발생할 것으로 예상 (2026)
2. 하지만, 알고리즘의 효율성 증가나 새로운 데이터 소스의 발견과 같은 변수들에 대한 우리의 이해가 부족하여 미래의 데이터 요구를 정확히 예측하기는 어려움
3. 결론적으로, 현재 추세가 계속된다면 데이터는 궁극적으로 기계 학습 모델의 규모 확장에 있어 주요 병목 지점이 될 것
4. Backbone 네트워크의 성능은 이제 어느정도 비슷해질 것, 학습 방법론이 추후엔 주목을 받지 않을까 생각한다.
그리고 2024
1. 하드웨어의 발전이 생각보다 느리다고 했는데, 요즘 NVIDIA의 주가가 심상치가 않다. 진짜 미친듯이 오른다. 하드웨어의 발전이 2022년의 예상보다 빠르다가 핵심이다.
2. 생성형 AI의 발전으로 데이터의 생성량이 생각보다 더 늘어날듯..?
3. 아 또 있었는데 까먹었다,,,

위의 Main figure에 대해 설명하자면, 다음과 같다.
1. 각각의 다른 두 종류의 예측 모델을 만든다. (빨강 + 파랑)
- 첫 번째 모델은 이전 논문들의 데이터 사용량 추세에 기반한 것이고,
- 다른 하나는 그들의 평가 지표를 바탕으로한 예측 모델이다. (파란색) 이 파란색은 외삽법이라는 Extrapolation 이라는 방법론을 바탕으로 했다. 여기서 이 Extrapolation은 Interpolation 보간의 반대방법이라 보면 된다. 바깥을 예측하는거다.
2. 그리고 각각의 두 모델은 모두 그들의 예측 모델을 나타내는 검은색 점선과 비교된다.
- 여기서 검은색은 데이터가 쌓이는 속도의 추세이다.
3. 그래프 해석.
Low quality NLP data: 2030년에서 2050년 사이에 Data shortage가 발생할 것으로 예상된다.
High quality NLP data: 2026년까지 소진될 것으로 예상된다.
Computer Vision data: 2030년에서 2060년 사이에 소진될 것으로 예측된다.
앞서 말한 것처럼. 저자는 비전 데이터에 대한 영역 지식이 조금 있어서 소진 연도의 범위가 너무 넓다. 하지만 우리가 2024년에 살고 있음에도 불구하고 언어 데이터의 높은 품질은 2026년에 꽤 가깝다.
이 논문에서는 이러한 그래프들이 왜 이렇게 되고, 고품질, 저품질 데이터를 구성하는 것이 무엇인지에 대해 알아볼 것이다
잘 보일지 모르겠지만, 우측은 데이터의 사용량 그리고 품질에 따른 모델의 성능을 앤드류 응 선생님께서 직접 강의하시는 모습이다. 이 내용은 DeepLearning / Machine Leanring을 시작하는 사람이라면, 한번쯤은 봤을 법한 DeepLearning-Specialization 에서 설명하신 내용이다.
데이터 품질은 좋을 수록 좋고, 양도 많을 수록 성능을 올리기가 효과적이다. 그리고 왼쪽에서 우측의 그림은, 시간이 지남에 따라 얼마나 데이터가 쌓이는지에 대한 그래프이다. 약간 추상적으로 대략적인 GB, TB등의 용량 정보만 표기했지 어떤 데이터가 얼마나 어떻게 쌓일지 예측하진 않았다. 하지만 확실한건, 데이터가 쌓이는 속도가 매우 빠르며 정보화시대에서 매우 많은 양의 데이터가 쌓이고 있다는 것이다.
그래서 왜 우리가 Data shortage를 왜 걱정해야하냐? 라는 질문엔 Chinchilla의 data scalling 법칙을 보여주고 싶다.
Chinchilla의 data scalling 법칙
- 우측 왼쪽 그림을 보면, 파란색 점은 Google 사람들의 실험 결과고, Chinchilla는 그것에 따라 scaling을 통해 학습 데이터의 양만 늘려서 더 작은 모델로 더 좋은 성능을 냈다. Google DeepMind에서 발표한 Chinchilla의 결론 중 하나는, 기존 GPT와 같은 모델들은 Over-parameterized됐다는 것이다.
