제목: Densely Connected Convolutional Networks
저자: Gao Huang et al.
소속: Cornell, Tsinghua University, Facebook AI
학회: CVPR2017 (Best Paper Award*)
인용: 38142 (2023.09.10 기준)
링크 : https://arxiv.org/pdf/1608.06993.pdf
영상 : https://www.youtube.com/watch?v=-W6y8xnd--U
오늘은 대학원 수업에서 DenseNet paper를 발표하게 되었다. 첫 발표는 2015-2018 사이의 큼직한 논문들이 있었는데 ResNet, LeNet, Efficientnet 등 다른 논문은 읽어본 적이 있는데, DenseNet은 잘 몰라서 빠르게 선정했다.
CVPR2017 best paper award를 수상한 DenseNet paper를 알아보자.
- 한장으로 요약하면 아래와 같다. 목표는 더 정확하고 더 효율적인 모델을 만드는 것이다.
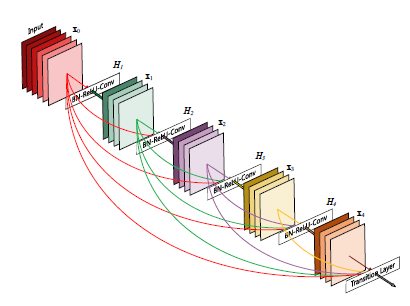
- Contribution은 SOTA를 달성할 때, 더 적은 파라미터 수로 달성했다는 것이다. 이에 대한 방법론은 아래의 2개의 그림으로 나타낼 수 있는데, 먼저 아래와 같이 Block 단위로 모델을 구성하고, Block은 왼쪽과 같이 Densely Connected 하게 구성이 되어있다.
- 이 논문의 문제점은 이따 뒤에서 설명하겠지만, Densely Connected 하기에, 이를 Concatenate하는 과정에서 속도가 느리며, Densely Connected 하기에 모델이 깊어질수록 더 이상 layer 혹은 block을 쌓기가 어렵다.


0. Abstract.
- 최근 Model Architecture를 바꾸려는 시도가 많은데, DenseNet또한 그중 하나이다. 그 중에서도 DenseNet이 목표로 하는 것은 더 정확하고, 깊고, 효율적으로 학습이 가능한 모델을 만드는 것이다.
- 위에서 정의하는 효율적인 모델이란, 입력과 출력 사이에 짧은 연결을 통해(Skip-connection) 학습을 더 쉽게 만든다.
++ 앞에서 추출된 정보를 재사용함으로써 특징정보 재사용해서 학습의 효율성 높일 수 있음. 또한 Residual learning을 통한 학습 쉬워짐.
- 기존의 Network들은 L개의 Layer가 있다면 L개의 연결을 사용했다. 하지만 DenseNet은 L x (L-1) / 2 개의 연결을 가진다.
- DenseNet이 가지는 장점
1. alleviate the vanishing-gradient problem.
2. strengthen feature propagation
3. Encourage feature reuse.
4. Substantially reduce the number of parameters and get a better result (SOTA)
1. Introduction.
- LeNet, VGG19, Highway Net, ResNet 등 다양한 모델 구조의 등장 및 100 층이 넘는 더 깊은 layer를 쌓을 수 있게 됨.
- 하지만 이런 과정에서 vanishing-gradient 문제를 야기시켰고, 이를 해결하기 위해 ResNet에서는 identity connection 사용
- DenseNet은 이런 문제를 해결하기 위해 모든 layer를 연결 시킨 후, layer들끼리의 maximum information flow를 보장하는 네트워크를 만듬.
- Figure 1을 보면 이전 layer에 대한 정보를 바탕으로, 다음에 있는 모든 layer에 정보를 넘겨준다. 따라서 둘 사이의 L x (L-1) / 2 라는 연결 수식이 나옴. (Figure 1 참조)
- 이러한 연결을 바탕으로 기존의 전통적인 CNN과 비교했을 때, 더 적은 parameter 수의 Network 구성이 가능하다는 것인데, 저자는 불필요한 feature-map을 제거했기 때문이라고 한다.
