논문: When Does Label Smoothing Help?
저자: Rafael Müller∗ , Simon Kornblith, Geoffrey Hinton
소속: Google Brain (Toronto)
학회: 2019 NIPS
인용 수: 1423 (2023.05.23기준)
Baseline
- 기존의 One-hot 방식의 hard label을 사용하는 것 보다 soft label을 사용하는 것이 더 성능이 좋았다.
- 왼쪽이 Soft-Label 방식으로, 레이블 마다 중요도를 바탕으로 label을 다시 만드는 방법이 있으며, Label-smoothing은 우측 그림과 같이 정답에서 일정한 부분을 빼서 나머지에 나눠주는 방식이다.
- hypterparameter a만큼 정답 label에서 빼준 후, a를 클래수 수 만큼 나눈다음 더해주는 방식이다.


Abstract
- Label smoothing은 model의 over-confidence를 막아주는 역할을 하여 SOTA모델에 자주 사용되었다.
- 자주 사용되는 것과 다르게, 왜 어떤 효과를 가지고 있는지에 대한 연구는 이루어지지 않았다. 그래서 밝히고자 한다.
- Knowledge Distillation에서 Teacher model에 Label smoothing을 사용할 경우 성능이 떨어지는 현상이 발생했다.
- 그 이유를 밝히기 위해 Penultimate layer (마지막에서 2번째 layer)를 분석해보았다.
- 이를 통해 Label smoothing이 학습 데이터에서 같은 클래스를 가까운 Cluster로 묶도록 하는 것을 볼 수 있다.
Purpose
- 이 논문의 목표는 다음과 같다
1. penultimate layer를 분석하여 label smoothing을 사용 방식과 그렇지 않은 방식을 visualization을 통해 비교한다
2. label smoothing은 모델을 보정하여, 모델의 예측이 신뢰도가 예측 정확도와 어느정도 일치하게 조정됨을 보여준다.
3. Knowledge Distillation에서의 성능이 좋지 않음을 보여준다.
1. Introduction.
Loss function의 역사
1. backpropagation에서의 quadratic loss function 사용
2. Classification performance & faster convergence로 인한 Cross Entropy사용
3. 추가적인 Loss funciton 사용. -> 그 중 하나가 Label smoothing.
+ 조금 더 자세하게 알고싶다면 CS229에서 왜 quadratic loss function을 사용했는지에 대한 요약이 있다.
Stanford CS229 강의 요약 Machine Learning - Locally Weighted & Logistic Regression | Lecture 3-1 (Autumn 2018)
Week 3 Topic & Week 2 Recap 1. Linear Regression (Recap) 2. Locally weighted Regression 3. Probabilistic interpretation + Why we use the qudratic loss function? 4. logistic regression (3-2 다음 포스팅에서) 5. Newton's method (in losgistic regression
187cm.tistory.com
Label smoothing
- 최초의 soft-labeling의 사용은 Inception architecture에서 hard target 대신 weight를 mix한 것이다.
- 그 외에도 classification, Speech Recognition, machine translation에서도 다양하게 사용하였다.
- Machine translation에서의 Perplexity score를 제외하고는 without LS보단 with LS의 성능이 더 좋다.

Preliminaries
- pk는 penultimate layer에서의 k번째 클래스의 likelihood. (likelihood: probability of the data)
- x는 1과 concatenated 되어 bias를 더 잘 설명할 수 있다. (1이 additional bias term)
- wk는 모델의 weight or bias이다.
- H(y,p)는 기존의 Cross Entropy이며, y-LS는 label-smoothing의 Loss function이다.



2. Penultimate layer representations
- 우리가 hard label 방식으로 학습했을 때, 정답에 대해 100%로 예측하게 만들어 logit이 커지게 된다.
- 반면 soft label 방식으로 학습했을 때, a/K만큼 정답이 아닌 클래스에도 label을 주어 logit이 커지기 위해서는 다른 class도 신경쓰게 된다.
- 아래 수식을 볼 때, xT⋅x는 softmax에 의해 없어지고, wT⋅wk는 전체적으로 유사한 값을 가지는 상수이다.
- 따라서 logit xT⋅wk가 클수록 Euclidean distance가 작아져 xT와 wk가 유사하단 뜻이다. 이는 Label smoothing에서 xT와 wk가 유사해지기 위해 incorrect class까지 a/K거리만큼 만들기 위해 노력한다는 뜻이 된다.

- 따라서 위의 preliminaries의 수식을 바탕으로 시각화를 한다. 3개의 클래스를 고른 후, 이 3개 클래스의 평면에서의 Orthonormal basis를 찾아서 시각화를 합니다

- 왼쪽 2개 Column은 Without LS, 오른쪽 2개 column은 with LS이다.
- 각각의 row는 CIFAR10, CIFAR100, ImageNet (각각 다른 특징의 class), ImageNet(2개는 비슷, 1개는 다른 class)
- 2번째 3번째 row 그림을 보면 a 만큼의 거리를 유지하며 각각 학습하는 것을 볼 수 있다.
- 그리고 4번째 그림이 핵심 그림이다. 우선 4번째 row의 각 Class는 (Toy poodle, Miniature poodle, tench)이다. 2개의 Class가 매우 유사한 것을 알 수가 있는데, 이는 그림에서도 똑같이 나오게 된다.
- Label smoothing을 사용하지 않으면 원형으로 비슷하게 포개지지만, 사용할 경우 호 모양을 그리며 a/K만큼의 거리를 유지하는 것을 볼 수 있다. (비슷한 클래스 끼리도 a/K만큼 거리를 유지하려고 호 모양이 되며, 다른 클래스에 대해선 완전히 a/K 만큼 거리를 둔 모습을 볼 수 있다.)