- 물론 추후에 나온 PaLM과의 성능을 비교한 우측의 우측 그림을 봤을 때, PaLM은 2배 적은 데이터로 더 좋은 성능을 냈으며, 모델이 훨씬더 무겁긴 하나, GPT와 같은 이전논문들과 Chinchilla의 학습 데이터 양 차이를 고려했을 때, 최소 3배 그 이상의 차이를 보일만큼 많은 데이터를 사용했다는 것이 오늘 설명할 논문에서의 또하나 중요한 점이다.

그래서 이 논문이 어떻게 예측을 했냐 라고 하면 위의 슬라이드를 참조하면 된다.
제일 앞단에서 설명한 내용 그대로이며, 추가적인 내용은 Measurement Unit, 즉 측정 단위를 이전 Related work problems에서 다뤘던 대략적인 용량이 아닌, 하나의 단어, 하나의 이미지로 계산해서 더 정확하게 맞추려는 시도를 했다는 것이다.

그래서 앞서서 말한 이전 논문의 트렌드를 기반으로 하면, 그냥 뭐 통계치 쌓아서 예측하면 되니까 별다르게 설명할 필요가 없고, 자기들이 주장하는 모델이 어떤 내용을 기반으로 하는지, 데이터가 얼마나 쌓이는 지에 예측을 했는지에 대한 내용을 지금부터 설명할 예정이다.
우선 왼쪽 슬라이드는 데이터 사용량을 어떻게 예측했는지 이다.
주된 요소로 "Computing budget"과 "데이터 세트 크기 사이의 관계"가 매우 관련이 높다는 것을 활용했다.
당연하게, GPU가 많으면 배치 크기를 늘리고 더 많은 GPU 메모리를 사용할 수 있어 도움이 되고 더 많은 데이터 세트를 쌓을 수 있다. 따라서 데이터 집합의 크기(D)가 계산 예산(C)의 제곱근에 비례한다고 가정하는 원리를 채택했다.
수학적으로 이 관계식은 위에서 보이는 D∝√C 이며, 저자는 하드웨어 예산(D)을 예측한 다음 이 계수를 스케일링하여 C를 예측하고, 이게 저자들의 예측 방식인 파란색 선이다. (지금 다시보면 엄청 성의없게 예측한 것 같다.)
그래도 완전 근거가 없는 건 아닌게, 위에서 나온 가정이 Cinchilla 논문에서 나온 아이디어를 근거로 하기 때문이다.
물론 우리는 계산 자원이 증가하면 더 큰 데이터 세트를 처리하고 활용할 수 있는 능력도 증가하지만, 선형적으로 정확히 일치하지는 않는다는 것도 알고, 하드웨어 자원이 계산 예산에서 가장 중요한 요소라는 것을 알고 있기 때문에, 대신 계산 예산의 제곱근에 비례하여 증가한다라고 이야기 한다. 따라서 이 파란색 선은 하드웨어적인 요소를 기반으로 외삽법을 통해서 예측한다고 보면 될 것 같다.
반면 우리가 추세에 기반한 외삽법을 고려할 때, 이 방법은 순진하게도 데이터 축적의 과거 추세를 가정한다. 그래서 우리는 과거의 연구를 기반으로 단순하게 빨간색 예측 그래프를 얻는다.
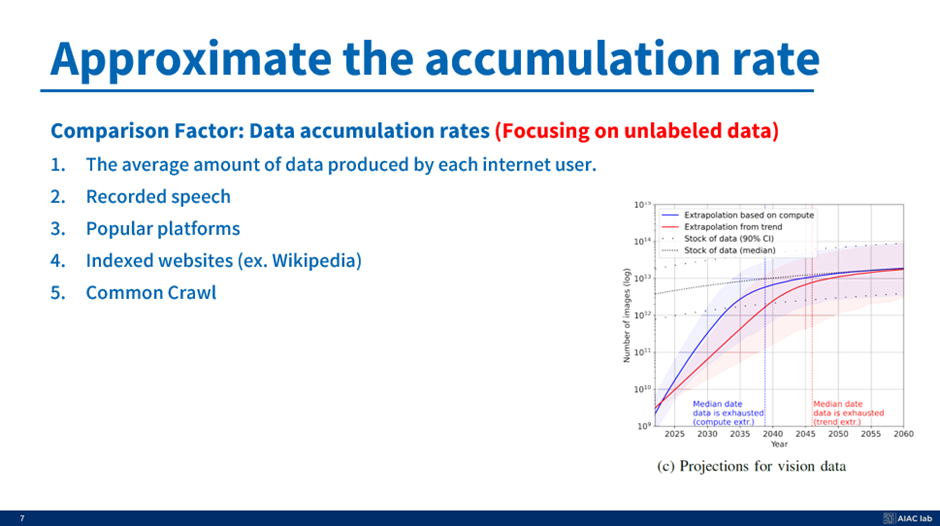
그리고 이번엔 검은색 선을 어떻게 예측했는지 이다. 주로 이 5개를 중점으로 봤다고 한다.