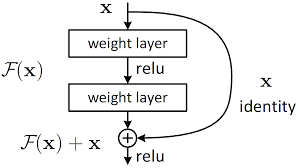
- ResNet은 입력 Feature를 Network를 통해 압축/요약 시킨 후, 다시 더해주는 과정을 거친다면, DenseNet은 들어온 모든 입력 Feature에 대해 Concatenate 작업을 치루게 된다. (아래 그림 비교) 저자는 ResNet의 이 요약 후 합치는 과정이 네트워크에서의 information flow을 방해할 가능성이 있다고 하였다.

2. Related Work

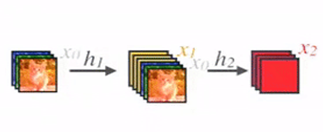
왼쪽: 전통적인 CNN 구조, layer-to-layer 구조로 이루어져 있으며 입력 feature x는 layer를 통과하며 필요한 정보는 보존하고, x의 상태를 바꾸며 다음 layer에 H(x)로 넘겨준다.
중간: x -> F(x)가 아닌 x -> F(x) + x를 만듬으로써, 우리의 layer가 변화가 적을 경우, F(x)는 0에 가깝게 만들면 되기에 F(x)를 만들어 내야하는 전통적인 방식보다 효율적으로 학습할 수 있다.
오른쪽: 우리의 DenseNet은 어떤 정보가 보존되어야 하는지, 더해져야하는지 명확하게 알 수 있다. 우측의 그림과 같이, 들어간 입력에 대해 선택되는 정보는 해당 layer의 출력인 k=12개만큼의 filter일 것이며, 보존해야 하는 정보는 모든 layer의 출력이 될 것이다.
- 각 layer는 loss function에서 얻은 gradient에 대해 직접적으로 접근할 수 있기에 implicit deep supervision을 이끌 수 있다.
implicit deep supervision* : 네트워크의 각 레이어가 독립적으로 학습하고 최적화될 수 있도록 하는 메커니즘. 학습의 안정성, 속도 향상 가능
- 또한 이전에 출시된 GoogLeNet은 Inception 모듈을 사용해, 서로 다른 filter 사이즈를 통해 여러가지 관점의 정보를 봤다면, 여기서는 feature를 reuse하여 더 효율적이고, 간단한 압축된 모델을 만드는 것을 목표로 하였다.
3. DenseNet
- DenseNet을 짤로 요약하면 다음과 같다. Gif 에서 볼 수 있듯이, Conv_layer의 출력 필터 수는 항상 같은데, k=3이다.
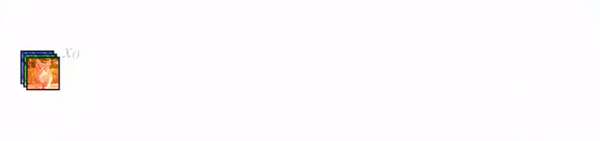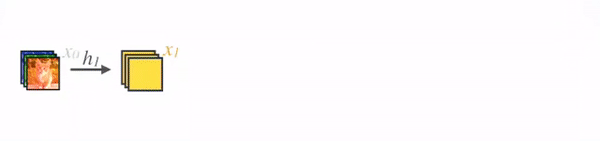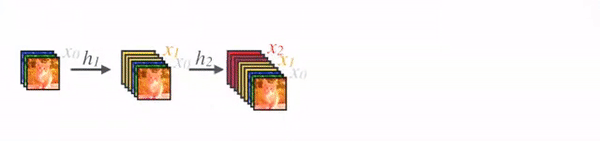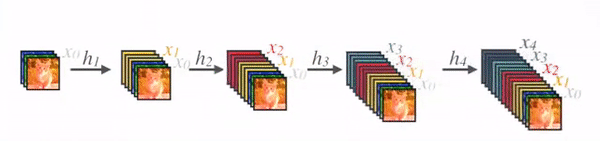

- 입력 이미지가 들어가고, Conv layer를 통해 k의 수를 조절해준다.
- Figure 2의 Conv + Pool layer는 transition layer로 불리는데, [Conv(1x1), MAXPOOL(2x2)] 로 구성이 되어있다. 여기서 1x1 Conv의 역할은, 채널 수를 절반으로 줄여주는 역할을 수행한다.
