오늘은 논문을 읽으면서 등장하는 전문적인? 용어들을 내가 기억하기 좋게 정리하기 위해 글을 써보려고 한다. 글로만 명확하게 설명하는 것도 좋지만, 기억에 잘 남는 것은 이미지를 활용하는 것이기에, 이미지와 글을 활용해보려고 한다.
아마 논문을 읽을 때 마다 모르는 용어가 등장하면 업데이트를 할 것 같다.
2023.09.02
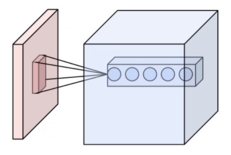
Receptive Field: 우리의 model이, 특히 한 layer 혹은 하나의 뉴런이 보는/담당하는 특정 입력 이미지의 크기이다. 위의 그림을 예시로 들면, 파란색이 우리의 모델, 빨간색이 입력 이미지라고하면, Receptive Field는 중간의 빨간 네모이다. 주로 CNN 모델에서 한 layer의 Receptive Field는 Kernel size와 같다.
Inductive Bias: 학습 알고리즘이 데이터에서 본 적 없는 새로운 상황이나 예제에 어떻게 반응할 것인지를 가이드하는 데 도움을 주는 implicit assumption or bias. 조금 더 풀어서 설명하면, CNN같은 전통적인 컴퓨터 비전 모델은 spatial location에 대한 bias가 내장되어 있다. 이러한 Inductive bias (내장된 편향) 정보는 CNN이 이미지 분야에서 잘 동작하게 만드는 이유가 된다. 하지만 Vision Transformer에서는 Self-Attention을 사용하기에 이러한 특징이 없다.
spatial bias : 아래의 3가지 특징을 가지는 것.
- Parameter sharing: 이미지에 대해 학습한 특징이, 이미지에 다른 부분에서 재사용 가능.
- Translation Invariance: 어떤 특징이 이미지의 어느 위치에서 발견되더라도 동일하게 인식 가능. (Augmentation에 좋다)
- Local Connectivity): CNN의 핵심 원리는 전체 이미지가 아닌, local하게 filter를 가져다 대고 보는 것.
Self-supervised Learning: 자기 자신, 즉 입력 이미지를 통해 내부의 표현과 같은 특징을 배우도록 하는 Unsupervised Leanring 방법론 중 하나.
Masked Image Modeling (MIM)
Local Structure: 이미지 내부의 texture, pattern 등과 관련된 세부 정보를 의미한다.
Spatial sensitivity: 공간적 민감성 = 모델이 이미지의 특정 공간적 위치나, 패턴에 얼마나 민감하게 반응하는지
공간적으로 민감한 feature로는 texture, 내부적인 이미지의 pattern과 같은 특성이 있으며, 반대의 특징으로는 이미지의 전체적인 형태나 모양과 같은 특징이 있다.
Occlusion-invariant features: Masked Image modeling의 경우 Patch Token을 마스킹 후, Encoder-Decoder 구조를 통해 이를 복원하는데, MIM은 이러한 가림현상 (Occlusion)에도 불구하고, 해당 특징(Occlusion-invariant feature)를 잘 인식한다는 말.
Intra-image structure: 이미지 내부의 구조나 특징 설명을 잘 하는 Network. MIM은 local structure를 잘 보기에 위와 같은 intra-image structure라고도 불린다.
Contrastive Learning
Semantic alignment: 말 그대로 semantice=정보의 의미를 정렬 하는 것, 주로 같은 특징을 가지고 있는 representation을 비슷한 공간에 mapping하는 것이다. 다른 정보는 다른 공간에 mapping 하는 것.
Pretext tasks: self-supervised learning에서 주로 사용되는 용어로, 레이블이 없는 데이터로부터 레이블을 생성하여 모델을 학습시키기 위한 보조적인 작업을 의미합니다.
ex) Contrastive Learning에서 Positive samples와 Negative samples를 정의하는 것