이 검은 점선은 label이 존재하는 데이터를 얻기가 정말 어렵기 때문에 unlabeld 데이터에 초점을 맞춘다. label 데이터는 매우 노동집약적인 과정을 필요로 하며, 오늘날까지도 Un/Self-Supervised Learning의 중요성을 강조하는 논문들이 많고, 특히 필자가 관심이 있게 연구했던 분야였기에 관심이 있다면 다른 섹션을 뒤져보는거도 추천한다.
그래서 레이블이 지정되지 않은 데이터만 고려한 다음 고품질 데이터와 저품질 데이터를 나누었다. 사실 고품질/저품질을 나누는 기준을 뒤에서 명확하게 설명해서 그냥 이러한 요소를 바탕으로 데이터 수치를 예측했다고 보면 될거같다.
저자는 이 다섯 가지 요인이 Accumulation Rate와 관련성이 높다고 가정한다.
- The average amount of data produced by each internet user. In this case, we assume each internet user makes data regularly.
- Recorded speech
- Popular platforms (ex. YouTube, Twitter)
- Indexed websites (ex. Wikipedia)
- Common Crawl
이 논문에서의 추정 방법은 알아보자. 앞서 말한 것 처럼 언어 데이터 세트에 한 단어, 비전 데이터 세트에 한 이미지를 사용하여 저자가 총 데이터 양을 계산하는 것을 기억하자.
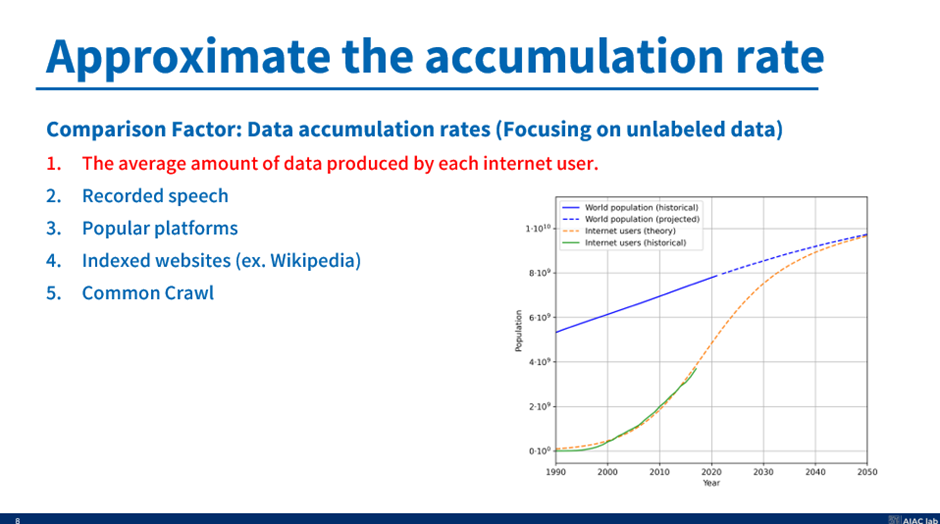

1. 먼저 인터넷 사용자별 평균 데이터 생산량.
요즘은 SNS나 인터넷 웹사이트에 글을 적는 것이 정말 쉽기에, UN의 인구 보고서에서 미래 인구를 예측하는 것을 사용하고, 이 미래 인구를 기반으로 이 사용자들이 정기적으로 대본을 만들거나 무언가를 쓰고 있다고 가정한다.
++ 그리고 이 인터넷 사용자 그래프를 얻기 위해 우리는 모든 사람들이 결국에는 2080년 정도 되면 인터넷을 사용할 수 있다고 가정한다. 그래서 우리의 선 모양은 Sigmoid 함수와 같게 설정한다.