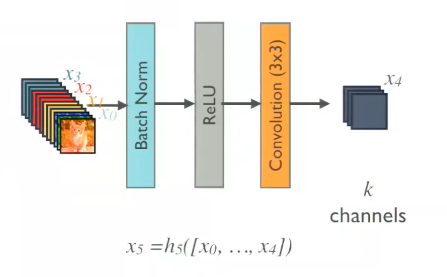
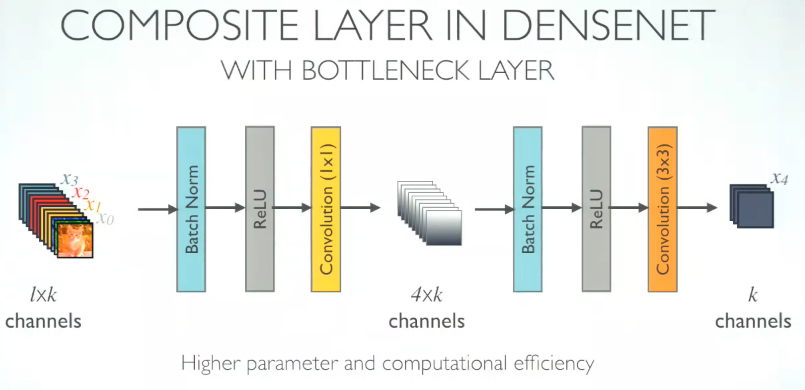

- Figure 1, Forward Propagation에 등장하는 H(⋅)은 [BN, ReLU, Conv(1x1), BN ReLU, Conv(3x3)] 으로 구성되어있다.
- 또한 위의 그림에서 볼 수 있듯이 1x1 Conv의 output은 4k가 되며, 각 H의 출력은 k가 된다.
- 실제 모델을 까보면 빨간 박스가 1x1 Conv의 channel 수 인데, ((Block_num+1) x k, k) 가 되는 것을 볼 수 있다. k = 32

- 위에서 언급한 k는 growth rate라고 불리는데, 각 layer가 k개의 feature-map을 더해줬다는 것이다. 위에서는 12라고 했는데 모델 table 보면 k = 32를 썼다.
4. Experiment
4-1. C10, SVHN Dataset
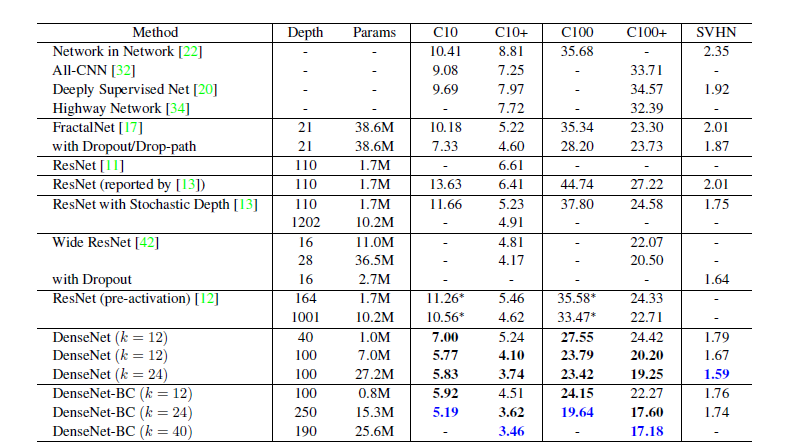
- 위의 그림은 CIFAR10과 SVHN 데이터 셋에 대해 성능을 비교한 표이다. +는 Data augmentation을 적용했다는 것을 의미한다.
- DenseNet-B가 붙은 것은 DenseNet block을 구성할때 [BN, ReLU, Conv(1x1), BN ReLU, Conv(3x3)] 으로 구성한 것, B가 붙지 않은 것은 [BN, ReLU, Conv(3x3)] 이다.
- DenseNet-C는 transition layer에서 압축을 더 진행했다고 보면 될 것 같다.
