오늘은 DACON과 SW중심대학에서 함께 진행한 AI 경진대회 후기를 올려보려고 한다.
작년에는 18학번 동기들끼리 나가서 Private score로 5등?을 했었는데 이번 년도에는 연구실 후배들의 경험치를 올려주기에 좋은 경험이 되지 않을까 싶어서 같은 연구실 후배들을 대리고 나가게 되었다.

등수는 Public 9등 Private 8등, 발표까지 포함한 등수는 7등으로, SW중심대학협의회의장상을 수상했다. 발표에서 한 등수가 오른 것은 아무래도 창의적인 기법들을 많이 써서 그렇다고 생각한다. Solution은 아래에서 공개하도록 하겠다.
주어진 Task로는 Building Segmentation이였다. 작년에는 예선 본선을 나누어서 진행했는데, 이번에는 하나의 Task로만 진행이 되고 끝났다.
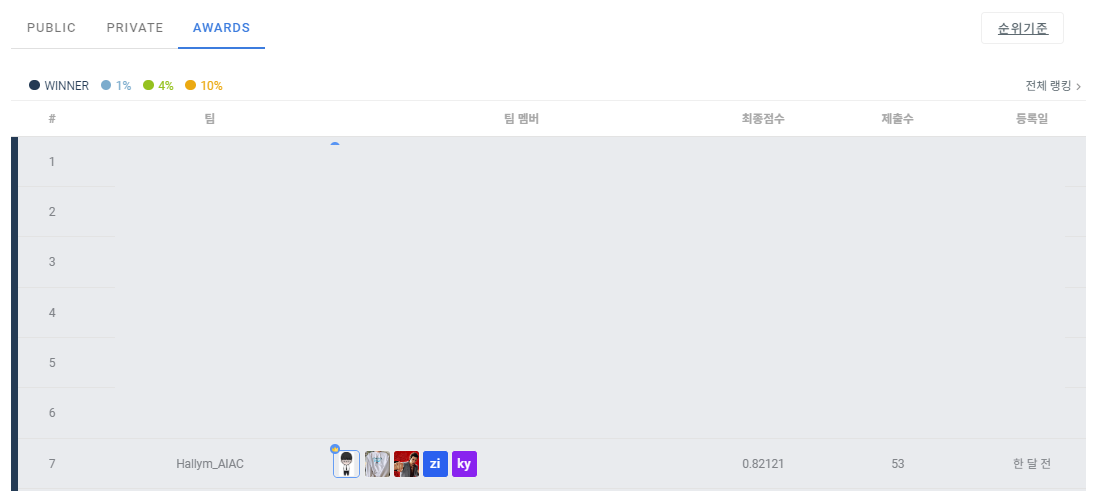
먼저 소감을 말하자면.. 뭐랄까.. 두번 다 상을 받아서 좋지만 둘 다 같은 SW중심대학협의회의장상이다. 발전을 하지 못한느낌..? 그래서 아쉽지만, 그래도 연구실 후배들을 대리고 이렇게 상을 받을 수 있다는 점은 행복한 것 같다.
가장 아쉬운 점은 6등을 기록한 우리 대학의 또 다른 연구실이 있는데, 그 연구실에게 졌다는 점이다. 대회가 끝나고 서로의 발표자료를 보며 Solution을 공유했는데, 우리가 신경쓰지 못한 부분이 너무 많았어서 아쉬웠다.
그 팀은 전통적인 대회 스킬을 많이 사용했고, 우리 팀은 새로운 방법론으로 이런 문제를 해결했다. 내가 우리 연구실 애들이 아니라 동기들이랑 나갔다면 더 좋은 성과를 얻지 않았을까 하는 생각도 들었지만, 후배들이 좋은 추억을 쌓은 것 같아서 만족스러웠다. 또 다른 생각으로는 간단한 부분을 신경쓰지 못한걸 자책했던 것 같다.
그래서 우리 팀이 해결하고자 했던 상황에 대한 Solution은 크게 5가지 정도가 있다. 먼저 우리팀이 정의한 문제는 아래와 같다.