1990년대 부터 예측하기 시작하여 이 인터넷 사용자 그래프를 검증할 때, 생각보다 나름 정확하다. 심지어 1990년대 부터 정확하게 예측하기도 한다. 그래서 이 인터넷 사용자 수를 바탕으로 기존에 봤던 모델 검정색 선에 영향을 끼치는 Feature를 만들 수 있다.
2. 두번째는 Recorded speech이다
세계 인구 전망 2022년 보고서를 기준으로 한 사람당 하루에 5k에서 20k 사이의 단어를 발음하거나 쓴다. 그리고 적어도 0.5%에서 50%는 디지털 방식으로 기록되기에 1인당 연간 단어의 양은 16만개에서 260만개 사이


3. 저자는 데이터 소스를 얻기 위해 인기 플랫폼에 대해 언급
- 유튜브를 시작으로 매분 500시간 분량의 동영상이 업로드되고, 이 중 5~50% 정도가 음성을 담고 있다. 우리가 번역하면 시간당 약 9,000개의 단어가 나온다. 이는 매년 130~1조 3,000억 단어에 달해 언어 모델 훈련에 필요한 데이터에 크게 기여한다.
- X라는 트위터로 넘어가면 플랫폼은 매일 5억 개의 트윗을 본다. 각각의 트윗에 10~50개의 단어가 포함되어 있기 때문에 우리는 연간 2조~20조 개의 단어를 보고 있다. 그리고 트위터에서 스크립트나 문장을 작성할 때 우리는 스크립트를 요약하고 강력한 의견을 전달한다. 그래서 우리는 좋은 텍스트 데이터 세트를 얻는 것을 가정한다.
- 블로그도 그 조합을 더해서 매일 750만 개의 게시물이 게시된다. 각 게시물에 약 100~1,000개의 단어가 있다는 것을 감안하면, 우리는 매년 0.2~2조 개의 단어를 추가로 축적한다.
- 이제 이러한 수치를 가지고 이 콘텐츠의 5~40%만이 언어 모델링 목적에 적합하다고 가정하면, 이러한 인기 플랫폼에서 매년 8.9~110조 개의 단어가 만들어진다.
4. 데이터 축적 속도를 더 근사화하면서 웹사이트를 더 넓은 인터넷으로 확장하는 것도 고려 가능.
- 이를 통해 우리는 텍스트 데이터의 보고인 Common crawl website 같은 저장소를 포함한 색인 웹사이트도 고려 가능하다
- 웹 크롤링 데이터의 개방형 저장소인 Common Krolling을 시작으로 매달 약 5~10TB의 압축된 평문 데이터를 볼 수 있다. 이 콘텐츠의 절반이 새 콘텐츠이고, 영어 텍스트의 압축률이 30%에서 85% 사이인 점을 고려하면 연간 약 160TB의 텍스트 데이터가 압축되지 않은 수치로 남게 된다.
- 결론: 우리는 매년 8.3조에서 44조의 단어를 얻습니다,
5. 색인화된 웹사이트의 측면은 우리는 100억 개에서 1,000억 개에 이르는 웹사이트에 끊임없이 단어가 유입중.
- 이 사이트들은 각각 위키백과의 각 문서처럼 약 500~5만 개의 단어를 제공하며, 이는 전체 웹사이트에서 10~100조 개의 단어에 달한다.

일반적인 데이터 축적률에 대한 우리의 이해와 더불어 고품질 데이터의 출처와 축적률을 구별하는 것이 중요하다. 이 논문의 저자가 주장하는 고품질 데이터는 유용성이나 품질 필터를 고수하는 것이 특징이다.
ex) News, 과학 출판물, github 등은 신뢰성과 관련성 수준을 보장하는 전문적인 기준을 적용받는 것이 일반적이다. 이들은 품질 관리 조치로 작용하는 동료 검토 또는 편집 프로세스를 통해 필터링될 수 있다.
+ 게다가 위키피디아와 같은 자료에는 자체 필터가 있고, 편집자가 콘텐츠를 큐레이션하고 검증한다.
++그리고 재미있는 점은, 한 국가가 연구 개발에 투자하는 GDP의 비율과 같은 경제적 요인을 고려하며, 이는 곧 생산되는 데이터의 질과 양에 영향을 미칠 수 있다고 주장하며, 우리는 전 세계 GDP 예산에서 R&D 예산을 2%에서 4%로 늘어난다고 설정한 다음 단어 양을 계산하여 새로운 기사나 과학 기사를 포함한다.