Attention Distance: Attention distance = pixel distance x attention weight.
위의 그림에서 pixel distance는 단어 사이 떨어진 거리이며 attention weight은 QxkT이다. 따라서 Attention distance가 클수록 조금 더 모델이 Global하게, 멀게 본다는 것을 의미하며, 반대로 작은 수치는 근처에 있는걸 위주로 본다 = localized하게 본다라고 해석할 수 있다.
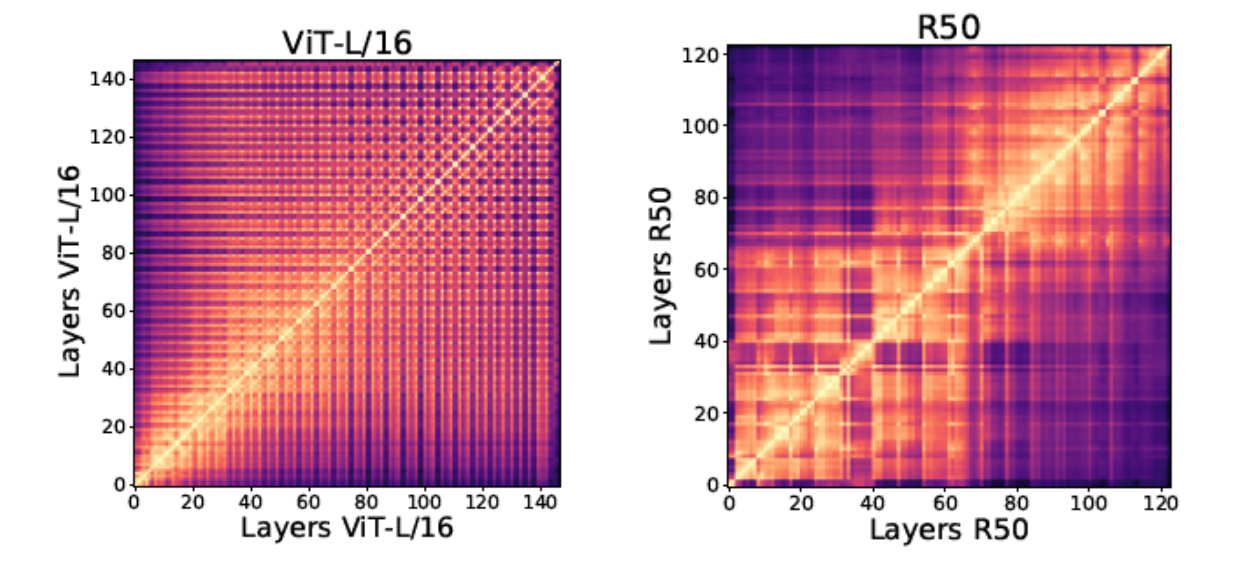
Centered Kernel Alignment (CKA): K는 X⋅X^T, L = Y⋅Y^T이다. HSIC는 Hilbert-Schmidt Independence Criterion이다. XY가 유사할수록 CKA는 더 증가하며, 낮을수록 낮아진다.

아래 그림은 CKA Value를 모든 layer끼리 비교하며 ViT와 Resnet50을 시각화한 그림이다.
Upper bound & Lower bound : 아래의 그림으로 대체. 어떤 집합이 있을 때, 그 집합에서 가장 큰 수와 같거나 큰 수가 존재할 때, Upper bound라고 함. 반대는 Lower bound.

NLP
static vector representation: Word embedding 시, 이 주어진 단어에 대해 항상 같은 vector 값을 반환하는 것을 의미한다.
GloVe, Word2Vec과 같은 논문에서 사용이 되었다.
'Deep Learning (Computer Vision)' 카테고리의 다른 글
| [DenseNet] 논문 톺아보기 - Densely Connected Convolutional Networks (0) | 2023.09.11 |
|---|---|
| Backpropagation 에서 전치의 발생. (0) | 2022.05.02 |
| MLP에서의 Forward pass, Layer shape 맞추기. (0) | 2022.04.28 |