0. Train Dataset의 해상도와 Test Dataset의 해상도가 다른 문제
1. 건물의 크기가 작은 경우, 모델이 인식을 못하는 상황 발생
2. 모델의 출력 값을 확인했을 때, 건물 내부가 비어 있는 출력 값이 발생
3. 건물의 경계선이 모호한 출력 발생
4. 16개의 이미지 분할로 인한 배경 정보 손실 문제
-> 위의 문제중 0번 문제는 필연적으로 해결을 해야한다고 생각을 하였고, 1~4를 주로 해결하는데 초점을 두었다.
0. Train Dataset의 해상도와 Test Dataset의 해상도가 다른 문제


- 위와 같이 왼쪽이미지에서 왼쪽이 Train 우측이 Test 데이터 셋, 이 크기가 다르다는 점 때문에 이미지 split, 분할을 했다.
- 따라서 나온 결과는 우측과 같다. 256 크기 16개와 약간의 겹치는 부분이 있게 하여 192 크기 36개로 잘랐다.
- 원본 Train 이미지가 7000장 -> 11.2만장 (256 사이즈) or 25.6만장(192사이즈)로 너무 많아져 학습이 오래 걸리기에, 아래와 같이 임의로 Train/Valid/Test 데이터 셋을 구축하였다.

- 학습을 한번 돌리는데 걸리는 시간이 오래걸리고, 데이콘의 제출 횟수가 3번으로 제한이 되었기에, 의료 데이터 학습시에 사용하는 자체적인 Train/Valid/Test 데이터 셋 구축 작업을 진행하였다. Train/Test를 실제 11만vs6만 과 유사한 2:1 비율로 자르고, Train/Valid를 7:3에 가깝게 44/22로 나누었다.
- 그리고 중간에 성능 점검을 위한 제출로는 8:2로 나눈 데이터를 사용했고, 마지막 앙상블에 사용하기 위한 데이터는 100% 모두 활용을 하였다.
1. 건물의 크기가 작은 경우, 모델이 인식을 못하는 문제

- 1번 문제를 해결하기 위해 Self-supervised Learning의 DINO라는 방법론에서 영감을 얻어서 이러한 작업을 진행을 했다.
- Segmentation pytorch 라이브러리의 특성상, 어떤 입력의 사이즈가 들어가도 그 사이즈에 맞게 복원을 해줄 수 있다. 이 부분은 입력 이미지 1024가 들어가던, 256이 들어가던 똑같이 복원을 해줬던 기억이 있었기에, 256이미지에서 DINO처럼 작게 잘라서 넣을 수 있지 않을까 생각했다.
- 물론 DINO에서는 96x96으로 자르고 224x224로 reshape도 해주고, Teacher-student 모델로 pre-training model을 만드는 것이 목표인데, 우리는 자원의 한계도 있고, pre-train을 만드는 방법론은 다른 방법론을 사용했기에, 하나에 모델에서 학습을 한번에 수행 가능한 end-to-end training model을 사용하였다.
2. 모델의 출력 값을 확인했을 때, 건물 내부가 비어 있는 출력 값이 발생

- 2번 문제는 그냥 가볍게 모폴로지 닫힘 연산을 사용했다.
3. 건물의 경계선이 모호한 출력 발생


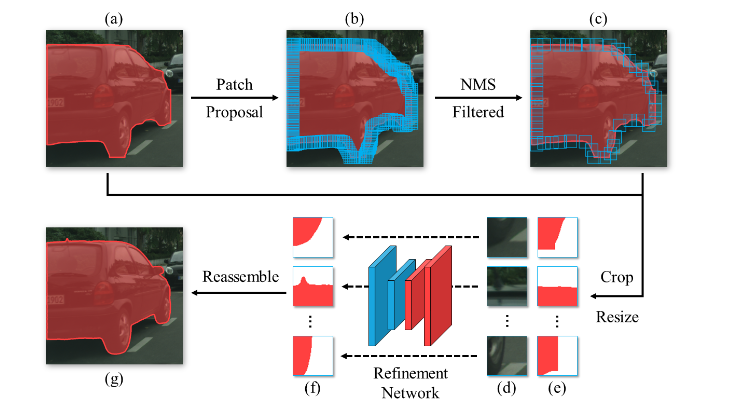
- 경계선이 모호한 문제, 즉 왼쪽 사진에서 경계선들이 뚜렷하지가 않은데, Cityscape 데이터 셋에서 1위를 차지한 방법론인 BPR(Boundary Patch Network)를 사용해서 우리 모델에 적용을했다.
- MMCV를 설치했다면 손쉽게 긁어와서 적용했을텐데, 대회 기간 내내 MMCV를 설치하지 못해서 그냥 논문 읽고 내가 구현해서 시각화까지 했다. (후배들을 시켰지만.. ㅠㅠ 너무 어려웠던 것 같다..)
- 근데.. 진짜 제일 우측 이미지가 논문에서 사용한 Figure, 왼쪽이 내가 그린 그림인데, 이거 진짜 잘 만들지 않았나 싶다