이러한 차별화 요소들을 검토함으로써, 저자는 다양한 인터넷 사용자들의 기여와 정보의 질을 높이는 필터링 메커니즘 덕분에 가치 있는 고품질 데이터가 축적되는 속도를 추정할 수 있다고 주장한다.
결론 해석에 들어가기 전, 이 논문의 한계를 먼저 말하면 다음과 같다. 또한 2년이 지났기에 과연 왜?? 그렇게 예측했는지, 그리고 맞았는지 틀렸는지도 알 수 있다.
사실 결과를 보기 앞서서 분석을 시작하기 전에 저자가 먼저 한계를 밝힌다. 따라서 이러한 단점을 고려하고 결과 해석을 하기를 저자는 바란다. 저자의 보고서에는 크게 두 가지 단점이 있다
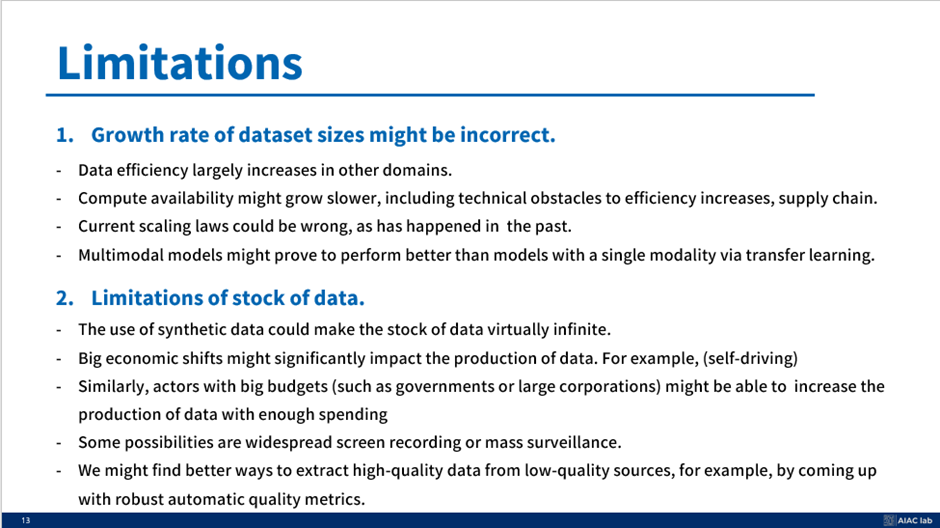
1. 데이터 세트 크기의 증가율이 올바르지 않을 수 있다.
1. 데이터셋 크기 증가율 부분에서 저자는 컴퓨팅 예산만을 고려했다. 따라서 너무 구식이기 때문에 잘못된 것일 수 있다.
2. 또한 멀티 모달 기능을 강화하면 컴퓨팅 예산을 효율적으로 사용하거나 다양한 모달리티를 사용하여 유용한 정보를 추출할 수 있다. (Multi modality 분야의 발전을 시사)
(필자도 Multi modality로 SOTA를 하나 찍었는데 Multi modality는 진짜 알면 알수록 대단한 친구인거같다.)
2. 데이터 재고의 한계.
- 녹음된 스피치 등을 전제로 하는데 zoom과 같은건 유출이 안되고, 사람들이 생각보다 녹음데이터를 안쓴다는 것.
- 그리고 우리는 2024년에 살고 있고, 그래서 우리는 호황을 누리고 있는 상황 때문에 과거보다 더 쉽게 돈을 벌 수 있다. 이는 정부가 R&D 예산을 4% 보다 더 높은 폭으로 늘릴 수 있음을 의미한다. 물론 최근에 한국이 R&B 예산을 줄였기 때문에 이런 특별한 이벤트가 발생할 수도 있으며 일관성 없는 주장으로 들리지만 어쨌든 그것은 특별한 경우이고. 저자는 R&D 예산이 세계 GDP의 4%라고 가정하고 모델을 만들었다고 한다.