- 기본 DenseNet은 {L = 40, k = 12}, {L = 100, k = 12}, {L=100, k = 24} 이다. DenseNet-BC는 {L=100, k =12}, {L=250, k=24}, {L=190, k=40} 이다. 그리고 이 Network는 C10, SVHN 전용인것 같다. 우리가 아는 DenseNet169,121은 따로
- hyperparameter:
batch-64(C10, SVHN), 256(IN-1k)
epoch - [300(C10), 40(SVHN), 90(IN-1k)]
optimizer - SGD(momentum=0.9)
lr = 0.1,
weight decay - 10**-4
4-2. IN-1k
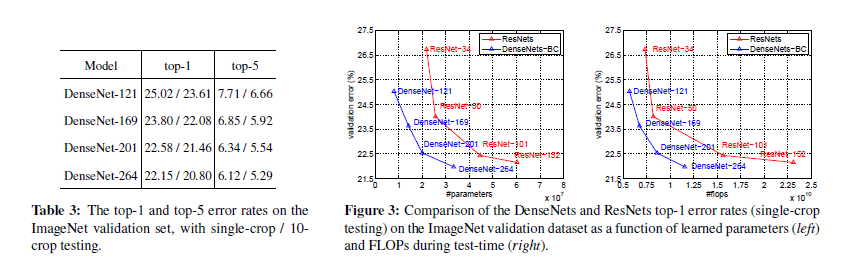
4-3. Feature Reuse
- 이 그림에서 우측과 같은 그림이 있다고 할 때, x1, x0의 concat이 source layer, Target layer가 x2라고 생각하고, 이 중간에 있는 h2의 Weight에 대해서 L1 norm을 적용했다고 보면 된다.
- 따라서 우리의 weight는 (k, k*2, 3,3) 일 것이다. (1x1 Conv 제외하고, 3x3만 있고 Block마다 12개의 layer를 가진 모델)
- 이 weight에서 x1, x0중 쓸만한 feature가 있다면 빨간색으로 높을 것이고, 낮으면 사용하지 않았다는 뜻이 되겠다. 즉 x1,x2에서 x1이 쓸모가 있다면, 이를 반영한 x2가 나오고 이 x1에 대한 weight인 (k, k*2, 3, 3)에서 (k, k, 3, 3) 부분이 빨갛게 변할 것이다.

- 그렇다면, 이 왼쪽 그림이 의미하는 바는 무엇일까? 여러가지가 있는데, 가장 먼저 1번째 block을 보면 빨간색, 주황색, 노란색이 섞여있는 것을 볼 수 있다. 이말은, 앞 부분의 매우 얕은 layer임에도 (receptive field의 크기가 작음)에도 불구하고 이 feature를 사용한다는 것이다. Densely Connected 한 것이 유용하다! 라고 할 수 있다.
- 두 번째로는 Feature map을 Maxpooling으로 줄이기 전 1x1 Conv로 채널수의 절반을 날려버리는데, 이 때, Feature를 잘 요약하는 모습을 Block 1,2에서 볼 수 있다. 즉 1x1 Conv로 채널을 잘 요약해서 사용했다고 볼 수 있다.
4-4. Summary
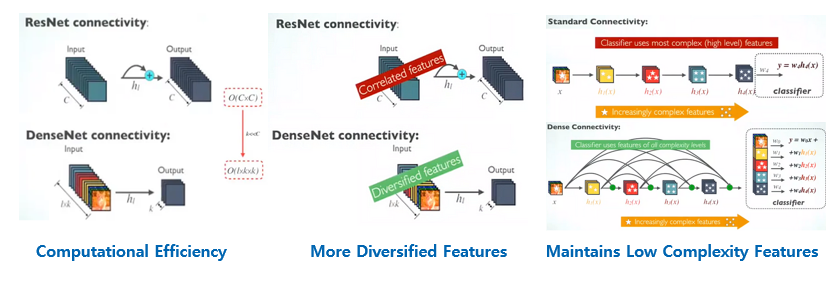
- 마지막으로 ResNet과 비교했을 때 장점은 다음과 같다.
1. 연산의 효율성. ResNet은 같은 Block 내에서 Weight를 element-wise로 더해주기 때문에, Channel 수가 같아야한다. 따라서 이 과정에서 O(CxC)의 비용이 발생한다. 하지만 우리의 DenseNet은 O(lxkxk)이며, 보통 k는 32, l은 1,2,3,4 .. ect로 block의 수 이기 때문에, 매우 작다. 보통 C는 VGG, ResNet에서 exponential하게 증가하니까 DenseNet이 훨씬 효율적!
2. 1과 유사하면서, 동시에 같은 수의 채널은 Correlated Feature를 만들기에 채널 수를 k만 추출하는 DenseNet이 훨신 diversify한 feature를 만들어 낼 수 있다.
3. 뿐만아니라 이 DenseNet은 이러한 Feature를 마음대로 사용할 수 있기 때문에, 기존의 Traditional CNN과 비교했을 때 차별점이 있다. 기존의 CNN, VGG를 예시로 들면 Receptive Field가 앞부분 일수록 작기에, 사람의 몸을 검출한다고 하면 Edge -> 눈,코,입 -> 얼굴, 팔, 다리 -> 몸 전체 이렇게 점점 커진다고 하면, 우리의 DenseNet은 그냥 팔+다리+눈 이런식으로 조합해서 쓸 수 있다는 것이 장점이다.