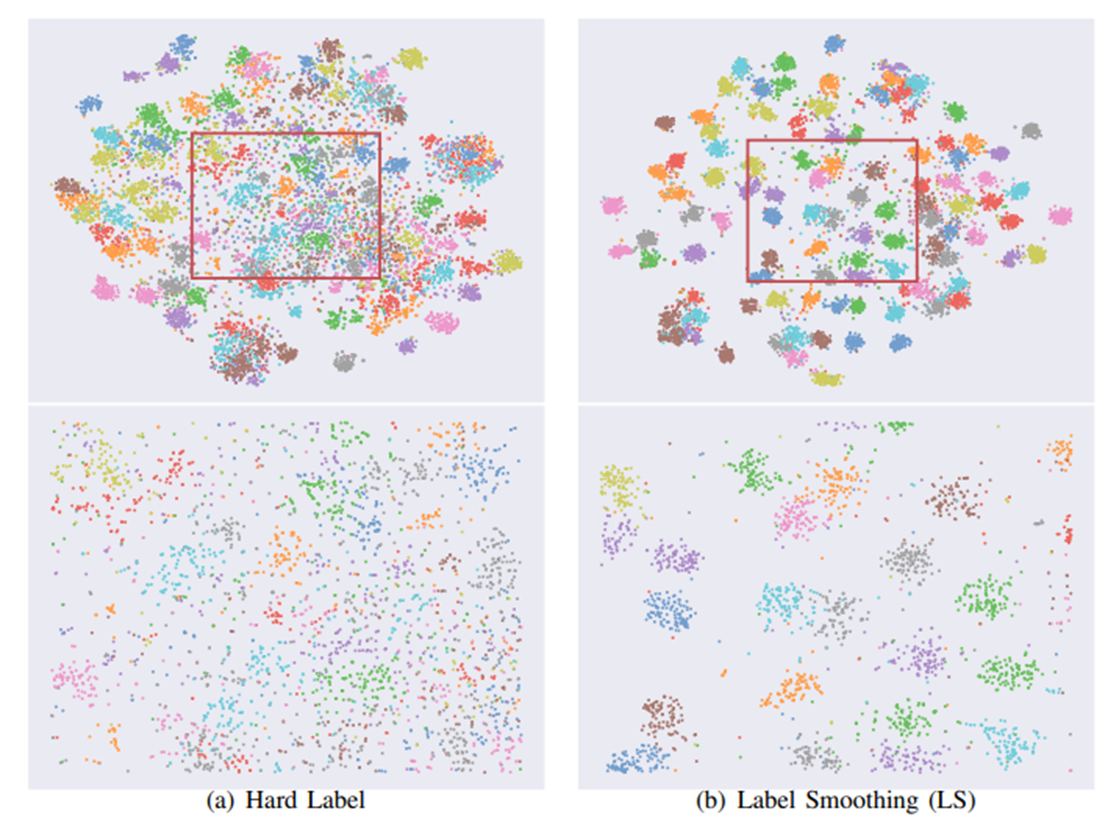
- 우측은 Delving Deep into the Label smoothing 논문에서 가져온 T-SNE로 시각화 한 label smoothing 여부의 그림이다.
3. Implicit model calibration(Realiability diagram)
- 파란 줄선: Hard label, 초록 줄선: Label smoothing, + 마크 파란선: Temperature scaling.
- 우리는 모델의 confidence만큼 Accuracy가 나오는 것을 원하기 때문에 이런 그림을 그리게 되었다. 중앙의 검은 점선이 Confidence와 Accuracy가 동일한 최적의 Realiability diagram이다.
+ Confidence는 모델이 어떤 클래스를 어떤 확률로 예측했는지이다. 3번이 정답이라면, 3번을 100%로 예측하기 원하는 것을 Hard label에서의 최적의 confidence, 3번을 90%확률, 나머지 클래스를 10% 확률로 예측하길 원하는것을 Soft label에서의 최적의 confidence이다.
- 결론을 보면 Hard label과 다르게, Label smoothing을 한 것이 모델의 Confidence와 Accuracy가 비슷하게 나온다.

- 추가적으로 위에서 사용한 Temperature scaling에 대해서 T의 값에 따른 Softmax의 변환 결과.
- T가 커지면 커질수록 smoothing효과를, T가 커지면 커질수록 Sharpening효과를 가진다.


4. Knowledge distillation
- Knowledge Distillation에서 Teacher Model에 label smoothing쓰면 안좋다.