결론 분석 (Low quality)
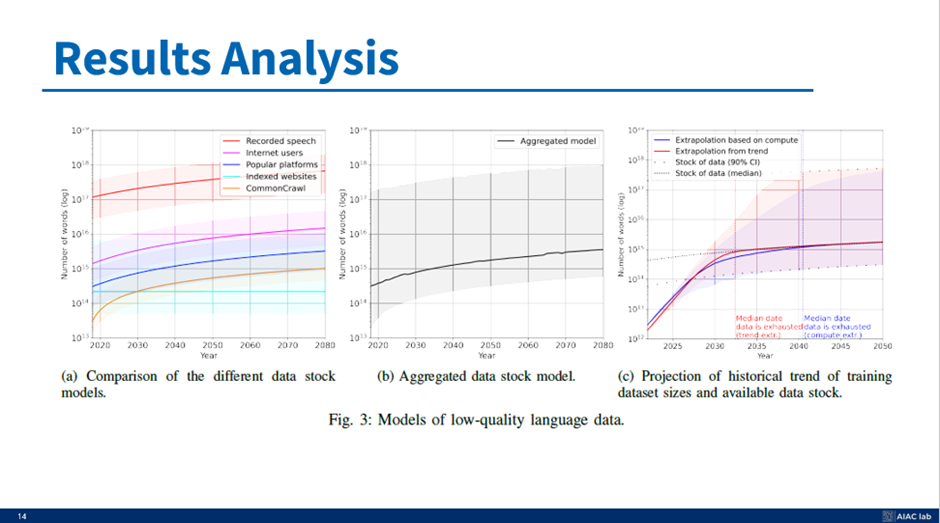
앞서 주요 그래프인 그림 3©를 설명하면서 먼저 검은 선을 얻는 방법을 좀 더 구체적으로 제시하고자 한다.
먼저 그림 3a에서는 앞의 슬라이드에서 살펴본 여러 data stock 모델을 비교한다. 이 모델들은 녹음된 음성, 인터넷 user의 기여, 인기 플랫폼의 콘텐츠, indexed website, Common crwal dataset를 나타내며, 2080년까지의 데이터를 보여준다.
다음으로 그림 3b에 집계된 data stock 모델을 보여준다. 이 그래프는 개별 데이터 소스 예측을 하나의 곡선으로 매끄럽게 통합한 것이다. 그러나 그들은 이 개별 정보를 어떻게 요약하는지에 대해서는 언급하지 않았다.
필자의 개인적인 의견으로는 이 녹음된 연설이 높은 가치를 제공할 수 있다는 것을 알지만, 필자가 진행한 세미나가 유출되지 않는 것처럼 쉽지 않다. 또한 인터넷 사용자들은 정기적으로 자신의 이야기를 기록하지 않는다. 아마도 이러한 요소들이 인기 플랫폼에 포함되어 있을 것이다.
우리가 스탠포드의 CS229와 같은 유튜브에서 수업 비디오를 쉽게 얻을 수 있다고 해도, 일반 인터넷 서비스가 아닌 트위터로 우리의 이야기를 기록한다고 해도 일부 수업만 공개가 된 것이며, 다양한 시나리오를 고려해서 검은 그림 3B 선이 우리의 예상보다 낮지 않을까 라고 생각한다.
마지막으로, 그림 3c는 특히 저품질 언어 데이터에 초점을 맞춘 훈련 데이터 세트 크기 및 사용 가능한 data stock model의 역사적 추세에 대한 예측을 제공한다. 우리는 두 가지 외삽법을 관찰할 수 있다: 하나는 (FLOP에 의해 정의된) 사용 가능한 계산 용량을 기반으로 하는 것이고 다른 하나는 역사적 추세를 기반으로 하는 것이다
따라서 Low Quality dataset은 2030 부터 2060 사이에 고갈된다고 예측을 하였다.