4-5. 내 생각?
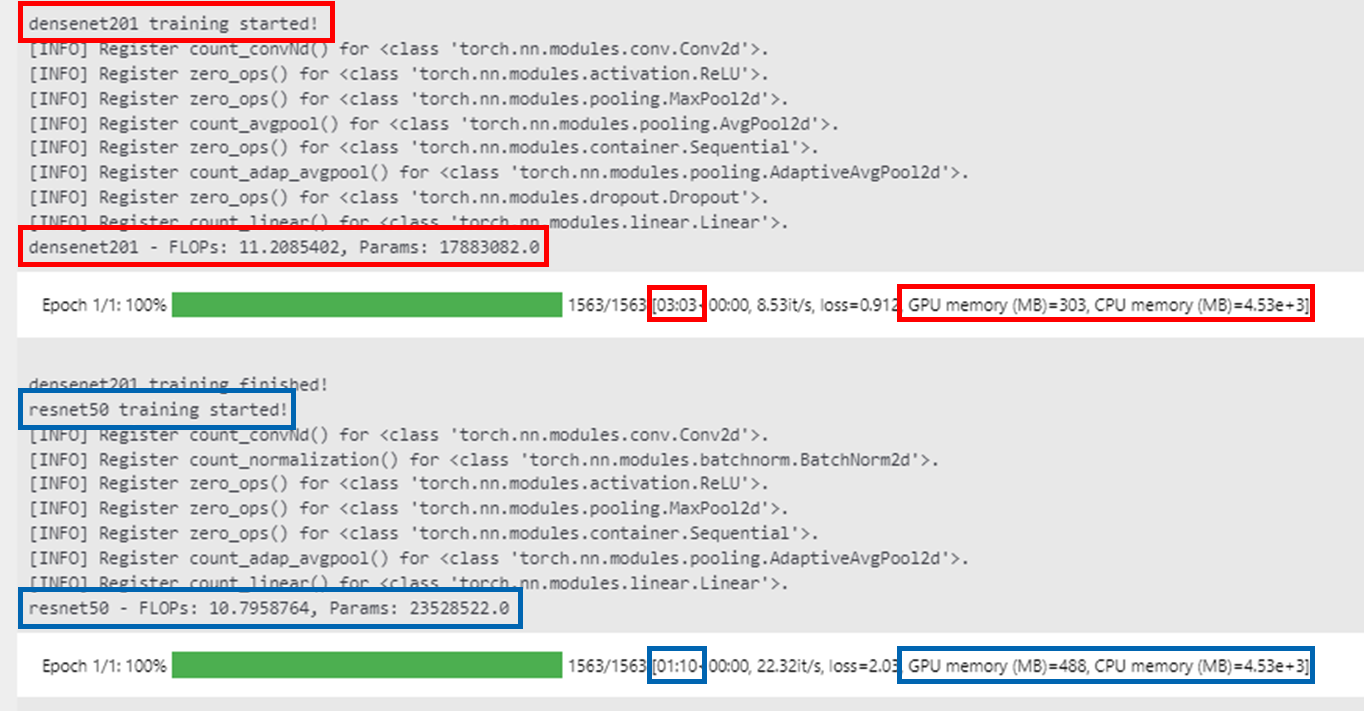
- 내가 ResNet쓸 땐 문제없이 잘 됐고, DenseNet은 서버가 터지는 경우가 종종 있었는데, GPU 사용량이 생각보다 작다. ResNet보다 같은 Flops일 때, 훨씬 더 적으며, layer도 깊고, 성능도 더 좋다! 그래서 결론은 ViT 최고
5. Conclusion.
- DenseNet은 동일한 양의 리소스로 다른 아키텍처보다 더 나은 성능을 달성.
- layer간 direct한 연결은 gradient의 흐름을 개선하며, feature-map의 재사용을 통해 네트워크의 파라미터 효율성을 향상.