- 방법론을 구체적으로 설명하면 다음과 같다.
- 결과는 위에 빨간색 건물이 있는 (e) 부분과 (d)를 보면 된다. 확대해서 보면 성능이 진짜 좋아보인다.
- 하지만 성능은 기대한 만큼에 비해 그렇게 많이 오르지는 않았다.
4. 16개의 이미지 분할로 인한 배경 정보 손실 문제
- 16개의 이미지로 자르게 되면, 아래 같은 경우는, 모래, 도로, 건물이 3개가 모두 흰색이라 파악하기가 어렵다. 따라서 1024x1024에서 배경이미지에 대한 정보를 가지고 있는 모델이라면, 건물 예측도 쉽게하지 않을까 생각하고, 적용해보았다.
- 하지만 이 Masked Image Modeling 방식은 Transformer 계열에서만 가능한데, 이번 Task에서 Transformer가 안좋았기에, 그냥 1024x1024에 대해서 segmentation을 진행한 모델을 pre-train모델로 사용하는 방법론을 사용했다.
- 근데 이 방식도 시간소모적이라 일부 모델에만 적용을 했다

5. 아쉬운 점.



- 아 그리고 이상한 라벨링이 너무 많았다. 이 부분 때문에 모든 팀이 전체적으로 성능이 낮았다고 생각한다.
메사추세스, WHU?, 등 과 같은 데이터 셋의 성능을 논문에서 찾아봤을 때 90퍼가 넘었었다. 아마 라벨링이 더 좋았다면 1위를 기록한 팀의 성능이 어디까지 올라갔을지 궁금했던 Task이기도 했다.
++ 이 이상한 라벨링을 오히려 모델에 반영해보기도 했지만, 그러면 모델이 아에 망가져버렸다.
6. 최종.
- 우리 팀은 아래와 같은 모델을 가지고 앙상블을 진행했고, Private 상에서는 8등을 기록했다. Hard voting을 사용했는데,soft voting도 사용하고, 진작에 192x192를 사용했다면, 더 좋은 결과가 나오지 않았을까라고 생각한다.
- 특히 우리보다 위에 있던 팀에서는 soft voting이 hard보다 1,2퍼가 좋다고 했으니.. 더 아쉬움이 남는다고 생각한다.
- Optimizer는 RAdam, Scheduler는 ConsineAnnelingLR - T_max = 10이다.
- Loss function은 BCE 80%, Focal 20%를 섞어서 사용했다.

- 총평을 하자면, 장비 덕이 아무래도 있었다고 생각한다. 순위 권에 들지 못한 팀들은 GPU 성능이 낮아서 그렇지 않을까 라고도 생각되는 Task였다. 간단하게 건물을 골라내는 방법론이기에, Encoder가 커지면 커질수록 성능이 높아졌다. 따라서 더 큰 모델을 사용하고 싶었지만, 이미 충분히 학습 시간이 오래 걸린다고 생각해서 더 늘리지 않았다.
- 그런 면에서는 efficientNet이 좋지만, 같은 파라미터에서 se_resnext 모델이 더 좋았기에 se_resnext를 사용했다.
- squeeze and exciation 이 방법론이 channel attention으로 알고있는데, 그냥 resnet보다 좋았던 것으로 기억하고 있어서 사용했다. se_resnext101, batch-size 128, 50 epoch을 돌렸을 때, 하루 조금 덜 걸린 것 같다.
- 아무튼 작년 OCR은 너무 어려웠는데, 이번 Task는 재미있게 수행했었다. 하지만 Task가 여전히 크다는 생각이 있다.
- 그리고 작년엔 발표 비중이 커서, 창의적인 방법론을 많이 썼는데 이번에는 별 영향이 없었던 것 같다. 작년과 같은 발표 비중이였다면, 더 올라가지 않았을까 싶지만, 원래 이런 대회의 본질은 창의적인 방법이 아닌, 성능이 우선이니까. 재미있었던 경험이었다.
'대회 참여 후기' 카테고리의 다른 글
| 2023 구글 머신러닝 부트캠프 2023 4기 후기 (0) | 2023.12.11 |
|---|