결론 분석 (high quality)
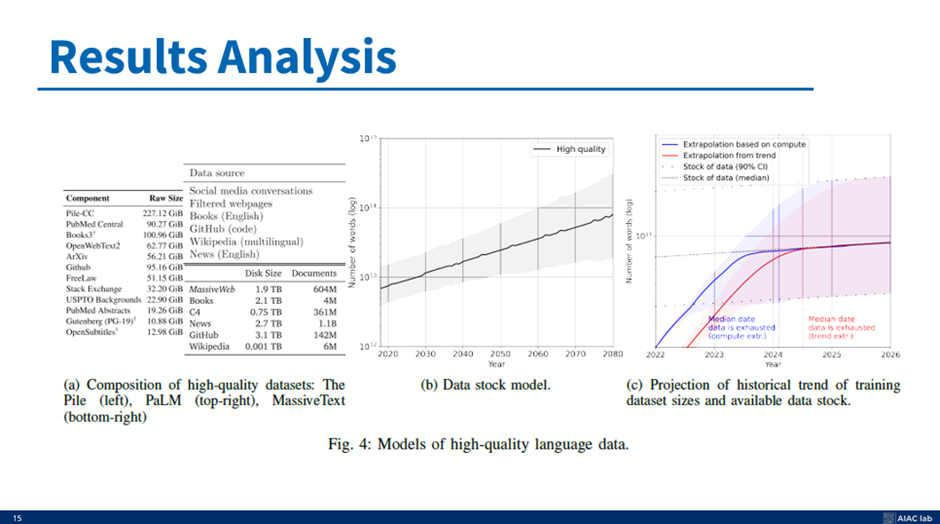
고품질 언어 데이터의 모델을 나타낸 그림 4의 다른 결과 분석으로 넘어가면 다음과 같다. 이 고품질 데이터는 정확하고 신뢰할 수 있는 언어 모델을 훈련하는 데 중요하다,
그림 4a는 고품질 데이터 세트의 구성을 보여준다. "The Pile"과 "PaLM training Language 데이터 세트", "Massive Text" 데이터 세트가 포함되어 있다. 이 중에서 앞의 슬라이드에서 본 것처럼 GitHub 저장소와 과학 논문의 양을 추정하고, 앞의 슬라이드에서 설명한 다양한 특징을 기반으로 디지털화된 도서를 스케일링 팩터로 사용하여 고품질 데이터 세트의 수를 계산한다. 그림 4b는 그림 4와 같다.
마지막으로 4c는 이전의 저품질 그래프와 유사한 훈련 데이터셋 크기 및 가용 데이터 스톡의 역사적 추세 예측을 보여준다. 그리고 고품질 데이터에서 그들의 결론은 2026년에 모두 소진된다.
결론 분석 (Computer vision)
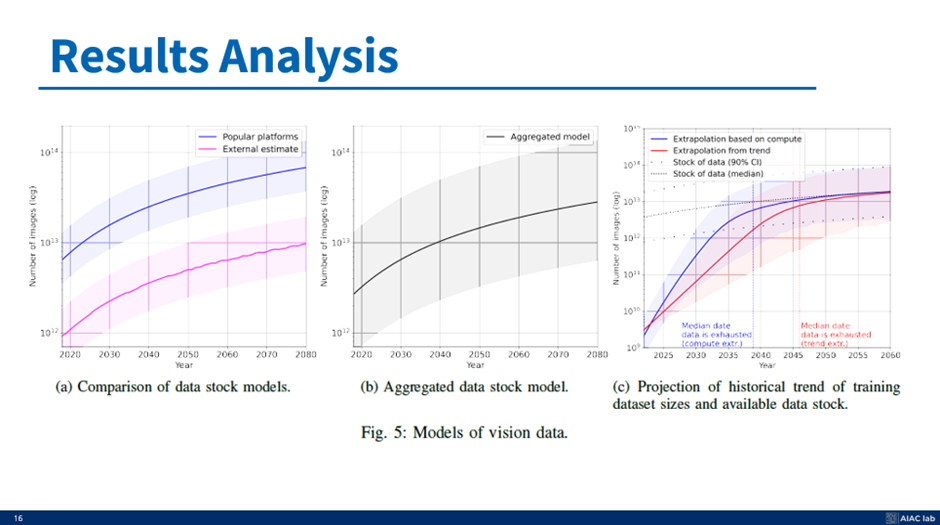
같은 방식으로 인기 플랫폼과 외부 추정치를 추정한 다음 결합하여 추정할 수 있다
'Machine Learning > Statistics' 카테고리의 다른 글
| Self-Attention과 Bilinear function (2) | 2023.10.02 |
|---|---|
| Variational Bayes Tutorial (0) | 2023.06.08 |
| 피어슨 상관계수(Pearson Correlation Coefficient) 알아보기 및 직접 HeatMap과 분포도 시각화해보기. (0) | 2023.05.21 |
| Sigmoid 미분하기 (0) | 2022.09.20 |