- 이러한 densely connection은 더 적은 파라미터로도 높은 성능을 얻을 수 있게 함. (SOTA)
- 우선 같은 파라미터 수 대비 성능이 좋은 것은 맞으나, layer가 깊어질 수록 메모리 사용량이 엄청나게 많다. (개인적인 경험) 그리고 학습 시간이 같은 파라미터 수인 ResNet에 비해 길기에 엄청 효율적인지는 잘 모르겠다.
- 그래서 추가적인 환경으로 실험을 진행했고 결과는 다음과 같다. (GPU: RTX3090x1)
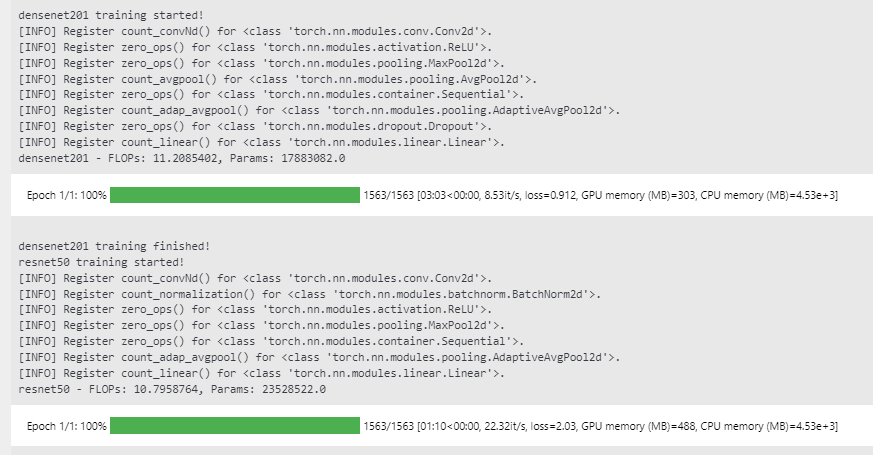
- 비슷한 GFLOPS 대비 파라미터 수가 확실히 적으며, 성능 또한 우수하다. 하지만 학습 시간이 3배 정도 더 오래걸리며, GPU 메모리는 오히려 적게 소요됐다. 신기하네.. 내가 쓸 때는 GPU 터지던데...
- 실험에 돌린 소스코드는 아래와 같다.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import timm
from tqdm.notebook import tqdm
from thop import profile
import psutil
import os
# 데이터셋 다운로드 및 전처리
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32,
shuffle=True, num_workers=9)
# GPU 사용 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 모델, 손실 함수, 최적화 도구 설정
models = {
'densenet201': timm.create_model('densenet201', num_classes=10, pretrained=True).to(device),
'resnet50': timm.create_model('resnet50', num_classes=10, pretrained=True).to(device)
}
criterion = nn.CrossEntropyLoss()
optimizers = {
'densenet201': optim.SGD(models['densenet201'].parameters(), lr=0.001, momentum=0.9),
'resnet50': optim.SGD(models['resnet50'].parameters(), lr=0.001, momentum=0.9)
}
def get_current_memory_usage():
process = psutil.Process(os.getpid())
return process.memory_info().rss / (1024**2) # MB 단위로 반환
# 학습 함수
def train_model(model_name, num_epochs=1):
print(f"{model_name} training started!")
input = torch.randn(128, 3, 32, 32).to(device)
model = models[model_name]
optimizer = optimizers[model_name]
flops, params = profile(model, inputs=(input, ))
print(f"{model_name} - FLOPs: {round(flops/1000000000,7)}, Params: {params}")
for epoch in range(num_epochs):
running_loss = 0.0
progress_bar = tqdm(trainloader, desc=f"Epoch {epoch+1}/{num_epochs}")
for i, data in enumerate(progress_bar, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 현재 GPU 메모리 사용량 확인
current_memory = torch.cuda.memory_allocated() / (1024**2) # MB 단위로 변환
final_memory = get_current_memory_usage()
progress_bar.set_postfix({"loss": running_loss / (i+1), "GPU memory (MB)": current_memory, "CPU memory (MB)":final_memory})
print(f"{model_name} training finished!")
# 모델 학습
train_model('densenet201')
train_model('resnet50')'Deep Learning (Computer Vision)' 카테고리의 다른 글
| Deep Learning & Computer Vision & NLP 용어 정리 (0) | 2023.08.18 |
|---|---|
| Backpropagation 에서 전치의 발생. (0) | 2022.05.02 |
| MLP에서의 Forward pass, Layer shape 맞추기. (0) | 2022.04.28 |

